
Internet usage patterns and delivery of software applications are undergoing major paradigm shifts. Decentralization is the primary pattern – transitioning away from fixed network entry points, concentrated clusters of compute and single data stores. These changes are being driven by the rapid evolution of work habits, software architectures, connected devices and data generation. After years of Internet resource convergence, we are witnessing a shift towards the broader distribution of compute, data and network connectivity.
Software applications are pushing processing workloads and state outwards towards the end user. This transition began to lower response times for impatient humans, but will become a necessity to coordinate fleets of connected devices. With work from anywhere, network onramps cannot all be routed through central VPN entry points protected by firewalls. Distributed networks backed by dynamic routing will increasingly facilitate point-to-point connections between enterprise users, their productivity apps, corporate data centers and local offices. Massive troughs of raw IoT data have to be summarized near the point of creation before being shipped to permanent stores.
These changes are being driven by exogenous factors, reflecting the same bias towards decentralization. Workers are less likely to concentrate in large office campuses where their network connectivity can be protected by closets of security hardware. The proliferation of connected devices and high-bandwidth local wireless networks are creating new opportunities to streamline industrial processes and enable machine-to-machine coordination. Privacy concerns are prompting government regulations to keep user data within geographic boundaries. The convenience and efficiency of digital engagement are forcing enterprises to move consumer touchpoints onto virtual channels.
Overlaying these trends is an increasing need for security. While hackers have existed for years, the decentralization of defenses and migration away from physical engagement are creating new opportunities to exploit vulnerabilities as technology tries to catch up with consumer habits. Information sharing, corporate-like organization and untraceable payment systems are propelling the practice of hacking into a thriving business function. This has thrust digital security from the back of the enterprise to the front office, layering over every corporate activity. Digital transformation extends the same risks to the enterprise’s customers.
These forces are creating significant opportunities for nimble software, network and security providers. Entrenched technology companies are responding, but existing business incentives and fixed system architectures are creating inertia. Foundations in centralized compute infrastructure, big data stores and network hardware sales are difficult to evolve. Newer companies grounded in a distributed mindset are better positioned architecturally, commercially and culturally to address the new landscape. Focused independent players will carve out large portions of the growing market for distributed Internet services.
In this post, I explore these trends in network connectivity, application delivery and data distribution, and then link them back to the independent, forward-thinking public companies that are capitalizing on them. While many companies are lining up against these trends, I will try to limit my focus on the implications for a few high growth software and network infrastructure companies tracked on this blog. Specifically, these include Cloudflare, Zscaler and Fastly. I will also use this narrative to weave in updates on each company’s recent quarterly results, product developments and strategic moves.
What is Changing?
The fabric of the Internet is being impacted by how we work, interact with the world and manage our lives. Software delivery infrastructure and network architectures are evolving, to both meet these new demands from society and to increase developer productivity. Nefarious actors are on the move as well, organizing in new ways to exploit security lapses.
I will summarize the most significant change drivers below. As investors, these need to be appreciated and monitored. Their momentum has implications for the companies that provide network connectivity, software infrastructure and data storage. As with any rapid industry advance, providers face both new opportunities and risks. Some forward-thinking companies will flourish and slow responders will fade.
Work from Anywhere. Every business must accommodate the ability for the majority of their employees to work remotely. Whether they bring all employees back to the office or keep them all remote is inconsequential. Going forward, CIOs have to plan for the necessary network capacity and configuration to enable all employees to be remote. This is because COVID-19 taught CIOs that another exogenous event (like another pandemic) could force periods of work from home in the future. That possibility has forever changed the planning process.
The outcome is that a plan for 100% remote work, even some of the time, means that prior network architecture designs with controlled entry points (VPN), physical firewalls and one-time authentication will not be sufficiently scalable or secure. Before COVID, with remote work being the exception, a lower expectation for offsite service quality was accepted. Enterprise IT could get away with marginally functional performance through shared VPN and other network chokepoints. The argument was that employees could always drive to the office for a better connection. That is obviously no longer acceptable.
This change pushes CIO’s away from a network architecture designed around limited entry points (hub and spoke, castle and moat) to fully point-to-point connectivity. This allows an employee to connect directly to any enterprise resource from any point on the globe. That requirement favors a distributed network on on-ramps and off-ramps, with entry locations near every city and dynamically routable network paths to every other point.
Additionally, network connections need to be short-lived – they are created and authenticated for the duration of every request. This differs from the prior castle and moat approach of authenticating at a single entry point and then allowing extended access to all resources on the local network. An analogy would be checking a visitor’s ticket once at the entry gate to the amusement park for the day, versus verifying their ticket before every ride. The latter approach is called Zero Trust and is becoming the norm, as a requirement of a fully distributed workforce.
Connected Smart Devices (or Machine-to-Machine). I won’t just call this IoT, although that is an accurate label. I make a distinction because the simplest form of IoT is simple one-directional sensors that collect data and ship it back to a central store. Examples are temperature gauges or moisture sensors for agriculture, or location beacons for packages. While this use case is interesting from a data processing point of view, these devices don’t generate much demand for decision making, cross-device communication or coordination. They just write to a log of values and then periodically ship that data somewhere else for processing.
I think the more interesting opportunity involves any device with sensors, some processing capability and an external interface (display, robotic arms, motors). These IoT devices both monitor and take action. These devices will have logic and something they control in the physical world (and in the case of software agents, the virtual world too). These types of devices are often more effective when coordinated with other devices in a local area.
These devices can connect to a network through a high-speed wireless spectrum (like 5G). Next generation wireless networks offer more bandwidth and broader range, making it feasible to reach all devices within a large building or square kilometer. Network equipment providers are rapidly rolling out systems that allow enterprises to set up their own private 5G networks.
The emergence of new high-bandwidth wireless networks, like 5G, coupled with IoT and automation are driving a significant upgrade of traditional manufacturing and industrial processes. This movement is being dubbed Industry 4.0, which involves integration of industrial systems for increased automation, improved communication and self-monitoring. Smart machines can even analyze and diagnose issues without the need for human intervention.
Beyond our factories, we can look for examples of these types of devices in our homes, commercial buildings and cities. Having temperature sensors throughout a building or a city would generate a lot of data, but that only goes one-way. However, if all the traffic lights in a city were coordinated based on traffic load, that generates an order of magnitude higher demand for compute and data resources.
Another example could be found in our homes, where sensors, control devices and appliances are all connected and coordinated on a local network. Smart homes can be optimized for efficiency and convenience. They also offer new revenue models, as discussed by SAP below.
The reality is that as the cost of sensors comes down, we are designing smarter products and assets that have embedded intelligence and IIoT data points. This means that everything is “smart” and we are only limited by our imagination for use cases.
Let’s take an item like a washing machine. The manufacturer may decide to move to an as-a-service model where they don’t sell the washing machine but offer it as a service and generates a monthly bill based on how many loads of washing you do in a given month.
But to do this they have to be able to track several things. Firstly, you must track how many times the washing machine has been used, so that you can bill the customer. But you also want to make sure that the washing machine is working at an optimal level and isn’t about to break down in mid-wash. This requires a whole new set of sensors on key components of the machine that can be used to alert the manufacturer that the machine needs maintenance or in the worst case, needs to be replaced. If it breaks down everybody loses.
You may also position your product as the “sustainable washing machine” that can provide the customer information on their mobile device about how much electricity it is using, what its carbon footprint is, how much water it is using per wash and much more. Again, this would mean leveraging IIoT sensors to capture and share this information.
Richard Howells, VP, Solution Management for Digital Supply Chain at SAP, Protocol Newsletter
This difference between sensor-based IoT and actual coordinated clusters of smart devices has important implications for the future demand for distributed compute and data storage solutions, often referred to as edge compute. While the potential for IoT is very exciting, I would argue that one-way sensors don’t do much to push forward the need for edge compute resources. Systems of linked smart devices that coordinate to achieve a desired outcome definitely do.
Current use cases for edge compute revolve around speeding up application delivery. By moving compute and data closer to the end user in a distributed fashion across the globe, the user’s perception of application responsiveness will improve. This is certainly a worthwhile cause, as digital experiences become richer and consumer expectations for real-time response increase. The impact on edge compute demand will be linear, though, increasing with the number of users and apps.
The non-linear growth will happen when true machine-to-machine communication takes off, moving beyond single-purpose sensors to connected smart devices. To serve those purposes, the need for distributed compute resources and data storage will explode. A lot of Industry 4.0 workloads might be addressed by locating a mini-data center on the factory floor. That could provide a large portion of the local compute and data storage needed. However, I think an equally large amount of data services will be needed to distribute information and coordinate activity across these factories, and connect them to distribution hubs, transportation services and supply chains.
Another way to consider the potential for machine-to-machine workloads is to think about the current set of Internet “users”. These are primarily people. While mobile phones and other smart devices increased the time a human could engage with the Internet, user growth was still bound by the number of humans on the planet (let’s say increasing 1-2% a year). While many new digital channels are disrupting traditional business models, like e-commerce, video streaming, health care, etc., the ultimate growth of those businesses will be bound by the number of humans available to consume their services.

With autonomous machines, however, the growth potential is non-linear and is bound by device manufacturing. All of these devices will need endpoint protection and secure network connectivity. Monitoring and coordinating them will require new distributed application workloads, with global reach and geographic proximity. Autonomous software-driven control agents will also need to communicate with each other. This growth of machine-to-machine coordination will accelerate the demand for decentralized compute and data storage solutions. This is the potential for investors to harness.
As a simple example, if a temperature sensor recorded the temperature every minute, but the temperature stayed the same for an hour, those 60 entries would not be very useful. Yet, the network transmission cost to ship 60 entries, versus just one summary entry, would be much higher. This reality creates a benefit for regional or local processing at some point between the device and the central processing store. Compute could be located in regional clusters that collects the raw log data and processes it for patterns. The summary data would then be sent to the central repository for further examination.
Data Tsunami. As more data is created by more connected devices across the globe, data pre-processing near the network entry point becomes a requirement. This is because large volumes of log data can be expensive to ship all the way back to a central processing cluster in raw form. Orchestrated systems will be sensitive to latency and benefit from local or regional processing to enable faster decisions and greater resiliency.
This localized data processing capability can be facilitated by edge compute resources. These might execute basic logic to compute averages and deviations, or be enhanced by ML/AI techniques. Edge compute providers would need to support a development environment, some local data storage for caching and a fast runtime. These runtimes would also need to be isolated from other tenants and secure.
Digital Transformation. While it can have a number of implications, digital transformation represents the enterprise process of creating new sales, service and marketing experiences on digital channels to supplement (or eventual replace) physical interactions. Each new digital experience creates incremental demand for software infrastructure. While this migration from offline to online was occurring pre-COVID, the pandemic and social distancing accelerated the process.
I expect this trend to continue. After being forced to utilize digital channels during the pandemic, most consumers have realized that it is more efficient to perform their daily tasks online. Going forward, they will expect to have digital channels available from every company selling them a good or providing a service. If enterprises successfully avoided digital adoption previously, COVID will push them over the edge. Additionally, as one company in an industry creates a better digital experience, their competitors are expected to keep up. This drives an ongoing cycle of one-upmanship.
A good example exists in the restaurant industry. Chipotle now anticipates up to half of all sales to occur online. Even after COVID, they expect this to persist as customers value the time savings and convenience of just picking up their food in the store versus standing in line to order it. They even recently started rolling out digital-only kitchens in heavily populated areas, which completely removes the human interaction. Other chains are building online experiences as well, like Panara, Starbucks, McDonalds, Chick-fil-A, Chili’s, etc.
Digital transformation is also being applied towards making employees more efficient. A good example is new Twilio’s Frontline product and its adoption by Nike. Frontline provides a mobile application for employees that connects them directly to customers via SMS, WhatsApp or voice. While the app is installed on the employee’s mobile device, the login, messaging and phone number are tied to their company’s identity. This allows the workers to have the convenience of their own mobile device, without having to rely on their personal phone number. This release was highlighted during Twilio’s Signal user event last year, as part of a keynote with Nike’s CEO. For Nike, this allows the company to service customers outside of a store environment.
Nike just announced impressive Q4 results. Overall revenue grew by 21% over Q4 2019 (better comparison than year/year due to COVID). Their digital channel, Nike Digital, grew 147% over the same period. They intend to continue this investment in the digital business going forward.

“FY21 was a pivotal year for Nike as we brought our Consumer Direct Acceleration strategy to life across the marketplace,” John Donahoe, President & CEO of Nike said. Now approaching 40 percent, Nike aims for direct sales to represent 60 percent of its business by 2025, with the share of digital direct sales expected to double from 21 to around 40 percent. Earlier this year, Nike’s largest competitor Adidas had announced a similar initiative called “Own the Game”, under which the German sportswear giant plans to reach 50 percent direct-to-consumer sales by 2025. This will include investments of more than €1B in digital transformation.
This direct to consumer trend from major manufacturers obviously has huge implications for digital channel growth. That is because they are cutting out distribution through a physical retail intermediary. By moving their distribution to direct consumer sales, they dramatically increase their reliance on software delivery infrastructure to facilitate the consumer’s ability to browse products, place orders, receive delivery and get customer service.
The implications for compute, storage and networking providers are significant. Moving more consumer experiences to digital channels will require additional software infrastructure, services and delivery consumption. The desire for performance will push some of this compute and data out to the edge. On the employee side, more productivity applications will increase requirements for secure network connectivity. When employees utilize a productivity application on their mobile device, tablet or laptop, they might not be on the corporate network. This means a secure, point-to-point network connection would be established (ideally) between their device and the enterprise application (which may be SaaS, on the cloud or located in a corporate data center). If the employee’s connection were routed through a VPN, it would create more load on that network chokepoint and result in a degraded user experience.
Decoupling Applications. Even before edge computing emerged, developers were breaking up large applications into smaller, independent components. The original Internet applications were monoliths – all code for the application was part of a single codebase and distribution. It executed in one runtime, usually a web server in a data center. Monoliths generally connected to a single database to read and write data for the application.
As applications and engineering teams grew to “web scale”, this approach to software application architecture became more difficult to maintain. With all code shared in a single codebase, isolating changes across a team of tens or hundreds of engineers wasn’t feasible. Test cycles were elongated as QA teams ran through hundreds of regressions tests. The DevOps team couldn’t optimize the production server hardware to match the specific workload demands of the application.
These constraints of a large monolithic codebase sparked the advent of micro-services. A micro-services architecture involves breaking the monolith into functional parts, each with its own smaller, self-contained codebase, hosting environment and release cycle. In a typical Internet application, like an e-commerce app, functionality like user profile management, product search, check-out and communications can all be separate micro-services. These communicate with each other through open API interfaces, often over HTTP.
Micro-services address many of the problems with monolithic applications. The codebase for each service is isolated, reducing the potential for conflicts between developers as they work through changes required to deliver the features for a particular dev cycle. Micro-services also allow the hosting environment to be tailored to the unique runtime characteristics for that part of the application. The team can choose a different programming language, supporting framework, application server and server hardware footprint to best meet the requirements for their micro-service. Some teams select high performance languages with heavy compute and memory runtimes to address a workload like user authentication or search. Other services with heavier I/O dependencies could utilize a language that favored callbacks and developer productivity.
Further up the stack, Docker and Kubernetes allow DevOps personal to create a portable package of their runtime environment. All of the components needed by their application, app server, database, cache, queues, etc., can be codified and then recreated on another hosting environment. This represented a major improvement to the decoupling and reproducibility of software runtimes. It also helped plant the seeds for further decentralization. No longer were production runtime environments constrained to a physical data center that SysAdmins needed to set up and tune by hand.
Finally, the emergence of content delivery networks (CDNs) gave developers the ability to cache components of a web experience that were slow to transmit over the network. These might include large files like images, scripts and even some application data. These caches were located in PoPs that CDN providers distributed across the globe. The benefit of using a CDN was primarily seen in the performance of the web application. Load times came down significantly.
However, CDNs provided developers with a side benefit of decentralization of application architecture. It provided a pattern for distributing application content across the Internet. It also forced models for cache management. These patterns for CDN use apply to distributed data caching and requirements for consistency.
This is to say that developers are already familiar with the idea of distributing their software application components and data across the network. They can rationalize keeping some parts of the application at a centralized core, where scale keeps costs down. Other parts of the application and data can be pushed outwards to users, running in parallel on a distributed network of regional PoPs.
Serverless. Continuing the progression of application decoupling, DevOps teams realized that maintaining large tiers of servers waiting on user requests wasn’t an efficient use of resources. Some parts of the application were only triggered by a separate user action and the output wasn’t something the user needed to monitor. These tended to be asynchronous jobs like sending a confirmation email or writing to an analytics data store.
Because these functions are asynchronous, the serverless runtime could be spun up slowly (referred to as code start time). Some more progressive CDN companies realized that they could adopt a serverless model to allow developers to run code on their geographically distributed network of PoPs. They created optimized runtimes that could start executing code in a few milliseconds or less. This change enabled serverless runtimes to be used for synchronous processing, responding in near real-time to every user request.
This change turned centralized application processing on its head. By allowing any part of a web application to run in a serverless environment, developers could consider moving many functions closer to application users. These new distributed serverless environments could run the same copy of code in parallel across a global network of PoPs. A user connecting from Germany would be served from a PoP in Europe, while a U.S. user would hit the PoP closest to their city. In both cases, the code run would be the same.
This model is easiest to apply to parts of the application that are stateless. For these cases, the serverless function stores no data or utilizes a local cache that persists for the duration of the user’s session. Stateless functions include things like application routing decisions or an A/B test. Short-lived cached data might represent a shopping cart for an e-commerce application or an authentication token after login. The benefit was that these functions could provide faster response times to the user, resulting in a much shorter application load.
By design, these serverless providers also supported a multi-tenant deployment. CDN providers with multi-tenant distributed compute could execute code for many customers in parallel within each PoP. Because the runtimes for serverless code are isolated from other processes, they could enforce security measures to ensure no data leakage or snooping.
These capabilities supported further breaking up the monolithic application, allowing some functions to be relocated to runtime environments closer to the end user (the edge of the network). Because developers were already versed in centralized serverless environments provided by cloud vendors, this new model of distributed serverless delivery was a logical extension. In addition, they had already conceptualized the use of a global network of PoPs through their experience with CDNs.
Finally, the software frameworks that developers use to create their applications are abstracting away some of the distribution complexity, particularly around state management and caching. Popular frameworks are being updated to account for new delivery paradigms, like edge compute. As an example, the React JavaScript framework is popular with developers for building modern web applications. It facilitates the creation of the client-side application and data management with the back-end. Recently, a new open source project, Flareact, was released for Cloudflare’s edge compute platform. The project owner updated React with new components specifically to support edge deployments. As edge compute becomes more popular, we can expect to see more improvements to common software development frameworks that make distributed application development easier for all levels of engineer.
Data Localization. Regulations are increasing from countries worldwide for data sovereignty. Several entities, like the EU, China, Brazil and India, already have controls in place, or are considering them. As privacy concerns proliferate, we can expect this kind of oversight to increase.
These data sovereignty requirements generally dictate that the data for a country’s citizens be processed and stored locally within that country’s borders. This requirement poses a problem for centralized application hosting models. They would need to have a presence in each country and a mechanism for keeping the data local.
However, if the application hosting model is distributed across PoPs in every country, the provider could enforce logic that services the user’s request within that country’s borders and maintains only a local copy of their private data. This model is easily supported by the CDN providers, who started with a distributed network of multi-tenant PoPs (mini data centers), connected by a software-defined network. As examples, Cloudflare and Akamai have PoPs in over 100 countries.
Identity and Privacy. Speaking of privacy, the Internet has a huge problem with identity and duplication of sensitive user data. Every enterprise application that a consumer interacts with wants their own copy of the user’s identity and metadata. This can include personally identifiable information, like name, phone number, address, email, etc. If the enterprise experiences a security breach, the consumer’s information is compromised. The likelihood of compromise for any consumer is high because their data is copied in so many places.
Additionally, some enterprises will create new data about a consumer, which they have no control over. If there is a mistake (like a credit history), the consumer may not know about it. The consumer may only want to share the data that is necessary for the application to function. In some cases, like on social networks, they prefer pseudonyms to protect their privacy. One user’s identity may be loosely associated with multiple personas with their real-world details kept private.
The current system of user identity would be much improved if the consumer had a method of maintaining their own encrypted store of personal data which could be shared with applications as appropriate for each use. The consumer could review their personal data to ensure it is accurate and up-to-date. With the right protocols, applications wouldn’t need to permanently store a user’s personal data. Rather, they might maintain an anonymized reference ID to that user, and then load the data from the user’s private store during an actual engagement. This is already how some payment systems operate.
Security Overlays It All
All of these trends towards decentralization make securing the underlying systems more challenging. Digital transformation, work from anywhere, IoT, big data, micro-services, all create new attack surfaces. This opportunity is being exploited by what seems to be increasingly well-organized hacker syndicates. Cyber attacks are more prevalent with high visibility impact, as we have seen recently with news reports on SolarWinds, Colonial Pipeline and JBS.
The number of breaches is expanding proportionally to the increase in attack surfaces. To quantify this, Zscaler published an “Exposed” report in June, which provided details on the significant increase in vulnerable enterprise systems over the prior year. This was driven by enterprise response to COVID-19, where companies offered more remote work options for employees, relocated physical experiences on digital channels for their customers and migrated application workloads to the cloud.
Some details from the report were:
- The report analyzed the attack surface of 1,500 companies, uncovering more than 202,000 Common Vulnerabilities and Exposures (CVEs), 49% of those being classified as “Critical” or “High” severity.
- The report found nearly 400,000 servers exposed and discoverable over the internet for these 1,500 companies, with 47% of supported protocols being outdated and vulnerable.
- Public clouds posed a particular risk of exposure, with over 60,500 exposed instances across Amazon Web Services (AWS), Microsoft Azure Cloud and Google Cloud Platform (GCP).
It probably goes without saying, but as we consider solutions to meet new demands for decentralized configurations, security capabilities have to be evaluated as well. A technology provider must produce evidence that they not only offer a distributed service, but that they can keep an enterprise’s employees, devices and data secure in the process. Security capabilities go hand-in-hand with broader distribution of technology services.
Implications for Technology Providers
As the changes that I listed above continue to progress, they create demand for new approaches in several technology categories. Because this is fertile ground, technology providers who move quickly and design for these trends natively stand to benefit the most. The scope and velocity of these changes is creating a large market opportunity. While legacy technology providers and the cloud hyperscalers will likely capture some share, there will still be plenty of growth for smaller, independent players.
I have written in the past about why I think that in many categories of software infrastructure, security and networking that independent providers can outperform the large technology vendors and hyperscalers. Advantages revolve around their cloud agnostic posture, focus, talent and product release velocity. This continues to be the case today, and will likely be increasingly magnified going forward, as the technology landscape becomes more complex. This explains why independent companies increasingly dominate a number of service categories, like Twilio in CPaaS, Datadog in observability and Okta in identity. Even software service categories closer to the core of cloud computing, like data warehousing and databases, are experiencing encroachment from newer entrants like Snowflake and MongoDB (who incidentally run on the hyperscaler’s compute and storage infrastructure).
This isn’t to say that cloud vendors won’t field competitive solutions in new categories like edge computing and network security. However, by their very nature, self-interest, size and inertia, they will be slow to respond or leave large gaps for independent providers to exploit. Additionally, secular changes often provide a tailwind for all market participants.
The changes discussed earlier in remote work, consumer preferences and software delivery modes will impact four categories of technology services. I will discuss each below, focusing on what is changing and the requirements to address the new approaches. I will later tie these requirements to the product offerings and platform infrastructure of three leading, independent providers, who I think stand to benefit the most. The companies are Cloudflare (NET), Zscaler (ZS) and Fastly (FSLY). I currently or previously owned shares in each of these companies in my personal portfolio.
Network Connectivity
What is the Change?
Enterprise network connectivity is undergoing two major shifts, both of which represent a move from centralized routing and access control to point-to-point connectivity (SASE) and single use authentication (Zero Trust). These changes are being driven by the remote workforce, the proliferation of user devices and heavy use of SaaS applications for critical enterprise functions. When all employees worked in a corporate office on their company-issued desktop and all their productivity applications were located in the company’s data center, it was straightforward to connect these resources on a single corporate network and protect that from the public Internet with firewalls. For the occasional case of an outside party needing access to the corporate network, a VPN provided the controlled connection method.
However, as the majority of network users and enterprise software applications (SaaS) move outside the corporate perimeter, it becomes increasingly difficult to maintain a scalable firewall/VPN configuration. The stopgap measure was to force users to connect to the VPN in order to then be connected back to a SaaS application out on the Internet. This allowed the enterprise to control access and monitor traffic, but caused serious lag for users and capacity constraints for VPN hardware.
A better solution is to decentralize access by extending the whole network plane across the Internet. This means establishing network onramps near every population cluster and SaaS hosting facility globally. These onramps represent small data centers (PoPs) with clusters of servers and multiple high-throughput network connections to the Internet backbone. These PoPs are all interconnected by a secure private network, in which routing is defined by software (SDN). A software-defined network (SDN) allows the route to be changed for every request. SDN contrasts with the older approach of maintaining fixed routes that are only updated by a configuration commit on the physical equipment.
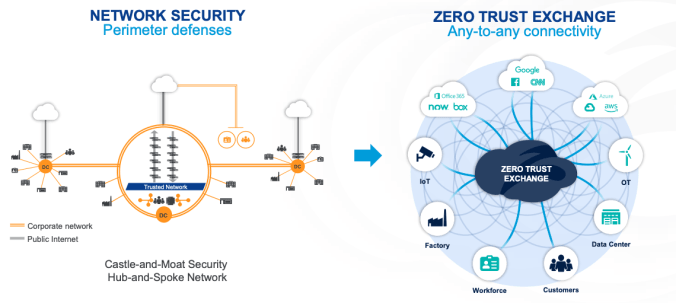
A point-to-point model (through PoP to PoP connections) obviates the prior approach of having a single entry point for corporate traffic ingress and egress. The benefit of the single controlled entry point was that the user could be authenticated once and then granted access to all resources on the corporate network. As hackers became more sophisticated, this method of authenticating once for a golden ticket provided a useful way to access many corporate resources through a single exploit. Once they gained access to the corporate network, hackers could “move laterally” to attack every resource.
Given this risk, security teams and providers began adopting a “Zero Trust” posture. In simple terms, this means that the user has to authenticate to every corporate resource separately on every interaction. This replaced the prior approach of authenticating once and then having access to all resources as long as the user session was active. Zero Trust significantly reduced the hacker’s ability to move laterally around the corporate network.
Point-to-point network connectivity and Zero Trust naturally work together. If a user’s device can connect directly to every resource, then that connection would have to be authenticated on each attempt. Forward-thinking providers realized this and stitched the two together. They built a global, intertwined network of PoPs and layered access controls on top of it. This way, a user anywhere on the globe could be routed to the closest PoP and authenticated to the resource they wanted to access. To manage this, the user would run a software agent on their device. Enterprise applications could similarly be obfuscated from public view and third-party SaaS applications could only be reached through controlled connections.
The CEO of Zscaler summarized the new demand environment as “The Internet is the new corporate network, and the cloud is the new center of gravity for applications.” This underscores the outcome of applying Zero Trust practices to a SASE network. With those services layered over the Internet, it is feasible for enterprises to treat the Internet like a private network. This new approach replaces years of capital spend on fixed network perimeters and physical devices to protect them.
What does a provider need?
In order to support a SASE network configuration with Zero Trust access control, a provider needs to have several capabilities.
- Network of entry points (PoPs). A provider should have owned and operated PoPs distributed globally, located in proximity to major population centers. Each PoP contains a concentrated cluster of high-performance servers with multiple network connections to the Internet backbone. In theory, the function of a PoP could be deployed on top of infrastructure maintained by cloud vendors, and some providers have tried this approach to fast-track the creation of a global PoP network. However, this tactic will ultimately be less effective. The provider will be limited by control over the full network stack (SDN), flexibility to customize hardware and geographic proximity.
- Software defined networking (SDN). Software defined networking provides the ability to dynamically and programmatically control the configuration of the network and the routing of traffic through it. This yields two benefits. First, the PoP can determine the routing for each request in real-time. This might be used to find an optimal path to the destination based on congestion or for certain types of content, like video, to ensure high availability. The second benefit is security related. The system can monitor for nefarious incoming traffic patterns, like a DDOS or bot attack, and re-route or blackhole that traffic.
- Traffic inspection. As network data packets flow through the PoP, it needs the ability to inspect them. This requires a lot of compute power as each data packet must be parsed, looking for pre-defined patterns. As most Internet traffic is encrypted, this examination needs to include SSL inspection. Decryption adds to the compute load. Traffic inspection gives the network provider the ability to identify malicious code or sense denial of service attempts.
- Threat monitoring. Foundational to handling all of an enterprise’s network traffic is the ability to maintain security. Fortunately, with all that traffic flowing through their PoPs and the ability to examine it, distributed network providers are in a very favorable position. They have visibility into a huge amount of activity on the Internet, aggregated across many enterprises. They get a first look at nefarious behavior and unusual patterns of activity. These can be quickly examined by a security-minded team to create new patterns to monitor. Similarly, AI/ML routines can be overlaid on the network data to automatically flag potential security threats. These threat identifiers can then be fed back into the real-time monitoring system. Of course, with a software defined network, the system can immediately take action to block or blackhole the activity. Or, if the threat isn’t 100% verified, the system could require an additional user action, like issuing a warning about a download or asking for further authentication.
Application Processing and Runtime
What is the Change?
Digital transformation, IoT and big data creation are increasing the demands placed on software delivery infrastructure. Consumers expect feature-rich, responsive digital experiences from enterprises. In the early days of the Internet, hosting an applications’s full runtime and data in one geographic location to serve the globe was marginally acceptable. For today’s global software services, that is no long the case, as latency impinges on usability.
By placing an application’s resources closer to the end user, transit times are reduced. This was the genesis for CDN’s in the early 2000’s for web content. But, early CDN’s were limited to static content, not dynamic processing. With IoT, clusters of connected smart devices will operate more efficiently if the application coordinating them is running in close geographic proximity. The shipment of large volumes of raw sensor data to a central location for processing is inefficient and costly. That data can be processed locally and the summary can be forwarded.
These factors all favor distribution of compute resources into regional locations across the globe. If an application can be subdivided into services and the most latency sensitive ones can run close to the user, then lag can be minimized and data transit costs will be reduced. This is made possible by distributing compute, in addition to content, to inter-networked data centers (PoPs) spread across the globe. Each PoP can maintain a copy of the application’s code and the ability to instantiate a runtime quickly in response to each user’s request. This code would run independently of the rest of the application, communicating with other services when necessary through open network protocols.
In order to prevent application owners from needing to run their own hardware in each PoP, the runtimes would be serverless and multi-tenant. Each runtime would be isolated from the others, without sharing resources like memory. Developers could address these environments from a single instance, and have their code duplicated globally on the click of a button.
What does a Provider Need?
- Serverless, multi-tenant runtime environment. In order for a provider to execute customer code in a distributed fashion across a network of PoPs, the runtime really has to support multi-tenancy. It wouldn’t be scalable to dedicate compute resources to each customer. This means that customer code is loaded into an isolated runtime environment on every user request. That runtime does not share memory space with any other process on the CPU. Similarly, the runtime must be serverless, or else it wouldn’t scale (the provider can’t keep a server running continuously for each customer). Running code for many customers in parallel within the same set of physical servers, duplicated across tens or hundreds of PoPs, is not a trivial undertaking. It requires sophisticated capabilities that only a handful of companies can address. The capital investment to deploy this kind of configuration is significant, creating a barrier to entry and hence a moat. While a provider could in theory spin up clusters of servers on hyperscaler data centers to emulate a PoP, they would never match the performance or efficiency of a provider that owns and operates their PoPs.
- Isolation. The risk for a multi-tenant provider is that a hacker finds a way to snoop on the application data of another customer’s runtime. In order to prevent this, the provider needs to design the runtime such that each customer process is fully isolated. This means that no memory can be shared and all data residue must be purged from processor caches before the next customer request is started. Also, the provider should employ sophisticated monitoring to look out for activity indicative of a snooping attempt. Usually, this takes the form of unusual memory scans or repeated runs of certain type of code that reveals characteristics of the CPU. Providers can monitor for this activity and block customers that engage in this behavior.
- Code distribution. A provider needs the ability for customers to upload code into the distributed runtime environment and have that be disseminated automatically to all PoPs. Ideally, updates would be rolled out very quickly, so that a customer can address critical fixes in near real-time. Additionally, customers would need the ability to access a test environment and promote code from one environment to another.
- Observability. The customer will want to understand how their code performs in the distributed runtime environment. They will want to be able to measure speed of execution and identify any bottlenecks (APM). Also, errors should be logged and surfaced for the customer, either through a real-time interface, or integrated with a log analysis tool. Ideally, the monitoring is aware of the execution path across all services within the application, allowing the customer to identify problem areas. Integration with other popular cloud-based observability tools (like Datadog) is useful here.
Data Distribution
What is the Change?
As application logic moves away from centralized data centers to locations closer to the user, the breadth of addressable use cases expands if data can be stored locally. There are some use cases that run at the network edge which are stateless. These include simple routing rules, API request stitching and logic gates, like an A/B test. In these cases, there isn’t a need to access persisted user-specific data. While these use cases provide a performance benefit to the application by relocating to the network edge, they account for a small percentage of an application’s functionality.
A broader set of use cases is available when user data can be stored across requests. The first level of progression is a cache into which user data can be stored during a user’s session. The cache will generally be localized to the PoP that the user is currently connected and will be purged after some period of time. A simple cache does open up another slice of use cases, like authentication tokens, session data, shopping carts and content preferences. This type of data can be pulled from the central location at the start of a user’s session. Or, it can be compiled over the course of the session. In either case, with cached data available for the application at the local PoP, the user’s perceived response will be much faster.
A bigger benefit occurs when an application is coordinating activity across multiple connected devices in a geographic area, like all the traffic lights and flow sensors on a city’s traffic grid. For this case, having data available to the application in a PoP near that city would make a huge improvement in performance, versus shipping every data update and logic decision to a central data center on the other side of the continent.
This clustering proximity benefit can apply to human users as well. If multiple users in a geographic location are interacting with the same application at once, then caching application data within a local PoP will improve responsiveness. This could apply to the experience for a multi-player game with geographic context (like Pokeman Go) or a collaboration tool (like a shared document). On the industrial side, clusters of human operators, like in a hospital, retail location or construction site would see a benefit.
The next stage of data distribution is to store user data across sessions. This starts to lend permanence to it. In this case, the provider has to think more broadly about security of the data and capacity. They would need to set expectations with application hosting customers about how durable the data can be and whether they still need to write back to a central store after each user session in order to ensure no data loss. As the data storage capacity at each PoP is presumably finite (central data centers can manage potentially infinite capacity more easily), the provider would need to establish policies to manage data usage across customers and consider how long they need to retain a customer’s data in each location.
The final solution for fully decentralized data stores is to support full-featured transactional databases at each edge node. These would be located in every PoP (or at least geographically close to it) and available to the application runtime. Data would be persisted across user sessions and available to all users of the application. That application data could be shared across PoPs, with an expectation that state would be eventually consistent between nodes.
A requirement for strong consistency increases the complexity of the system by an order of magnitude. Clustered data storage systems like Cassandra have wrestled with various algorithms to ensure that data is synchronized to all nodes. There are different tactics to address consistency. Other approaches involve a form of data replication. Some providers are researching new data storage methods, like CRDTs, which sidestep challenges around ordering of data updates by supporting only data structures that support consistency in all cases.
Regardless of the approach, data access patterns should be familiar to developers. Caches are commonly used in central data centers to prevent heavy database queries. Examples are Redis and Memcached. These are generally structured as key-value stores. These systems provide client library code in many programming languages that make the process of reading and writing key values very easy – abstracting away any underlying complexity of setting a unique key, checking for stale data, triggering a refresh, etc.
For full-fledged databases at the application edge, the ideal is standard support of CRUD actions through SQL. Most developers are familiar with relational databases, or document-based data stores like MongoDB. In either case, the developer should be able to expect access libraries provided for their language of choice and adherence to common data access patterns.
For all of these solutions, data residency can add another layer of complexity and requirements. As governments and user organizations stipulate a preference for keeping user data within a geographical boundary, data distribution strategies to geographically bound PoPs suddenly move from the realm of application performance optimization to core requirement. This also argues for permanent data storage in each PoP, versus a cached approach. This is because data in a cache would eventually need to be written to a central store in order to persist across user sessions. If that central store is in another country, then the residency requirement is broken.
Currently, data residency requirements are manageable, because the number of countries with active regulations is limited to the EU and China. A few other countries, like India and Brazil, are considering it. This level of adoption is manageable because a central data center could be established in those countries and the application instance would be constrained to that geographical boundary. However, if these regulations proliferate and every country adopts them, then distributed data storage will quickly become mainstream. Maintaining an isolated copy of every application and its data in each country would be difficult to manage. Utilizing a serverless, distributed system of compute with localized, permanent storage, would offer a much better solution architecturally.
What does a Provider Need?
In order to offer a solution for localized distribution of application data, a provider needs a few capabilities. These assume they already have a global network of PoPs connected by a SDN.
- Data Storage. Obviously, the basic capability is to have a place to store data. This requires a large amount of memory (for caches) and fast disk (for long-term storage). There should be enough capacity planned to accommodate data usage for all customers. Capacity planning becomes more stringent than for centralized data center storage providers because data storage is duplicated across all PoPs. Depending on the expectation set with customers for durability of their data, the provider would need to set up algorithms for purging older data to create space for newer data when needed.
- Consistency Methods. If the provider sets an expectation that application data is available across PoPs, they will need mechanisms to distribute copies of data. They also need to have methods to address eventual consistency or enforce strong consistency. Each has trade-offs in access latency and durability.
- Localization Controls. The provider should have have capabilities to keep application data within geographic boundaries when required. This implies a mapping of PoPs to each country and methods to override user-to-PoP assignments based on country borders and not geographical distance (closest PoP to a user may be across a border). In the event of a network or PoP failure, the same logic should be enforced, overriding standard re-routing algorithms.
- Developer-friendly Interfaces. As providers set up distributed data stores and make them available to application developers, the data access patterns and tooling should be familiar. If the data store is a key-value store, the developer should have access to a code library that abstracts the mechanics of setting and updating key values. If a full-featured database is available to the developer, the provider should mirror well-understood patterns for data access, like SQL support.
Identity
What is the Change?
In response to concerns around user privacy, one of the more recent trends is decentralization of identity. In this context, the ownership and distribution of user data is moving from multiple copies managed in centralized enterprise stores to a single copy managed by each user. Rather than establishing a duplicate copy of login credentials, preferences and personally identifiable information (PII) with each digital business, the user would manage a private, encrypted copy of their own data and share that with each digital channel as needed. Identity would be established through a single, consistent authentication method. The user could share data needed by each enterprise on a temporary basis. Enterprises would be prohibited from storing identifiable user data permanently.
In this way, identity management would be distributed to the users themselves. A user’s identity might be established initially by government policy, and then built up with other third-party credentials. User reputation would accumulate over time and verifiable credentials would allow commercial parties to assess risk based on the depth of user reputation available. The key distinction from today’s model is that the user would be in control of what credentials they assemble and the depth of data they are willing to share.
One emerging standard that addresses these goals is Decentralized Identifiers (DIDs). These enable verifiable identity of any subject (person, organization, etc.) in a way that is decoupled from centralized registries or identity providers. DIDs can be established for an individual, allowing them to engage with any Internet service with a single identity over which they have full control. The individual can decide the level of personal information to share with each application.
DIDs begin life with no evidence of proof, representing an empty identity. They can then be tied to an owner who can prove possession of the DID. DIDs can build up legitimacy through attestations from trust providers like governments, educational institutions, commercial entities and community organizations. Any of these endorsements could be independently verified. By accumulating attestations from multiple trust systems over time, an identity can build up enough proof of its legitimacy to enable it to surpass whatever risk level is established by an app or service.

As an example, the identity of Jane Doe might be established at birth by her government. She would be assigned a cryptographically secured wallet, into which all identity information would be stored. As she aged, additional attestations from educational institutions (test scores, degrees, other credentials), financial organizations (credit scores, loan repayment, accounts) or civic organizations (membership) might all be collected. Jane would also be able to keep personal information (name, address, phone, preferences ) up to date. Finally, she could set up different profiles that would be shared with online services based on context. Twitter might get a pseudonym with limited information, whereas her bank would have access to her full identity.
What does a Provider Need?
In order to support a decentralized identity service, a provider would need to support several components of the DID service framework. As a software infrastructure platform, their solutions would primarily enable applications to interact with these new identity services and provide network connectivity to use them for authentication. Since these standards are emerging, providers have latitude to determine what services they plan to offer.
- Identity Hub. A provider might host a version of an identity hub. This is a replicated database of encrypted user identity stores. These facilitate identity data storage and interactions. They also allow authentication with other systems like applications and network access. Network providers might maintain a purpose-built version of an identity hub on behalf of their enterprise network customers to facilitate Zero Trust.
- Universal Resolver. A universal resolver is a service that hosts DID drivers and provides a means of lookup and resolution of DIDs across systems and applications. Upon authentication, the resolver would provide an identity object back to the requestor which contains metadata associated with the DID. A provider might host a version of the universal resolver for its customers.
- User Agent. User agents are applications that facilitate the use of DIDs for end users. This might not represent a consumer service, but could be a software application provided to enterprise customers for their employees to utilize. This generally takes the form of a cryptographically signed, wallet-like application that end users utilize to manage DIDs and associated identity data.
- Decentralized applications and services. Since providers offer development and runtime environments for application builders, they could host applications or services on behalf of decentralized organizations. These might interact with end users through services supported by providers that interface with end users through public DID infrastructure.
Web 3.0 and Dapps
I realize that the term decentralization is sometimes associated with new developments around decentralized apps (dapps) and Web 3.0. My use of decentralization focuses primarily on the associated changes in software delivery architecture, data storage and network infrastructure, versus considerations for token economics, autonomous organizations and distributed ownership. Putting aside business models, I focus on the technology needed to deliver the next generation of digital experiences at scale.
As current software infrastructure providers evolve to support a more decentralized application architecture and network configuration, many of the patterns employed overlap with Web 3.0 concepts like edge computing and distributed data structures. The development of large parts of decentralized applications could be supported by existing software infrastructure providers, whether through existing products or a future incarnations.
In fact, many businesses that are blockchain-related employ software services from existing infrastructure providers. As an example, the decentralized exchange dYdX utilizes the Ethereum blockchain to record transactions. The vast majority of activity on the exchange is stored in the order book, which is processed by the matching engine. The order book records all the offers to buy or sell a cryptocurrency and the matching engine generates the actual purchase transactions. Due to the type of activity on the exchange (derivatives, options), a subset of all orders actually result in a transaction which is recorded on the blockchain.
In an interview on Software Engineering Daily, the founder of dYdX discussed the technology platform behind the exchange in detail. He mentioned that the order book and matching engine, which handle over 99% of the activity on the exchange, are hosted on AWS and utilize PostgreSQL as the data storage engine. While the final transaction is recorded on Ethereum, the rest of the application utilizes existing software infrastructure.
The Serverless Chats Podcast offers a wonderful resource on the state of serverless computing and touches on many concepts of both distributed and centralized implementations. In a recent show, the host interviewed the Developer Relations Engineer at Edge & Node, which is the company behind The Graph. The Graph is an indexing protocol for querying blockchain networks. Data collected can then be exposed through open APIs for dapps to easily access. Edge & Node also builds out decentralized apps themselves.
During the discussion, the two were hypothesizing about practical use cases for Web 3.0 technologies and the flavors of applications that would be suitable for this application infrastructure, at least in the near term.
To me when I think about building apps in Web2 versus Web3, I don’t think you’re going to see the Facebook or Instagram use case anytime in the next year or two. I think the killer app for right now, it’s going to be financial and e-commerce stuff.
But I do think in maybe five years you will see someone crack that application for, something like a social media app where we’re basically building something that we use today, but maybe in a better way. And that will be done using some off-chain storage solution. You’re not going to be writing all these transactions again to a blockchain. You’re going to have maybe a protocol like Graph that allows you to have a distributed database that is managed by one of these networks that you can write to.
Serverless Chats Podcast, Episode 106
Some of the emerging concepts in decentralized identity management are very interesting and likely have near term broad application. As discussed earlier, Decentralized Identifiers (DIDs) enable verifiable identity of any subject (person, organization, etc.) that is decoupled from centralized registries or identify providers. Not wanting to miss out on this trend, Microsoft is building an open DID implementation that runs atop existing public blockchains as a public Layer 2 network. This will be integrated into their Azure Active Directory product for businesses to verify and share DIDs.
Like Microsoft, other existing software infrastructure providers can participate in the evolution of Web 3.0, dapps and blockchain-based networks. Fundamentally, the same arguments for decentralization of compute, data and network flows align with the trends we have been discussing in this blog post. The Web3 Foundation published a useful block diagram of the Web 3.0 technology stack, depicting the different layers upon which a decentralized app could be built. These are labeled in generic software component terms.
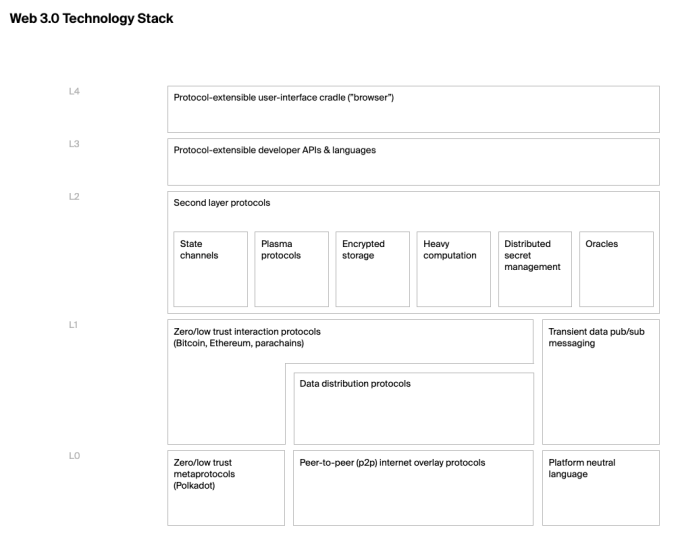
Abstracted out in this way, many of these higher-level software services could be offered by existing technology companies. As an example, DocuSign saw an opportunity early to provide support for blockchain. In 2015, they worked with Visa to create one of the first public prototypes for a blockchain based smart contract. DocuSign is currently a member of the Enterprise Ethereum Alliance, and in June 2018, announced an integration with the Ethereum blockchain for recording evidence of a DocuSigned agreement.
A similar argument can be made for Cloudflare. Their mission is to “help build a better Internet”. With over 200 PoPs (data center locations) spread across 100 countries, they can generically be considered as a high capacity distributed network. In a recent interview on alphalist.CTO, Cloudflare’s CTO, John Graham-Cumming, described the function of his team as focusing on future technologies and innovation for Cloudflare.
On the podcast, the CTO mentioned they had been examining the function of Ethereum and blockchain-enabled networks, and what opportunities may exist to align these with Cloudflare’s basket of software services. Along these lines, Cloudflare announced in April that they had added support for NFTs to their video Stream product. With their product development momentum, developer centric motion and financial position, it wouldn’t be a stretch to see Cloudflare expand their offerings to address other aspects of Web 3.0 software infrastructure and tooling. Many of the architectural advantages of dapps, like isolation, autonomy and data distribution, are characteristics of serverless edge computing.
In fact, a smart contract could be generically viewed as a distributed serverless function. It is created using a programming language and compiled into bytecode that runs on a virtual machine. The code applies conditionals, invokes loops, specifies actions and updates state. This code is executed across a distributed network of processing nodes that respect multi-tenancy. These are characteristics of edge compute solutions provided by Cloudflare and Fastly.
One of the future directions for optimizing the Ethereum network involves updating the Ethereum Virtual Machine (EVM). One of the proposals that appears to be gaining steam is to migrate the runtime for Ethereum transactions to be based on WebAssembly (WASM). This flavor of virtual machine is being referred to as eWASM, basically Ethereum’s transaction framework based on WebAssembly. eWASM provides several benefits over EVM, including much faster performance and the ability to utilize multiple programming languages for smart contracts.
The reason I find this interesting is that several serverless edge networks utilize WebAssembly as the runtime target. These products include Cloudflare Workers and Fastly’s Compute@Edge. In the case of Fastly, they further optimized the WASM compiler and runtime for extremely high performance, released as the open source project Lucet. Lucet claims to the best performing WASM runtime available. I mention these examples because if Ethereum moves its virtual machine to be WASM based, then software providers like Cloudflare and Fastly may be able to extend their existing WASM tooling to offer services to the smart contract ecosystem.
I think decentralized applications and infrastructure have a lot of promise. The leading technology providers today support many of the underlying architectural concepts and could offer software services to address them. As with dYdX, these new business models should generate incremental usage for existing infrastructure providers, not less.
Leading Players
Since this is a blog primarily about investing, I want to make these decentralization trends actionable for investors. To do that, I will apply them to three independent leaders in secure, distributed networking and compute. These publicly traded companies are Fastly (FSLY), Zscaler (ZS) and Cloudflare (NET). I will also use this opportunity to provide a review of their most recent quarterly results and how I am allocating my personal portfolio towards these stocks.
I realize that the space of edge compute, networking and security is broad, and that many larger technology providers, including the hyperscalers, are converging on this space. My thesis is that smaller, nimble independent providers will be able to carve out a meaningful share of the market due to their focus, product velocity and appeal to talent.
Fastly (FSLY)
Fastly started as a CDN provider, but always had aspirations to offer a full-fledged edge compute environment. Their network currently spans 58 locations across 26 countries. Each location can contain one or more PoPs, as represented by their “Metro PoP” strategy for high density areas, like Southern California.
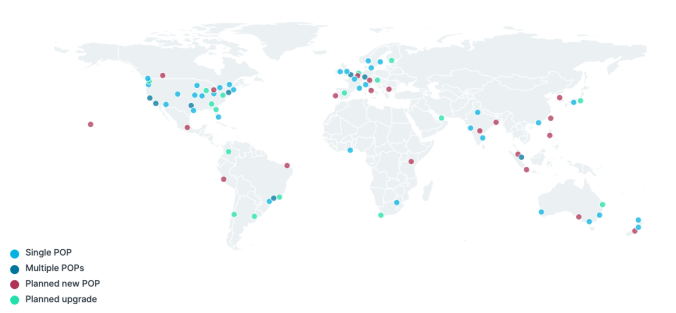
Early on, Fastly established a strategy of building fewer, more powerful PoPs at select locations around the world. By utilizing PoPs with large storage capacity, they achieve high cache hit ratios for content requests. This can result in better performance for their customers, as a cache miss can cause much more overall latency as the request routes all the way back to origin. They also maintain high throughput on their network, with 130 Tb/sec of capacity available, triple the value at IPO in 2018.
Because of this focus on performance, Fastly built up a strong stable of marquee digital native customers. The majority of their revenue is still derived from content delivery, although they also offer security products focused on application delivery continuity. These include DDOS, bot mitigation and WAF/RASP. Their application security capabilities were solidified by the 2020 acquisition of Signal Sciences.
Besides the addition of a full suite of application security services, the big opportunity for Fastly is to leverage their interconnected network of PoPs to deliver distributed application processing and data services. These are encapsulated in Fastly’s serverless edge compute offering, called Compute@Edge. Fastly has been working on this platform for several years and moved it into Limited Release in Q4 2020.
As Fastly was designing their edge compute solution, they evaluated existing technologies for serverless compute, like re-usable containers. However, they found the performance and security capabilities to be lacking. They ultimately decided to leverage WebAssembly (Wasm) which translates several popular languages into an assembly language that runs very fast on the target computer architecture.
WebAssembly was spawned as a browser technology, which has been recently popularized for server-side processing. At the time, the common method of compiling and running WebAssembly was to use the Chromium V8 engine. This results in much faster cold start times than virtual containers, but is still limited to about 3-5 milliseconds. V8 also has a smaller, but non-trivial, memory footprint than a container. In the end, Fastly wanted full control over their environment and decided to build their own compiler and runtime, optimized for performance, security and compactness.
This resulted in the Lucet compiler and runtime. Fastly has been working on this behind the scenes since 2017. Lucet compiles WebAssembly to fast, efficient native assembly code, which enforces safety and security. Fastly open sourced the code and invited input from the community. The was done in collaboration with the Bytecode Alliance, an open source community dedicated to creating secure software foundations, building on standards such as WebAssembly. Founding members of the Bytecode Alliance are Mozilla, Red Hat, Intel and Fastly. Microsoft and Google recently joined as well, adding more industry clout to the movement.
Lucet supports WebAssembly, but with its own compiler. It also includes a heavily optimized, stripped-down runtime environment, on which the Fastly team spends the majority of their development cycles. Lucet provides the core of the Compute@Edge environment. As an open source project, customers can choose to host it themselves.
In December 2020, Shopify did just that. They added a new capability to their core platform that allows merchants to create custom extensions to standard business rules. These can be coded by the merchant or partner, but are run in a controlled environment within the Shopify platform. This approach allows Shopify to ensure the code is executed inline, but in a fast, isolated environment.
For this platform capability, the Shopify team chose to use Lucet. Shopify selected this architecture for the same reasons that Fastly decided to build it themselves. While most serverless compute runtimes leverage the V8 Engine, Fastly’s Lucet runtime is purpose-built for fast execution, small resource footprint and secure process isolation. Lucet generally exceeds V8 performance along these parameters.
In ecommerce, speed is a competitive advantage that merchants need to drive sales. If a feature we deliver to merchants doesn’t come with the right tradeoff of load times to customization value, then we may as well not deliver it at all.
Wasm is designed to leverage common hardware capabilities that provide it near native performance on a wide variety of platforms. It’s used by a community of performance driven developers looking to optimize browser execution. As a result, Wasm and surrounding tooling was built, and continues to be built, with a performance focus.
Shopify Engineering Blog, dEc 2020
This choice by Shopify validates Fastly’s architecture design and general approach. Keep in mind that Shopify could have chosen to utilize the V8 Engine for the same workload. However, they favored the near instant cold start time of 35 micro-seconds and the smaller footprint offered by Lucet. Additionally, they decided to support AssemblyScript as the programming language for partners to utilize for this environment. This is also one of the first-class languages for Compute@Edge. Shopify plans to invest engineering resources in building out new language features and developer tooling for AssemblyScript. This work will in turn help Fastly, as AssemblyScript has become core to Fastly’s strategy of catering to JavaScript developers.
For more background on Fastly’s edge compute solution, I covered it extensively in a prior post. When compared to other serverless, distributed compute runtimes (specifically the V8 Engine), Fastly’s solution has the following distinguishing features:
- Performance. As Shopify’s feedback indicates, Lucet and Fastly’s Compute@Edge platform have the best performance of any serverless runtime environment. This is measured in cold start times (100x faster) and memory footprint (1,000x smaller).
- Language Support. However, this performance comes with a major drawback. Lucet only supports languages that can be compiled into WebAssembly. Currently, this includes Rust, C, C++ and AssemblyScript. This leaves out a number of popular languages that are supported by other runtimes, most notably Javascript. While seemingly downplaying the need to support JavaScript initially, the Fastly team has now prioritized development to add support for it.
- Operating System Interface. While Lucet runs WebAssembly code in a secure sandbox, there are potential use cases that would benefit from having access to system resources. These might include files, the filesystem, sockets, and more. Lucet supports the WebAssembly System Interface (WASI) — a new proposed standard for safely exposing low-level interfaces to operating system facilities. The Lucet team has partnered with Mozilla on the design, implementation, and standardization of this system interface.
- Security. Because of super fast cold start times, each request is processed in an isolated, self-contained memory space. There is only one request per runtime and data residue is purged on conclusion. The code compiler ensures that the code’s memory access is restricted to a well-defined structure. Lucet employes deliberate memory management to prevent cross-process snooping.
For languages in particular, because Fastly chose to build their own runtime in Lucet (versus leveraging the V8 engine, like most competitors), Compute@Edge will only run languages that can be compiled to produce a WebAssembly binary. This greatly reduces the language set available (at least currently), relative to the V8 engine. The V8 engine can also run JavaScript, which expands the set of candidate languages greatly, as many popular ones have an available compiler to JavaScript. Fastly’s Chief Product Architect explained this design choice for Compute@Edge in a past blog post.
During the Altitude user conference last November, Fastly’s CTO was optimistic that language support for WebAssembly will continue to expand in the future. In fact, when asked a question about the 5 year vision for Compute@Edge, he felt that all popular languages will eventually support WebAssembly as a deployment target. This will significantly lower the adoption barrier for less experienced developers.
Distributed Data Storage
While Fastly’s development of a highly performant serverless edge compute platform has been notable, their public progress on a distributed data store has been slower. They are developing a fully distributed data storage solution as part of their Compute@Edge platform. On a recent podcast on Software Engineering Daily, Fastly’s CTO said the founders first wanted Fastly to provide a distributed data service from their POPs. But, they soon realized this would be more relevant to developers if it could be referenced from a compute runtime. This caused them to prioritize building out the Compute@Edge solution first, before tackling data storage.
During the Compute@Edge talk at Altitude, the customer panel mentioned looking forward to a new offering, referred to as Data@Edge. While this hasn’t been formally announced by Fastly, we can assume it represents a new distributed data store for use by the serverless runtime. Fastly has a basic local cache available for the existing VCL environment called Edge Dictionaries. Data@Edge would presumably take this to the next level, providing an eventually consistent, distributed data store with a CRUD-like data interface for developers to use.
Fastly’s Principal Engineer, Peter Bourgon, discussed a data storage layer in the past. He weighed the challenges of building a distributed state management solution in a blog post from July 2020 and also in a tech talk at QCon London. The implied technical direction was to leverage CRDTs (conflict-free replicated data types), which have the benefit of guaranteed consistency, but more complexity in implementation.
In the blog post, he said that “Fastly is actively prototyping and deploying a CRDT-based edge state system.” Perhaps Data@Edge will represent the first incarnation of this to provide data storage for Compute@Edge. A job posting for a Senior Software Engineer – Data Storage Systems implies the same. The engineer will be responsible for building the infrastructure to enable state at the edge. The job description implies this role will be part of a team of engineers and that data storage will be leveraged to drive other product offerings in the future.
In addition to providing distributed data storage for use by Compute@Edge, Data@Edge might be offered as a stand-alone service. This would be similar to Fauna, which is a popular globally distributed, cloud-based data store. It is completely accessible through APIs and meant to be connected to directly by client applications (web or mobile). This future-facing approach to application development and infrastructure is dubbed the Client-serverless architecture and aligns well with Fastly’s capabilities.
Other Decentralized Solutions
Another insightful Altitude session covered the product roadmap for 2021. This was led by Fastly’s heads of engineering and product. The session provided a brief overview of the planned product roadmap going into 2021. It started with Compute@Edge and Secure@Edge (application security leveraging the Signal Sciences platform), which we would expect. However, they introduced two new product categories, called Perform@Edge and Observe@Edge.

I found this very interesting, as Fastly is already expanding their “@Edge” product franchise and applying the label to new categories. It isn’t clear at this point if the new products would generate additional revenue streams. Perform@Edge represents a formalization and doubling-down of content delivery and streaming, with new capabilities lined up for more robust video delivery support. Observe@Edge will build on top of Fastly’s existing logging and stats functionality to add deep observability, application tracing features, advanced analytics and alerting. The programmatic aspects of these offerings will be built on the Compute@Edge runtime, offering further evidence for the versatility of their compute platform.
Strategic Directions
As we consider all aspects of decentralized architectures discussed earlier, Fastly appears to be focusing on distributed compute at this point. They are not leveraging their capabilities to provide SASE and Zero Trust network services for enterprises. Additionally, they have not made a major release recently for facilitating distributed data storage to complement their compute offering with broader state management.
With Fastly’s focus on content delivery and edge compute, they do have the potential to become a significant provider of a distributed runtime with built-in application security. As their existing customer base primarily focuses on delivering web experiences over the Internet, these offerings are well-aligned with demand. Use cases will continue to grow and benefit from a desire to improve delivery performance to end users, made more acute by digital transformation initiatives.
In their investor presentation from August, Fastly leadership sized the addressable market at about $35B. In this case, they estimated an $18B market for edge computing and application security at the edge, and another $17.5B for the existing markets around content delivery and video streaming. We can assume that sales opportunities in edge application compute and security will be more greenfield, while content delivery would likely represent a mix of competitive displacement with some greenfield opportunities from new content distributors or expansions.

As investors consider the TAM, it is worth thinking about the paradigm that Fastly and other edge network providers are enabling. This is represented by the shift of delivery architecture from single deployments of server clusters to a mix of centralized and distributed application delivery points. This shift will encompass both compute and data storage.
Once Fastly brings a distributed data solution to market, I think the use cases for their edge compute solution will expand. The majority of logic in an Internet application is stateful, rather than stateless. A distributed data storage capability also provides a mechanism to address data residency requirements.
Quarterly Results
Fastly reported Q1 results on May 5th. The results were not well received by the market, with the stock dropping 27% the next day. Most of that drop has recovered in the last two months, with the current price almost inline with pre-earnings levels. However, FSLY is still down about 35% YTD. Its P/S ratio is under 20, after peaking in the 40’s last year.
Q1 revenue of $85M grew 35% year/year, which was about inline with analyst estimates for $85.1M. The issue was with the Q2 revenue estimate for $84M – $87M, representing 13% year/year growth. This was below analyst estimates for $91.7M. However, Fastly did raise their prior full year revenue estimate by $5M at the midpoint to $380M – $390M, representing growth of 32.3%. This reflects management’s expectation for an acceleration in revenue growth in the second half of 2021, after clearing the Q2 overhang. As investors will recall, Q2 2020 benefitted from a surge in revenue due to pandemic overages and TikTok usage. TikTok then substantially dropped usage of most third-party platforms in Q3 due to U.S. government oversight. Year/year comparables have been challenging since that event.
Customer growth showed improvement in Q1, after slowing down in Q4. Total customers were 2,207 at the end of the quarter, up 123 or 5.9% from end of Q4 and 20% year/year. This represents a significant jump in total customers adds – the largest increase ever, after adding just 37 customers in Q4 and 96 in Q3. Enterprise customer counts increased by 12 in Q1, which represents the largest increase in the last 4 quarters. This pick up in customer activity could be attributable to the new sales head hired in February. It may be too early to tell, but the preliminary signs are positive.
Existing customers also expanded their spend in Q1, but at lower rates than Q4. To account for customer churn, Fastly has publishes several measures of expansion rates. These include the following:
- DBNER (excludes churn): Dipped to 139%, from 143% in Q4.
- NRR (includes churn): Dropped to 107% in Q1, from 115% in Q4.
- LTM NRR (includes churn, but normalized over 12 months): Dropped to 133% in Q1, from 137% in Q4
The expansion metrics are something investors should monitor over the next few quarters. While the trend is down currently, I suspect these will stabilize. NRR should improve once we clear the TikTok anniversary in Q3. If Fastly can maintain annualized total customer additions in the 20% range and stabilize spend expansion (NRR) in the 130% range, then they would be set up for favorable, sustained revenue growth of 40+%.
On the product front, new announcements were light. Management highlighted one new customer of Compute@Edge (HUMAN security), along with the recently added Nearline Cache and Log Tailing features. Nearline Cache enables organizations to stage content in cloud storage near a Fastly PoP that doesn’t incur egress costs. This allows customers to reduce origin serving costs while also making delivery more resilient. These features were built using the Compute@Edge platform by Fastly’s internal engineering team, highlighting their first external product offering utilizing their edge compute platform.
Fastly ramped up network capacity to 130 TB/sec, which is a 48% increase from 88 TB/sec a year ago. They also added two new PoP locations, bringing the total number to 58. These span 26 countries. As of April 30, Fastly’s network of PoPs is serving over 800B requests a day with cache hit ratios near 90%. The high cache hit ratio is a consequence of Fastly’s strategy to build fewer PoPs, but with higher storage capacity to avoid a cache miss.
Fastly Take-Aways
While some of their recent results show promise, for now, I will remain on the sidelines with Fastly (FSLY) stock. The pace of product releases is still restrained. I was excited by all the new “xxx@Edge” opportunities highlighted during the Altitude conference in November 2020. However, we haven’t seen any updates on these in the subsequent 8 months. It’s possible there is a lot going on under the hood and we may see a flood of announcements later this year at the next user conference. Additionally, we have received only a glimpse of customer uptake on Compute@Edge. I would like to see more real-world examples of adoption at scale.
Distributed data storage is another area of product development where Fastly needs to demonstrate progress. Their existing Edge Dictionaries offering provides a basic local cache and is comparable to Cloudflare’s Workers KV product. Hints of new distributed data solutions with strong consistency, like Data@Edge, would presumably take this to the next level. Leadership has talked about the need for a globally consistent, distributed data store with a CRUD-like data interface for developers to use. Layered on top of this should be controls and logic to meet data residency requirements.
On the business side, customer additions appear to be re-accelerating and net expansion measures should stabilize after lapsing the TikTok impact. A renewed focus on go-to-market with the new CRO should bring back more consistent sales execution for existing business lines. Customer adoption of new product offerings, like Compute@Edge, and further cross-sell of application security (Secure@Edge) will layer incremental revenue on top of this.
These factors may all combine to create a favorable set up for the stock in 2022, as price action over the last year has pushed FSLY’s valuation to the low end. I plan to keep an eye on developments and will provide updates as the situation improves.
Zscaler (ZS)
If Fastly is approaching decentralization from the vector of distributed edge compute, Zscaler started from network connectivity. They built a global, distributed system of PoPs connected by a private, software-defined network. Their global network is made up of 150 individual data centers, operated by Zscaler. The system processes over 160B transactions a day, which Zscaler claims makes it the largest security cloud. From these transactions, they generate 7B security incidents and policy enforcements every day.

All network traffic, including SSL, is inspected by the Zscaler system. They employ a sophisticated combination of human and AI/ML threat monitoring that constantly looks for unusual behavior and malicious activity. Threat patterns are then fed back into the active monitoring service, resulting in blocking or re-routing of suspicious activity. This allows Zscaler to meet requirements for Secure Access Service Edge (SASE).
The heart of this threat hunting capability is Zscaler’s ThreatLabZ, which is the embedded security research group at Zscaler. This global team includes over 100 security experts, researchers, and network engineers responsible for analyzing and eliminating threats across the Zscaler security cloud and investigating the global threat landscape.
These detection capabilities will be further enhanced by the planned acquisition of Smokescreen, which provides active defense and deception technology. The Smokescreen system sets up decoys for attackers across networks, applications and endpoints. The system then monitors for activity against these “honeypots”, knowing that it would be from nefarious users. Also, false targets cause attackers to waste time, making attack activity more costly. This all generates data to feed into Zscaler’s threat detection database.
Because of the breadth of Zscaler’s global coverage across so many enterprise customers and transactions, the Zscaler security team has a bird’s eye view to threat activity. Competitive solutions based on a perimeter defense keep network activity monitoring local to that enterprise. This misses the opportunity to “crowdsource” threat activity across the entire customer base. Because Zscaler routes all traffic through their distributed network, they can identify new threats at one customer and then update security policies for all other customers in real-time. This is similar to the benefits accrued by Crowdstrike’s Falcon Platform and their Threat Graph, with its visibility into trillions of events collected from agents running on millions of endpoints.
Zscaler highlights 5 capabilities that make their offering unique:
- Built for the Cloud. Legacy security providers (including Palo Alto) started with hardware products physically installed in corporate networks and data centers. Only recently have they started trying to layer on a distributed network. Zscaler built their global, distributed network of PoPs as their first step.
- In-transit Edge Cloud. Zscaler’s network configuration is software defined and updated on demand. Traffic can be dynamically routed through optimized paths from any node to any other location.
- SSL Inspection at Scale. All network traffic can be decrypted for full visibility into threat activity. This occurs at every entry point, not backhauled to central processing locations for inspection.
- Zero Trust Network Architecture. Every request to transit the network is authenticated individually. This permission only lasts for the duration of that point-to-point connection and cannot be extended to other resources.
- Operational Excellence. As enterprises are entrusting their full payload of network traffic to Zscaler, their expectations for uptime are extreme. Zscaler’s SLA for availability is 99.999% uptime.
From their Zero Trust Exchange Platform, Zscaler delivers four primary product offerings.

- Zscaler Internet Access (ZIA). ZIA provides customers with a secure Internet gateway that is cloud delivered. This allows enterprise users to connect to the Internet and use web applications from a global, fast and secure network. By providing network onramps from 150 locations, ZIA can ensure a local experience and optimized access to users anywhere.
- Zscaler Private Access (ZPA). ZPA flips to the other side and protects the applications that enterprise users frequently access. These can be third-party SaaS or internal corporate apps. ZPA is a cloud service that provides seamless, Zero Trust access to private applications running on public cloud or within the data center. These applications are never exposed to the Internet with public IP addresses, providing the additional benefit that hackers cannot scan for them or initiate a DDOS attack. By connecting a user only to each application individually, ZPA prevents the ability for hackers to employ lateral movement techniques after authenticating to the corporate network.
- Zscaler Cloud Protection (ZCP). ZCP is a newer offering that leverages capabilities that were built as part of ZIA/ZPA and applies them towards the protection of cloud workloads. It does this by automatically addressing security gaps, minimizing the attack surface and eliminating lateral threat movement. With 3,000+ pre-built security policies and 16 compliance frameworks, it quickly identifies and remediates application misconfigurations in IaaS, PaaS, and Microsoft 365. It also uses ZPA to keep cloud instances private and facilitate direct user connection to them. For app-to-app connections (either micro-services or machine-to-machine coordination), ZCP offers Zscaler Cloud Connector. Lateral movement is prevented by Zscaler Workload Segmentation, which further subdivides a cloud workload into smaller segments each of which gets a Zero Trust model.
- Zscaler Digital Experience (ZDX). ZDX is a tool for system administrators at enterprises that allows them to monitor the overall performance of the network, troubleshoot connectivity issues for individual users and scan for unusual activity. This monitoring leverages the software agent on every user device and Zscaler’s network traffic inspection. This provide ZDX with broad visibility across the user experience, including end-user device performance, network cloud path and application performance.
These all combine to deliver a unique set of solutions for enterprises to manage secure connectivity for their distributed users and applications through a decentralized network. Recent product additions to protect cloud workloads and machine-to-machine communication open up a much broader market opportunity, as Internet traffic moves beyond human interaction to automated machine coordination, whether IoT, AI-driven software agents or Industry 4.0 initiatives.
Competitive Positioning
Zscaler has a very favorable competitive position. There are few companies that that can match their breadth of network services on such a large scale. Legacy hardware vendors have tried to rapidly catch up through shortcuts, such as creating virtualized versions of their hardware solutions on the cloud or stringing together different technologies through acquisitions. To spin up a distributed network of PoPs, they layer software services on top of hardware and network infrastructure provided by the hyperscalers.
These approaches were taken by Palo Alto Networks in creating their SASE offering Prisma Access. A recent article from TechTarget highlights the underlying architectural limitations of that approach. These really boil down to the inherent advantages in controlling all layers of the network stack and having a single multi-tenant processing engine in every PoP.
Palo Alto’s biggest problem, though, is it’s not a true cloud service. Instead of a single, multi-tenant, cloud-native processing engine, Palo Alto processes packets and security in separate appliances: Virtual firewall instances in the cloud handle security enforcement; SD-WAN devices handle traffic routing and processing. With separate appliances handling traffic inspection and processing, Palo Alto SASE is only marginally different than what we’ve always done — deploy and integrate different appliances. It also means latency grows, as packets must pass through each function serially.
The pros and cons of Palo Alto Networks’ SASE platform, TechTarget
Palo Alto also lacks a private network backbone between its PoPs, which are built on top of third-party cloud platforms from AWS and GCP. This limits their control over network routing and geographic proximity to population clusters. Also, most PoPs are merely connection points for customers to the network. Network traffic processing is often backhauled to another location for deep inspection.
By running their own hardware and data centers, Zscaler is able to fully customize how network traffic is inspected, routed and blocked. They can apply this traffic inspection at the network entry point, reducing latency. Finally, all network traffic processing and security enforcement is performed in a single, multi-tenant environment.

Gartner recognizes these advantages, and consistently places Zscaler in the most favorable position in their Magic Quadrant for Secure Web Gateway (SWG). In fact, in the most recent report, Zscaler was the only vendor placed in the Leaders category. This is very unusual, as most other technology categories include at least a couple of vendors as Leaders. While SWG can sound like a limited label, it includes Zero Trust Network Access, CASB, Firewall as a Service and Remote Browser Isolation.
Quarterly Results
On May 25th, Zscaler released their Q3 FY2021 results. The market reacted favorably to this report, pushing ZS stock up 12.4% the next day. Since then, the stock has increased almost 30% above the pre-earnings price. Zscaler is benefiting from a strong demand environment and performance far exceeded what analysts had modeled. Revenue growth is accelerating, increasing 60% in Q3, up from 55% in Q2. The Q3 revenue performance even beat my optimistic target for 57% growth. For Q4, they raised the revenue estimate to represent 47.7% growth, significantly beating the analyst consensus for 38.4%. If we assume the same level of outperformance for Q4, Zscaler could match Q3’s 60% revenue growth. Calculated billings grew 71% as well, further supporting the case for high revenue growth going forward.
The bottom line showed further leverage improvement. Non-GAAP gross margin hit 81%, up slightly from last year. Income from operations more than doubled year/year, for an operating margin of 13%. Free cash flow surged to nearly $56M for a FCF margin of 32%, up from 8% a year ago. Zscaler doesn’t regularly report customer counts, but they did highlight serving over one-fourth of the Global 2000. They also mentioned closing a record number of 7-figure ACV deals this quarter. DBNER was 126% in Q3, up from 119% last year and roughly inline with Q2’s 127%. Management did discuss how large initial customer lands and short term upsells are limiting DBNER somewhat.
Zscaler revealed some significant long-term growth opportunities at their Analyst Day back in January. They are targeting 200M users and 100M workloads to protect. Currently, they serve about 20M users. This provides a long runway of growth. Additionally, they believe they can reach an ARPU of $145 per user through the combination of their ZIA, ZPA and ZDX products. They estimate the serviceable market at $72B. Zscaler leadership also highlighted their strong relationship with Crowdstrike, enhanced at the product level with an API integration to share activity and threat data between systems.
I was pleased with Zscaler’s results and think they provide another reliable bet on the cybersecurity market. I like the consistent execution, both in revenue growth and improving profitability. Zscaler has established strength and competitive advantage in their segment of the security ecosystem and is benefiting from the visibility of the Crowdstrike partnership and public mentions. My primary watch-out is in customer growth, which Zscaler needs to lean into heavily in order to maintain continued revenue outperformance. They have discussed expansion into enterprises with >2k employees as a new expansion opportunity.
Partnerships
Zscaler has formed strong partnerships with other security providers. These span both go-to-market and technology integrations. The advantage to Zscaler is two-fold. First, as partner company sales teams are engaging with their customers, they are giving Zscaler more visibility and exposing them to additional deals without marketing expense. Second, integrations between Zscaler’s network and other security offerings, like endpoint protection, improve threat detection and make the entire platform more secure for customers.
The most notable partnership is with Crowdstrike, which was highlighted by Crowdstrike’s CEO on their Q1 earnings call. The two companies have an integration to share telemetry data and threat detection through API interfaces. As an example, this allows the Crowdstrike Falcon platform to identify a user device that has been compromised and send that device information to Zscaler, which can then cut off its network connectivity.

The two companies both commented about deals that the other initiated on their recent earnings calls. These included an insurance company that Zscaler pulled Crowdstrike into and an investment bank that Crowdstrike introduced to Zscaler. In fact, Zscaler just named CrowdStrike as their 2021 Go-to-Market Technology Partner of the Year at their ZenithLive Summit.
I think thematically, it’s customers are looking for a next-gen endpoint workload technology platform like CrowdStrike combined with next-gen network technology, and they’re looking to replace their legacy Palo Alto Networks — or others. And we spent a lot of time in the field, and we’ve set up compensation structures between the two organizations, where both sales teams are incented to help each other out, which is always good in the field.
And we’ve done the integration. So when we think about understanding what happens on the network, obviously, we’re not a network company. That information can be supplied to us in the Falcon platform. And we’ve got tremendous visibility on the endpoints that go beyond anything a network company could have and that’s useful to Zscaler customers.
So when you put the two of them together, we think it’s better together. And we’ve got a huge hotel company that uses both Zscaler and CrowdStrike, and it has just been amazing to see the technologies work together. And they’ve been a big fan and a big proponent of us putting these integrations together. So I think it’s good for customers and it’s good for both parties.
Crowdstrike CEO, Crowdstrike Q1 FY2022 Earnings CAll
Zscaler also has deep relationships with the hyperscalers and other technology vendors, including AWS and Microsoft. At ZenithLive 2021, which just wrapped up, Microsoft’s Corporate Vice President of Product Management was one of the Keynote speakers. He discussed how Microsoft is partnering with Zscaler to “enable the future of Zero Trust for the cloud-first enterprise”. Zscaler also has partnerships with Google, Cisco and VMware.

These kinds of partnerships are important for investors to appreciate, as they provide a view into the competitive dynamic. If a company considered Zscaler as a competitor, they would be less likely to cross-sell their service as part of an overall offering. We can also read a lot into which partners leading companies highlight. Given that Crowdstrike is the undisputed leader in endpoint protection, having them call out their partnership with Zscaler on an earnings call is a strong validation of Zscaler’s position in the market.
Zscaler Take-Aways
Zscaler leadership estimates their serviceable addressable market to be $72B. This is based on data from IDC reports for network security spend through 2022. This estimate represents the combination of user protection ($45B) and workload protection ($23B). Given that Zscaler’s current annual revenue run rate is about $700M, they have plenty of room to grow. This also doesn’t take into account some future opportunities, particularly the full spectrum of machine-to-machine communications.

A more concrete KPI is Zscaler’s target to increase their coverage to 200M users and 100M workloads connected to their network. This was revealed at Analyst Day in January. This target would represent a 10x increase in users and many more times that for workloads, as workload protection is a newer product.

Zscaler’s revenue growth toward their SAM will be driven by two contributors. First, they will expand usage by adding more users and workloads to the platform. Second, enterprise customers will increase their spend per user or workload by adopting add-on services. This generates a target of $145 per user and $155 per workload. Current average spend per user is in the mid-$20 range, providing a 6x upsell opportunity.

Of the decentralization trends we discussed earlier, Zscaler is laser focused on the transition to distributed, point-to-point networks. They do not offer products for application development, like an edge compute or distributed data storage. Their workload protection service (ZCP) would be relevant for securing edge compute workloads. Similarly, IoT devices and machine-to-machine communications will need secure network access, which also offers an opportunity for Zscaler.
Distributed identity might be an interesting area for future expansion. Currently, Zscaler partners with major centralized identity providers, like MS Azure Active Directory, Okta and Ping. As decentralized identity (DIDs) solutions become mainstream, Zscaler would be in a favorable position to enable support for the technology to their customers and provide services to support components like Identity Hubs and Universal Resolvers.
Additionally, the implications for ZDX are favorable. An aspect of ZDX is application performance monitoring, as well as user device performance. Given Zscaler’s visibility across users, devices, the network and applications, there are likely opportunities in aspects of observability.
Probably the easiest gauge of Zscaler’s continued growth momentum is a chart shared at Analyst Day. Management revealed that daily transaction volumes on the network have roughly doubled every 20 months since 2014. The volume of transactions is a reasonable proxy for revenue growth, implying their rapid growth trajectory should continue.
Overall, I like Zscaler for their leadership position on the network connectivity side of Zero Trust and SASE. This provides a strong strategic foundation on which to grow. They have been demonstrating consistent business execution, with strong quarterly results that include accelerating revenue growth and customer adoption. They project a large SAM and have a strategic plan with tangible KPIs and products in market to capture a large share of that.
Based on their performance so far this year and future potential, I have a 12% allocation to ZS in my personal portfolio. While their valuation is high, I think revenue growth is sustainable at current rates given Zscaler’s prime competitive position, product strategy and the favorable demand environment. The partnership with Crowdstrike further cements their position as a leader in network security.
I am also adding ZS to my coverage list and setting a 2024 price target of $635. This assumes revenue of $670M for FY2021 (55% year/year growth), increasing to $2.175B for FY2024 (exit rate of 45%). Target P/S in 2024 is 40 (versus 50 now), yielding a target market cap of $87B. This represents growth of 2.8X over current valuation for a 2024 estimated price of about $635.
Cloudflare (NET)
Of the independent software infrastructure providers discussed, Cloudflare is probably in the best position to address the new trends driven by decentralization. This is because they have products in market to serve all three of the main thrusts of infrastructure decentralization – Zero Trust / SASE based network architecture, serverless multi-tenant edge compute and distributed data storage. All these capabilities were built in-house and are rapidly expanding through a breakneck product release cadence.
At Cloudflare’s core is a distributed network of PoPs with a presence in all major countries. They support Zero Trust connectivity for enterprises with multiple methods for onboarding employees, office locations and data centers. PoPs with concentrated, hand-tuned resource configurations provide distributed, serverless compute environments. They offer several methods for distributed data storage, based on desired consistency levels, which also accommodate data residency controls if needed. All of this is overlaid with advanced security monitoring, threat detection, network traffic protection and full packet inspection.
Cloudflare’s mission is to “help build a better Internet”. This is purposely broad, allowing Cloudflare to address multiple market segments. This is grounded in a view that the “Network is the computer“, which recognizes that the Internet’s power comes from the connection of many people and devices over secure channels. When asked about competition on the most recent earnings call, Cloudflare’s CEO didn’t point to other network, security or content delivery providers, but rather AWS. I think this is telling and reflects the large market opportunity Cloudflare plans to address.

I will review Cloudflare’s primary product offerings and recent developments as it relates to decentralized opportunities. I won’t cover everything Cloudflare does, but will discuss what I think are the most relevant offerings and new announcements for this year. For more in depth commentary on Cloudflare, readers can reference some of my past blog posts. Peer analyst site Hhhypergrowth also offers in-depth coverage of Cloudflare.
Distributed Network Services and Zero Trust
Cloudflare operates on a distributed network of over 200 PoPs in proximity to population centers that span more than 100 countries. These are connected by a private network with software defined routing. Each PoP includes significant compute power with which they can perform full packet inspection. Enterprises can easily connect their corporate network, data centers and employees to the Cloudflare network. The whole system is overlaid with advanced security monitoring.

They continue to grow their network, adding new PoP locations and compute power continuously. In fact, Cloudflare published a mid-year update on their blog highlighting the 10 new cities and 4 additional countries added to the network in 2021 so far. They have doubled their computational footprint since pandemic lockdowns started (a little over a year ago). Cloudflare’s network ensures that they have a PoP located within 50ms of 99% of Internet users.
They also made it even easier for enterprises to directly connect their networks to the Cloudflare network through new partnerships with data center providers. This provides a Layer 2 interconnect from over 1,600 locations worldwide. This extends the network reach of Cloudflare’s PoPs to each enterprise’s physical network or data center installation.
Their Zero Trust offering for enterprises looking to connect employees, offices and data centers to a secure network is Cloudflare One. This was introduced in October 2020 as part of a week long binge of product releases called Zero Trust Week. This followed two other release weeks in the prior 3 months, reflecting an almost unbelievable pace of product development.

Cloudflare One provides a unified set of tools to enable a Zero Trust security posture for customers. It delivers a cloud-based, network-as-a-service to protect enterprise devices, data and employees. While this represented some packaging of existing SASE products like Access, Gateway and Magic Transit, it also adds browser isolation, a next-gen firewall and intrusion detection. Cloudflare One is the umbrella product offering, and these other tools roll into it. The product release announcement included quotes from a number of customers, like JetBlue, OneTrust, Discord and INSEAD. This product continues to drive new enterprise wins in subsequent quarters.
In order to round out the Zero Trust capabilities of the platform, Cloudflare announced partnerships with leading providers in identity management and endpoint protection. Cloudflare allows customers to preserve their existing identify management tools, with integrations between Cloudflare One and providers like Okta, Ping Identity, and OneLogin. Similarly, for device security (endpoint protection), Cloudflare has partnered with CrowdStrike, VMware Carbon Black, SentinelOne and Tanium. Cloudflare One also works across different identity providers, which provides an interesting capability that might enable future extensions.
In the past few months, Cloudflare added more support for private networks. Private networks allow a customer to hide IP address ranges and only expose resources to designated clients. Using a private network, an enterprise can remove public network access to their internal software applications. Only employees with the appropriate client app and permissions will be routed to the obfuscated application. This capability also supports non-HTTP traffic, which was a constraint previously. Cloudflare’s new support for private networks is similar to Zscaler’s ZPA offering.

For customers that still want some control over traffic flowing across their network, Cloudflare introduced Magic Firewall. This provides a network-defined firewall for an enterprise to secure users, offices and data centers. Like a typical hardware firewall, users can specify allow/block rules based on IP, port, protocol, packet length, etc. This is integrated with Cloudflare One making these capabilities automatically available.
To protect employee browsing activity, Cloudflare offers Browser Isolation. This product addresses the risk that a script downloaded from an infected web site might introduce a vulnerability into a user’s device. To prevent this, Cloudflare actually runs a copy of the user’s browser in a sandboxed environment on one of Cloudflare’s distributed data centers. The results are then streamed to the user’s local browser instance as a set of draw commands to render the page. This prevents the user’s browser from actually running any code. If a vulnerability is encountered, it only installs on the sandboxed version of the browser, which is then destroyed in the cloud.
Cloudflare One provides visibility into network activity with its Intrusion Detection System (IDS). The IDS product is a natural extension of the visibility enabled by Cloudflare One. Once a customer has connected their employees, devices and data centers to Cloudflare’s network, Cloudflare can actively inspect that traffic for threats. This takes the form of traffic shaping and traffic inspection. Shaping observes normal, expected behaviors and flags anything unusual, like a particular user accessing many resources in rapid sequence. Traffic inspection involves examining each user request for something malicious, revealing a targeted attack. For both types of detection, IDS can alert security personnel or take proactive action, like blocking a user’s source IP address.
Finally, to formally bring secure access to the network edge (SASE), Cloudflare launched their Magic WAN with Magic Firewall integrated into it. Magic WAN provides secure, performant connectivity and routing for all components of a typical corporate network, including data centers, offices, user devices, etc. This can be managed as a single SaaS based solution. Magic Firewall integrates with Magic WAN, enabling administrators to enforce network firewall policies at the edge, across traffic from any entity within the network.

Beyond the improvement in security and simplicity, customers who connect their network to Cloudflare through Magic WAN can realize significant cost savings by ditching their MPLS connections. Typically, a corporation would connect offices to regional data centers using MPLS over leased lines. Each data center would have leased line connectivity to at least one other data center. These data centers would host corporate applications and a stack of hardware boxes to keep them secure. Enterprises that migrate some of their corporate applications to the cloud would also typically establish connections from their data centers to the cloud providers directly to boost security and performance.

Magic WAN allows all of this overhead to be replaced by Cloudflare’s single global anycast network. This provides significant benefits to the enterprise. Geographic growth (acquisitions, international expansion) isn’t constrained by long lead times for leased MPLS connections. Employees no longer experience latency accessing applications, as traffic can be routed directly versus being backhauled to a central location for inspection. These capabilities bring Cloudflare more closely aligned with Zscaler’s SASE platform and product offerings (ZIA, ZPA).
Distributed Application Runtime Environment
Because their PoPs included heavy compute capabilities for traffic inspection, Cloudflare decided to leverage that capacity to provide a distributed compute environment. Their architecture is serverless and multi-tenant, allowing developers to locate software services on the network edge.
Cloudflare offers edge compute through their Workers product. This has been available to customers since early 2018. Workers provides a distributed runtime that executes developer code in parallel across Cloudflare’s network of over 200 POPs spread across 100 countries. Cloudflare built their solution on the Chromium V8 Engine. This allowed them to leverage the work already done by the Google Chrome team and get a product to market quickly in 2018.
With Workers, developers can create code modules that run on request or scheduled via a cron service within their distributed serverless environment. Due to its foundation on the V8 Engine, Workers can run JavaScript, along with a plethora of other popular languages that can be complied to JavaScript. Workers provides developers with tooling to write, test and deploy their serverless functions. To monitor execution of Worker code in the production runtime, Cloudflare supports an integration with several leading observability providers.
One noteworthy difference with Cloudflare’s serverless implementation is the release of Workers Unbound. This extends the allowed execution time for Workers request processing from 50ms to 30 seconds. This provides developers with the ability to address long running jobs on the Workers platform, like for data analysis or ML/AI workloads.
The day before Workers Unbound was launched to GA, Cloudflare also announced support for AI at the edge powered by Nvidia GPUs and TensorFlow. This will allow developers to build AI-based applications that run across the Cloudflare network using pre-built or custom models for inference. By distributing the models on Cloudflare PoPs, developers get the benefit of security of their models and proximity to the consumer of the model. By leveraging the TensorFlow platform, developers can use familiar tools to build and test machine learning models, and then deploy them globally onto Cloudflare’s edge network.
Adoption of Workers has been strong. On the Q4 earnings call, Cloudflare’s CEO announced that more than 50,000 developers wrote and deployed their first Cloudflare Worker in the quarter, up from 27,000 in Q3. Cloudflare has been rapidly adding features to the Workers offering, hosting a stand-alone Serverless Week in late July 2020 and launching a new data storage engine Durable Objects in early October.
Workers is also building adoption amongst enterprise customers. In the last two earnings calls, Cloudflare management highlighted several new customer adds. They also provided some actual customer use cases for Workers during Developer Week in April.
- Invitae: Runs genomics analysis with Workers Unbound and Workers KV. As an example, their engineering team built an API that simulates DNA sequencing data.
- Doordash: Uses Cloudflare Pages to host their marketing sites. They value the savings in CI/CD overhead and integration with the rest of the Cloudflare platform.
- Thomson Reuters: Used Workers Unbound and Workers KV to build EverCache, a cache implementation designed to improve efficiency and load times across thousands of their partner websites.
- National Instruments: Applies Workers to several use cases for scaling and tuning ni.com. Initially, they used Workers for redirects, and then began applying Workers Unbound for other features such as detecting the location of users and adjusting the experience. Currently, they are improving routing, image optimization and page caching.
What is most telling about the versatility of Workers is Cloudflare’s own commitment to build new software services on top of their distributed network using their Workers platform as the software toolkit. Not only does this represent “dog fooding” their own technology, but provides validation that Workers can handle difficult application use cases and processing loads. For example, Cloudflare’s development team built Browser VNC, Waiting Room and AMP Optimizer using the Workers development environment and runtime.
The Cloudflare team has been exploring more use cases for Workers in particular verticals, like gaming. They built a sample real-time, multi-player game on top of the Workers platform. The Client app is run using Cloudflare Pages and leverages WebSockets support to handle the client-server connections for data updates. They distribute each user’s location information in Durable Objects. This provides a useful example of a use case for gaming, which is arguably a complicated application to build. They even ported an open source version of Doom to the platform and run the server-side code in WebAssembly.
As we think about implications for distributed edge compute, it’s worth doing a brief comparison of the edge compute solutions fielded thus far between Cloudflare and Fastly. Fastly’s Compute@Edge is optimized for performance. It has the fastest cold start time and smallest memory footprint. This comes at a cost though in language support, which is currently limited to a handful of specialized languages that can be compiled to WebAssembly.
Cloudflare’s Workers are geared for versatility. They chose to re-use the V8 Engine, which allowed an earlier production launch. Due to this choice, Workers supports most popular developer languages, including JavaScript. They have extended runtimes with Workers Unbound and are supporting AI model inference through the partnership with Nvidia.
As I mentioned earlier, Fastly needs to add more distributed data storage capabilities to the Compute@Edge platform. Otherwise, their solution risks being relegated to a handful of stateless use cases. As I will discuss next, Cloudflare has been advancing quickly to add multiple options for data storage, including third-party partnerships. Additionally, they have rolled out meaningful solutions to address data residency requirements.
Distributed Data Storage
Cloudflare’s solutions for data storage have been advancing rapidly. After Workers launched in 2017, Cloudflare soon added a distributed, eventually consistent, key-value store with Workers KV. This allows developers to store billions of key-value pairs and read them with low latency anywhere in the world. Each key can hold up to 2MB of data and developers can create an unlimited number of keys.
However, there are limitations. Challenges with managing any distributed data store are well understood and encapsulated in the Cap Theorem. Without getting too technical, this basically stipulates that a distributed data storage system can be optimized for two of three design goals – availability, resiliency (partition tolerance) and consistency.

For Workers KV, Cloudflare chose to optimize for high availability and resilience. This ensured that developers could expect data values to be highly available with low latency. Workers KV yields 12ms response times on average, which is very fast. Data distribution is resilient to PoP or network outages.
The trade-off is in consistency. This means that multiple requests for the same key value from different locations at the same time might generate different results. This might be problematic for a use case that involves high volume bursts for a shared data value, like tickets to an event. Update distribution is still pretty good – with global consistency typically achieved within 60 seconds.
With ultra-fast reads and high availability, Workers KV is suitable for a number of use cases. These primarily revolve around functionality in which a data value is updated infrequently but read very frequently. On the other hand, for use cases where the same key value is updated frequently, shared with many other locations and accuracy is important (like an account balance), then another data storage approach is needed.
This limitation to consistency was addressed with the introduction of Durable Objects in September 2020. Durable Objects takes Workers KV a step further, by allowing any set of data to be persisted with guaranteed consistency across requests. Objects can be shared between multiple application clients (users). This consistent and sharable data object storage enables many common use cases for multi-user Internet applications, like chat, collaboration, document sharing, gaming, social feeds, etc.
A Durable Object is defined by a JavaScript class and an ID. There is only ever one instance of a Durable Object with a given ID running anywhere in the world. All Workers making requests to the Durable Object with that ID are routed to the same instance – letting them coordinate across multiple requests. The Durable Object instance can then make requests to downstream APIs or write data to permanent storage through a storage API.

By emphasizing consistency, Durable Objects sits at the opposite end of the CAP Theorem spectrum from Workers KV. Durable Objects are well-suited to workloads requiring transactional guarantees and immediate consistency. However, since transactions from multiple parties must be coordinated into a single location, clients on the opposite sides of the globe from that location will experience moderate latency. Cloudflare has discussed a future enhancement to mitigate this latency by dynamically auto-migrating Durable Objects to live close to where they are used.
An additional advantage of Durable Objects is in their design. As the name implies, they are implemented by Cloudflare like a software object, as in object-oriented programming. This distinction is subtle but important. As an object, Durable Objects capture not just state but also code. The implementation is a software class, with setter/getter methods in which logic can be applied. The state can be cached locally and also written to a durable store. This implementation allows the Durable Object to do more than just store state. It can also coordinate between requests, enforce conditionals, add loops, etc.
This is a very powerful abstraction and has future implications, where Durable Objects (or some future form) could be assembled or coordinated into a broader data store. Cloudflare has implied that this provides the foundation for a future abstraction that resembles something like a distributed database, which would support queries across multiple objects. In many ways, this combination of state and executable code resembles a smart contract, and could even support composability with an enhanced permissions model.
Acknowledging that their own data storage solutions may not meet all use cases and that some developers have already made use of third-party distributed data storage solutions, Cloudflare announced in April new partnerships with two major distributed data companies, Macrometa and Fauna. This makes clear Cloudflare’s intent to provide developers with many options for data storage and represents another step towards unlocking a broader set of edge compute use cases by providing both code runtimes and state systems.
Macrometa provides a fast, globally replicated NoSQL database, implemented as a document store. On top of this, they expose integrated data services for search, pub/sub and stream processing. Data requests are directed to the closest Mecrometa data center. Writes are replicated globally with configurable consistency options. Performance is pretty good, with Cloudflare reporting end-to-end latency for a database request from an edge client of 75ms or less for 99% of requests.
The other database partner, Fauna, provides serverless, multi-region, transactional database instances that are accessible via a cloud API. The data access API accommodates relational and document-centric querying. It supports business logic and an interface of GraphQL. Like Macrometa, Fauna provides strong consistency for a full range of data types with reasonably low latency and high availability.
Both of these partnerships enable the creation of full-featured web applications, like a complete e-commerce store. The difference from Workers KV and Durable Objects is that queries across multiple data values is feasible with reasonable performance. An example for e-commerce might be to return a list of all the products of a category type, like sci-fi books in an online bookstore. With Workers KV or Durable Objects, this type of query would require a brute force scan of all objects or keys. Cloudflare has indicated that this type of filtering meta layer may be added to Durable Objects in the future.
Identity and Privacy
To help customers address data residency requirements, Cloudflare introduced Jurisdictional Restrictions for Durable Objects in December. This enhancement significantly reduces the overhead for developers to keep customer data local to a particular geographic boundary when required. They can create rules to ensure that Durable Objects only store and process data in a particular geographic region. This way, they can easily comply with a country’s current data residency regulations and quickly adopt to new ones that may be passed in the future.
This constraint is easy for the developer to introduce. They simply pass in an additional parameter of “jurisdiction” when instantiating a Durable Object. An example might be “EU”. This defines the set of Cloudflare PoPs into which the Durable Objects data can be located or accessed. There are no additional servers to spin up or separate database copies to maintain.
For identity, Cloudflare doesn’t formally offer an identity service and partners with the major identity providers like Okta, Ping, Onelogin and Microsoft AD. However, given their coverage across the network, data and compute, I wouldn’t be surprised if they began supporting aspects of decentralized identity management. Particularly if DID models gain adoption, Cloudflare could extend their service offerings to support shared services like Identity Hubs or Universal Resolvers. Similar to Microsoft, they could provide services to help application developers leverage the DID ecosystem.
Quarterly Results
After reporting earnings on May 6th, Cloudflare’s results garnered a moderately positive response from the market, gaining about 3.7%. In Q1, Cloudflare grew revenue by 51% annually, beating analyst estimates for 43.6% growth and up slightly from 50% in Q4. Sequentially, Q1 revenue increased 9.7% over Q4, roughly inline with that quarter’s 10.2% sequential growth. Looking forward, Cloudflare leadership raised their Q2 revenue target to 46.4% growth at the midpoint, increasing it by 7% over analyst estimates for 39.4% growth. If we apply the Q1 beat of about 8% to Q2, it implies over 54% annualized growth, which would represent further acceleration. For the full year, management raised the revenue estimate by 5% to 42.4% annual growth.
Customer engagement metrics support this optimistic view. Total paying customers grew to 119.2k, up 8.2k from 111k in Q4. This represents 33.6% annualized and 7.4% sequential growth, inline with Q4’s 32% year/year growth and slightly down from 10% sequential growth. Customer spend expansion as measured by DBNER jumped to a record of 123%, up 6% from 117% in Q1 2020 and 119% in Q4. This is an impressive trajectory, reflecting increased customer spend on existing products and expansion into some of the newer ones, like Cloudflare One. Large customer growth (spending over $100k ARR) was strong as well, with 120 new large customers in Q1. Large customer count is up 70% over Q1 2020 and 14% sequentially over Q4. Large customers now contribute more than 50% of total revenue.
While Cloudflare shows consistent revenue growth, it is also improving operating leverage. Non-GAAP gross margin was roughly inline with Q4 and Q1 2020 at about 78%. Non-GAAP operating margin improved substantially year/year from -16% in Q1 2020 to -5% this past quarter. Cloudflare management also confirmed their long term target for greater than 20% operating margin. Operating cash flow increased to $23.5M for 17% margin in Q1, up from ($14.3M) or -16% margin a year ago. These results reinforce Cloudflare’s consistent, repeatable growth model.
Cloudflare Take-Aways
Given Cloudflare’s vision and broad product offering, they have set the largest TAM of the decentralized providers discussed. Addressing a TAM estimated at over $100B by 2024 with a run rate of about $600M currently, Cloudflare has a lot of expansion opportunity. With their rapid product release cadence and consistent execution, I could see them increasing revenue by 50+% for several years.

The release of Cloudflare One in 2020 significantly increased the size of their TAM, by exposing them to enterprise network spend on Zero Trust and SASE. Magic WAN also allows Cloudflare to replace expensive enterprise spend on private MPLS circuits, offering both a cost savings and performance boost. High demand for Zero Trust and SASE services over the next 3 years will drive their TAM over $100B.
Interestingly, their market projections don’t include estimates for distributed compute or data storage. Cloudflare has active customers on their Workers product offering, but isn’t comfortable projecting the potential market size at this point. That is likely a fair assessment, as use cases are still emerging for edge compute. For now, Cloudflare views the Workers platform as an enabler of software services that layer on top of their distributed network. This forces the internal development team to continue to improve the product functionality, in parallel to customer adoption.
One of Cloudflare’s biggest advantages is their enormous customer base, which includes a large set of non-paying users. This total grew to over 4.1M in Q1, up from 3.5M in Q4 and 2.8M in the prior year (growth of 46% y/y). With just 3% of total customers paying, there is a lot of room for upsell. Additionally, Cloudflare’s rapid product release cadence is facilitated by leveraging the free user base as beta testers for new products. By monitoring the activities of this large set of Internet users and developers, Cloudflare’s product team gains a direct view into new market developments and product opportunities.
For these reasons, I am happy with my roughly 20% allocation to NET in my personal portfolio and don’t plan to change this. With product offerings aligned towards all vectors of decentralization, Cloudflare is in an optimal position to benefit from multiple secular tailwinds. The valuation multiple is very high, which will require consistent outstanding performance going forward. Analysts have modeled revenue growth for 2022 and 2023 of about 30%, which I think Cloudflare will significantly outperform.
Hyperscalers
Decentralization effects are certainly on the radar of the hyperscalers. It would be naive to assume they will sit idly in their central clouds and ignore new market opportunities. Of the effects I have discussed, the hyperscalers appear most focused on extending their central compute and data storage solutions to address use cases closer to their customers. These are primarily falling under the label of edge compute.
Besides facilitating some aspects of Zero Trust, through authentication systems, the hyperscalers are largely staying out of private networks for enterprise connectivity (SASE). As discussed earlier with Zscaler, they are partnering with these network providers to enable enterprises to migrate to SASE and Zero Trust. This avoidance makes sense as their anchor is in cloud compute, with connectivity as a by-product.
For edge compute, the emergence of new high-bandwidth wireless networks, like 5G, coupled with IoT and automation are driving a significant upgrade of traditional manufacturing and industrial processes. This movement is dubbed Industry 4.0, or the fourth industrial revolution. It centers on integration of industrial systems for increased automation, improved communication and self-monitoring. It involves the production of smart machines that can make decisions and diagnose issues without the need for human intervention.
These Industry 4.0 principles can be applied to any function where tighter monitoring, communication and coordination between individual components would yield greater efficiency or productivity for the process as a whole. While vague, this could be applied to many industrial processes – manufacturing centers, distribution hubs, hospitals, buildings, transportation centers, etc. Generally, the scope is constrained to a small geographic boundary, where a local wireless network could reach clusters of IoT enabled devices.
Coordinating these systems requires a large amount of compute to perform data processing, apply control algorithms and facilitate communication. Because the volume of data creates opportunities for optimization and prediction, AI and ML techniques can be leveraged to improve the performance of the overall system. This is creating a large opportunity for AI technology vendors, like Nvidia, to add their solutions to the technology stack.
Enabling Industry 4.0 use cases appears to be where a lot of the focus of hyperscalers is directed. The term edge compute is becoming a catch-all, including the process of co-locating cloud-like processing resources close to industrial centers. These resources are often connected to local high-bandwidth wireless networks along with smart devices and sensors within the industrial complex.
These efforts largely involve duplicating the same resources available in central cloud data centers. We can generally think of this like a private data center in a box. The infrastructure is largely designed to be single tenant, which dramatically simplifies requirements for runtime invocation, data storage and security. This strategy from the hyperscalers makes perfect sense as it will be easy to scale, drive heavy resource consumption and leverages existing technologies from central data centers.
While labeled as edge compute, this single tenant, single location approach to distributed computing is different from the multi-tenant, multiple entry point computing environments being offered by Cloudflare and Fastly. Multi-tenant, multi-entry edge computing requires a fundamentally different architecture, which is well aligned with the software-defined network of global PoPs already built by both providers.
The runtime environment to support multi-tenancy has to be radically different as well. It must be stripped down into isolated processing threads with no shared resources between invocations. This is a requirement for security and resource utilization. Multi-tenancy duplicated across hundreds of PoPs can only scale if the compute and memory footprint of the runtime is minimized. This requirement eliminates the feasibility of containers or other virtualized environments, which are largely the basis of the hyperscaler edge compute solutions.
The same simplifications apply to data storage. A single-tenant, single location data store can be easily implemented with existing database solutions. Data can even be pushed to other locations through replication. However, multi-tenant, fully distributed data stores introduce new design considerations for consistency and performance. This explains why Cloudflare and Fastly couldn’t set up conventional database systems in all their PoPs.
This isn’t to say that one approach will be more commercially successful than another. The market opportunity to power the fourth industrial revolution is enormous. This explains why every technology vendor seems to be tripping over themselves to partner with wireless network providers to offer edge compute on 5G. They want to power smart factories, airports, universities, hospitals, power plants, buildings, etc.
However, this isn’t the domain of multi-tenant, multi-entry edge compute providers, like Cloudflare and Fastly. They are enabling use cases where the software application has to be globally distributed and fully decentralized. These use cases are primarily the domain of consumer-oriented businesses currently, like e-commerce, media and other services for human users. However, I think that as Industry 4.0, IoT and machine-to-machine coordination really ramp up, a new software layer will emerge to service communication between these Industry 4.0 complexes.
If the hyperscalers all provide these edge compute and data services for industrial use cases, there will still be a need to serve software applications that work across these installations in a vendor-agnostic way. For example, if one factory implements AWS’ 5G edge solution and another factory uses the same from Azure, a data service that needs to communicate with machines in both installations would be better served by a cloud-neutral, multi-tenant, multi-location edge compute and data distribution solution.
This is why I think there will be an equally large opportunity to service “edge compute” workloads for the multi-tenant providers like Cloudflare and Fastly. The hyperscalers, working with telcos and wireless network providers, will likely represent the primary entry point for data and compute from industrial IoT use cases. However, any compute or data service that needs to transcend multiple locations and cross hyperscalers will be best served by edge applications and data distribution provided by the independents.
As an example, AWS Wavelength brings AWS services to the edge of the 5G network, minimizing the latency to connect to an application from a connected device. To do this, Amazon has partnered with some carriers in the U.S. to establish small data centers called Wavelength Zones within the carrier’s 5G network. Wavelength Zones offer a subset of the services available in an AWS Region. Compute is provided by EC2 instances running in containers and orchestrated by Kubernetes.

This AWS Online Tech Talk provides useful detail on Wavelength implementation and best practices. In it, they recommend running “hard to distribute” workloads and master databases in the AWS Region (of which there are 4 in the U.S.), not the local Wavelength Zone. This implies that this solution is not ideal for applications that require state consistency across multiple geographic regions. They provide an example of a gaming application, where they recommend that the gaming company determine where the gamers are located geographically and then locate game servers in Wavelength Zones nearby. They also recommend back-hauling state to the nearest AWS Region. Any serverless functions would similarly be routed back to an AWS Region to run on Lambda.
Within this configuration, AWS points out that other compute and data services would still be available to the application running in the Wavelength Zone or the 5G devices themselves from the Internet (Annotation “5” above). They reference this access for third-party developer tooling, like GitHub. Along the same lines, data services from other third-parties could be accessed through the same connection and delivered from distributed application hosting providers like Cloudflare or Fastly.
The key point is that Wavelength provides concentrated compute and cached storage close to the cluster of 5G connected devices within an industrial complex. This is very useful for single-tenant, geographically targeted workloads, like those serving a distribution facility or a sports stadium. However, for application services that need to be available synchronously from all points on the globe, this is not the solution. These might represent data services consumed by applications that run in multiple industrial complexes at once.
For example, manufacturers of the same equipment used in multiple factories might offer services designed to maximize the uptime or coordinate maintenance for their machines. Parts and supply distributors might offer data services relevant to multiple connected factories that deliver the real-time cost or availability of their inputs globally. Information about transportation bottlenecks or even weather patterns might be consumed by all the Industry 4.0 installations. Demand for these types of distributed services will emerge in parallel, as the fourth industrial revolution takes shape. The software and data that power them will be best served by a globally distributed network of multi-tenant, serverless PoPs.
With this in mind, a reasonable litmus test for success in delivering these types of multi-tenant, globally distributed application services is whether the provider previously maintained a high-performance CDN. While CDN is largely a commodity service, it emphasis the native design requirements for global distribution, multi-tenancy and performance optimization. Vendors who can support a CDN service will more easily evolve to this multi-tenant edge compute solution. This is because their architecture was designed for it from the beginning. Hyperscalers, on the other hand, were grounded in central data centers. They more naturally expand into single-tenant compute and data solutions at the edge that resemble their existing centralized compute infrastructure. Most even promote this as a feature of their edge solutions – that the same tooling and infrastructure is available at the edge as in central data centers.
Related to this, hyper-local edge compute offerings, like placing equipment in cell towers or lamp posts, will be constrained for resources to properly address high volume, global, multi-tenant use cases. There is a minimum size for a PoP that houses sufficient compute, content and data resources. Consider all the applications that consumers within a cell tower’s radius might use. Edge compute code, data and content for each application has to be duplicated at every edge location in order to be multi-tenant and globally distributed. That space would not likely be available in a lamp post.
For cell towers, which have more space, there are estimated 349k cell towers in the U.S. and 4-5M globally. It would be very costly to duplicate the compute and storage space necessary to service all applications from edge compute equipment closets located within every tower. This would argue for regional clusters of equipment to which groups of cell towers could forward application requests. However, that regional concentration is what Cloudflare, Fastly and others have already built. Fastly provided a detailed explanation for why many, micro PoPs is actually less effective for a distributed CDN. The same argument applies to edge compute and data storage. Additionally, cell tower based edge compute would lack software-defined, point-to-point network routing between locations globally.
Besides Cloudflare and Fastly, the only other CDN provider that could muster a proper distributed, multi-tenant, serverless edge compute solution is Akamai. However, they have been slow to market. They launched their EdgeWorkers product in October 2019, but it was in private beta through last year. The current solution is based on the V8 Engine and only supports JavaScript for development. They offer a basic key-value store, called EdgeKV, but no more sophisticated data storage solution that addresses strong consistency, full database functionality or data residency controls. For these reasons, their edge compute offering is behind the more advanced solutions fielded by Cloudflare and Fastly. We might see some more progress from them as Industry 4.0 ramps, but for now, I will put Akamai in the legacy provider camp.
To summarize, these are the architectural distinctions which I think make the distributed, serverless compute and data storage solutions from Cloudflare and Fastly unique:
- Multi-tenancy. Many of the new IoT or industrial solutions being rolled out by the hyperscalers and large technology providers are designed for single-tenant, local, private hosting. This provides a simpler security posture, as the security of the environment is often defined by physical boundaries. Multi-tenancy brings a different set of requirements.
- Optimized Runtime. Hyperscaler compute environments tend to rely on containers or virtual machines. This is suitable for single-tenant solutions, as threads can be kept warm for fast response. The multi-tenant environments provided by Fastly and Cloudflare contain isolated, slimmed down runtimes. They consume much less memory and compute resources, providing greater resource scalability.
- Software-defined Edge Network. The PoPs within which Cloudflare and Fastly provide distributed compute and data services are interconnected by dynamic routing software. The path for each traffic request can be determined on demand, based on optimization algorithms.
- Cloud Neutral. As hyperscalers sought to dominate all services needed by developers within their cloud environments, a backlash ensued in which CXO’s wanted to avoid “lock-in” with a particular provider. Lock-in can limit flexibility, constrain portability and reduce negotiating power. An avoidance of lock-in and a desire to leverage the best technology from each hyperscaler encouraged many enterprises to adopt a multi-cloud strategy. Additionally, some software services that power multiple Industry 4.0 locations would need to run across hyperscalers.
Nvidia
Nvidia has been making some very interesting moves this year as it relates to expanding into software services to enable ML/AI capabilities. These, of course, are built over their GPU hardware platform. One could argue that Nvidia is rapidly becoming a software company, with revenue from software services gradually increasing. They recently created their AI Launchpad program to help enterprises more easily apply AI to their businesses.
AI LaunchPad provides an end-to-end AI platform to help enterprises jumpstart their AI initiatives. AI LaunchPad delivers a suite of software services that can be layered on top of hosting infrastructure provided by industry partners. Through the combination of the two, enterprises will have access to AI services in cloud, hybrid and local environments without having to spin up their own infrastructure.
For hybrid-cloud environments, Nvidia has partnered with Equinix. This allows enterprises to take advantage of AI services in a private cloud that can be distributed across Equinix’s platform of 220 data centers. Enterprises can locate these AI services close to their manufacturing, healthcare or transportation hubs. Because of this geographic proximity to the users or devices, this brings AI services to the “edge”, albeit in a private, containerized environment.
In a similar way, Nvidia has partnered with many of the 5G providers to bring AI services closer to clusters of devices on private 5G networks. Launch partners include Fujitsu, Google Cloud, Mavenir, Radisys and Wind River. Enterprises, mobile network operators and cloud service providers that deploy the platform will be able to handle both 5G and edge AI computing in a single, converged platform. Customers could create AI applications on the platform to address use cases like precision manufacturing robots, automated guided vehicles, drones, wireless cameras or self-checkout aisles.
Specific to Google Cloud, they are extending their Anthos application platform to the network edge, allowing telecommunications service providers and enterprises to build new services and applications at the 5G edge. Enterprises can leverage this for IoT use cases within their private 5G networks covering geographically bound areas. The partnership with Nvidia then layers AI processing capabilities over Anthos.
These examples are exciting and will extend the applicability of AI to hyper-local use cases and clusters of IoT devices within industrial plants. However, to contrast these with the solutions provided by Cloudflare, Fastly and other distributed edge compute vendors, these are private environments intended for a single tenant. Additionally, the runtime environment is typically a virtualized container managed by an orchestration engine (Kubernetes for Google Cloud). These are important distinctions, as they imply that these 5G edge solutions would not directly encroach on the market for globally distributed, multi-tenant, serverless edge compute.
Investor Take-Aways
I have discussed a number of the drivers of decentralization and capabilities that nimble technology providers need to address them. Network architecture, application processing and data storage are rapidly dispersing on the Internet, away from centralized concentrations. We can monitor the velocity of these secular changes going forward to gauge the future demand for increasingly distributed network, compute and data storage services. Decentralization of identity will be another trend to monitor and distributed technology providers should be able to offer solutions to enable new methods of identity management.
Several distributed system providers are well equipped to address the needs of these trends towards decentralization. Purely based on product solution availability and breadth of coverage, I think Cloudflare (NET) is in the best position. They are pursuing multiple product strategies around decentralization, including SASE/Zero Trust, edge compute and distributed data storage. Their product development velocity is extreme and new opportunities continually emerge. Additionally, they have projected the largest TAM for their services.
Next in line is Zscaler. They are dominating distributed network services for large enterprises currently, with an emerging opportunity in cloud workload protection. As Internet usage moves beyond human participants to machine-to-machine communications, Zscaler will be in a perfect position to securely connect smart device traffic. Zscaler doesn’t leverage their network for edge compute and data storage currently, representing a distinction from Cloudflare. Nonetheless, they are growing revenue the fastest and have set a tangible goal to increase platform users by 10x and revenue per user by 6x. These KPIs have a very clear fit between the state of Zscaler’s product offerings and the market’s demand.
Finally, Fastly offers a highly optimized edge compute runtime with some basic data storage. They have strong penetration with major digital properties for their CDN business, and intend to expand these relationships to their new Compute@Edge and application security offerings. They have announced other “xxx@Edge” offerings that would further expand their market reach. On the flip side, I would like to see a faster product release cycle and updates on the newer offerings. Additionally, they have teased some new solutions for distributed data solutions, but made no announcements. On the execution front, they have experienced some revenue growth volatility, mostly tied to TikTok, and need to continue adding new customers at an accelerated rate.
The market for decentralized software, data and network infrastructure will continue to evolve. While independents discussed above appear well-positioned, we will also need to watch the hyperscalers. I currently favor investment in independents like Cloudflare and Zscaler, but will continue to monitor their execution, competitive position and market dynamics.
NOTE: This article does not represent investment advice and is solely the author’s opinion for managing his own investment portfolio. Readers are expected to perform their own due diligence before making investment decisions. Please see the Disclaimer for more detail.


Totally admired your faith on NET and still got super large position on it. And you got rewarded!
I think Cloudflare’s TAM seems very big but they realized forwarded revenue still very little compared with their Market Cap. I’m not here to discuss the suitable valuation for NET. But…I have no idea how NET can go that big and also it was my best shot YTD this year till now.
Same case study showed on SNOW, YTD performance still lagged that reminder that valuation probably still work here. So let me think about to trimmed NET. But will keep at least double digits in my portfolio.
Thanks again, looking forward to seeing your latest article for SNOW and Databrick.
Rick
Thanks, Rick. Yes, NET has been my best performing stock this year, up over 40% so far.
Your new commentary, Peter, reveals an exceedingly high level of concentrated thought, rigorous intelligence, and disciplined mind to write at length and compellingly about such an arcane topic. Bravo!
You provide many essential insights but I find this quote especially insightful…
“With this in mind, a reasonable litmus test for success in delivering these types of multi-tenant, globally distributed application services is whether the provider previously maintained a high-performance CDN. While CDN is largely a commodity service, it emphasis the native design requirements for global distribution, multi-tenancy and performance optimization. Vendors who can support a CDN service will more easily evolve to this multi-tenant edge compute solution. This is because their architecture was designed for it from the beginning. Hyperscalers, on the other hand, were grounded in central data centers. They more naturally expand into single-tenant compute and data solutions at the edge that resemble their existing centralized compute infrastructure. Most even promote this as a feature of their edge solutions – that the same tooling and infrastructure is available at the edge as in central data centers.”
Who [else] would have viewed this issue in this way? Not me! But you did and share your insight. Thank you.
As an investor, it is gratifying to read your commentary (okay, commentaries) and reflect on my investment decisions, past, present, and future: Most stocks will rise and fall as the market rises and falls, many stocks will rise distinct from the market’s cycle based on the company’s success, but only a few stocks will rise and then rise higher – and higher yet -thanks to a growing market and snatching a larger piece of that growing market, and a track record of successful execution their business plan. You identify three leaders (okay 2 with a possible 3rd), name a few other probable winners, and hint at a few more. In the end, after 2 hours of reading and thinking in the wee hours of my morning, “Decentralization Effects” proves not merely intellectually exciting but practically useful as well. Thank you very much.
Thanks for the thoughtful feedback, David. I really appreciate it. While I primarily write these articles to solidify my own understanding, I am glad they are useful for others.
The point you highlighted about the difference between the hyperscaler edge compute offerings and the multi-tenant edge compute solutions from the likes of Cloudflare and Fastly is really important. It is confusing to see all the headlines from hyperscalers, 5G network providers and other legacy technology players about “edge compute” launches and assume that these directly compete. However, as I pointed out, these are generally different technology approaches, with the primary architectural difference being single tenant and single location. I am happy to see you picked up on this.
Thanks for the great article! I believe Fastly is approaching the zero trust market within their new Okta partnership (providing the signal intel to Okta to allow for continuous authentication). Also, Fastly just announced yesterday their response security service. NET announced their offering in May. Definitely seems like Fastly is transitioning to a more security focused company in regards to future revenue.
https://www.signalsciences.com/blog/future-of-zero-trust-continuous-authentication/
https://docs.fastly.com/products/response-security-service
Thanks for the feedback. I agree that Fastly is shifting more heavily into security. That is primarily focused on application security (RASP) at this point, which does differentiate them from Cloudflare and Zscaler. With a fully functional edge network backed by SDN, it would be possible to expand into SASE/Zero Trust at some point, similar to what Cloudflare did with Cloudflare One last year.
This was exceptional – many thanks for this!
Peter, I have nothing to add, just gratitude for sharing your awesome analysis!
Thanks – appreciate the feedback!
Peter, thank you once again for such a monumental post! If I have ever seen an article describing The Big Picture, this must be it!
Now, I realize this question is not directly, if at all, related to the topic at hand but I’d be very interested to hear your thoughts around this, I don’t think you covered this in your posts so far.
If you looks at the charts of tech stocks (whether stock price charts or valuation multiple charts) since 2018 or so, they seem wild, to say the least. Looking at Nasdaq/QQQ chart for the past 20 years it seems to have been sky-rocketing for the past couple of years as well. Obviously we’re in the middle of a huge technical revolution (some say it’s greater than even the industrial revolution) but the pessimist in me remembers all the books saying how valuations eventually always return to the mean.
I am wondering how do you view tech/growth valuations in general? I don’t mean individual companies which may be higher than the most (like SNOW or NET) but the sector overall when the valuations are now at elevated levels that historically have not sustained in the past two centuries. Sure, in the past there were no IT/SaaS companies with recurring revenues, DBNER, huge high gross margins (compared to e.g. traditional manufacturing companies), and so on.. but still.
When reading comments from people investing in tech/growth they seem to think, dare I say, this time it’s really different. But when seeing value and dividend investors’ comments they are just waiting for the tech/growth “bubble” to burst, and keep reminding of the dotcom bubble.
Of course, none of knows for sure how the future plays out but are you concerned at all about valuations of tech/growth companies in your portfolio? Or what would need to happen to get you concerned?
I’m also fully invested in tech/growth myself and even a 50% correction wouldn’t be a complete disaster for me given the returns of the past few years but perhaps exactly because of those returns I occasionally find myself thinking how long this can last. It would be very interesting to hear your thoughts on this, perhaps here in the comments or even in a separate blog post.
FWIW, a peer growth investor blog has some very interesting around big drop and valuations, here are perhaps the two most related ones:
https://gauchorico.com/big-drops/
https://gauchorico.com/2021-06-30-portfolio-update/
Hi – thanks for your feedback on the post and additional thoughts around valuations. I don’t really have much to add on this topic. I agree that valuations for high growth/tech stocks are historically high right now. However, I don’t employ a strategy to try to manage to that. My focus is on the companies that I think are positioned to grow revenue 30-40% a year (or more) for the foreseeable future. I figure that high rate of growth will eventually work through any reset of valuations. My portfolio could absorb a 50% drawdown, primarily because I only need a small percent each year to cover my living expenses. If valuations were to return to some baseline, that would be okay with me. This is because eventually valuation would normalize and then stock price would start to grow again proportionally to revenue.
What would make me concerned about the technology stocks that I cover is if they could no longer grow revenue at the high rates we are currently seeing. That would represent some sort of serious recession or other exogenous event that halted all investment in software and the Internet. That type of circumstance would force we to rethink my strategy.
Hi Peter – Great write-up as usual. “My focus is on the companies that I think are positioned to grow revenue 30-40% a year (or more) for the foreseeable future.” Does $DOCU qualify perfectly? It seems it’s back in the 50% growth cohort, which is just as high as other stocks currently in your portfolio, but with a significantly higher annual run rate at almost $2B, making its 50% annual growth even more impressive. I understand you sold it out previously which makes it harder psychologically for you to re-enter and you have to sell something to buy it again resulting in capital gains taxes. But suppose you’re to start a new portfolio today would you own it? What’s holding you back given its superb numbers last quarter and likely this coming quarter as well? Anything under the surface might be of any concern?
Thanks for the feedback. If I still owned DOCU, I would be very happy and would hold onto it. I don’t see any immediate risks to the stock and was impressed by the Q1 results. The investment thesis I laid out in prior posts appears to be intact and Docusign has multiple avenues to continue growth. If I had new money coming into my portfolio, I would be buying it on dips. But, it’s not so compelling relative to my current holdings that I am willing to incur a 20%+ capital gains premium.
Thank you Peter! This was really informative read, I did like your angle on Web 3.0, DID and smart contracts.
I wanted to add that for Cloudflare to compete with AWS and transition more cloud native loads to the edge, they need to implement a container based solution at their pops, luckily they have already internal solution developed https://blog.cloudflare.com/containers-on-the-edge/
Also the Browser Isolation is utilizing their container solution, not the Workers, which is useful since it allows them to test their container with more workloads and add more internal use cases for testing.
Also I believe Cloudflare is still lacking CASB implementation which is something year Zscaler has had for a while now.
In addition, I believe the Cloudflare Pages product is under appreciated or people are not paying attention to it, but there were few updates like support for API commands that allows them to compete with Veracel (which is growing like weeds).
Hi – thanks for the feedback and the additional info.
I agree that support for containers is nice to see. As their blog post points out, these are suitable for some types of workloads that are compute-heavy or asynchronous. I think that having containers available to developers to supplement the Workers environment is an important addition. While I think that the majority of use cases for Workers will be distributed compute on isolates, containers could be used for scheduled jobs, CI builds or single-use processing. The key is that a developer could address both types of workloads in one environment, keeping them on Workers for all edge development.
Good note on Browser Isolation and I agree that Cloudflare Pages is another capability that will appeal to developers.
Peter, thanks so much for your articles. I started reading you a little over a year ago and you’ve been key in getting me up to speed in the area of hypergrowth tech. Amazing that I can get this level of analysis free of charge (I wouldn’t mind paying a little!).
This is an incredible document. Enjoyable to read and understand.
I purchased FSLY lately based mainly on their capability of speeding the transfer of data. This is essential to many data relied on companies. Has the gaming industry accepted FSLY?
The other thing i’d be interested in is ROKU. The streaming and youtubing seems to be extremely fast growing data exchange industry for the younger population. Wondering why
ROKU was not included in your data networking decentralization discussion?
Hi – glad that you found the post helpful. I haven’t seen Fastly announce any major customer relationships with gaming companies at this point, but there may be some. Their customers have been leaders in e-commerce, media, payments and some infrastructure.
Roku is a great company for investing in the media streaming space. However, this blog primarily focuses on companies that sell software, security and network infrastructure services to enterprises. Roku really doesn’t fall into that category, so I didn’t include it.
Fantastic article! Thanks for sharing. What role do companies like Akamai have to play going forward. Is it too late for AKAM? Would welcome any thoughts?
Thanks. I touched on Akamai briefly in the article. While they have the largest global network of PoPs, their pace of innovation has been slow in the last few years. I don’t see them as a technology leader any longer and they risk falling further behind the more nimble CDN providers like Cloudflare and Fastly.
Specifically, as it relates to edge compute and distributed data storage, they have the least performant or complete solution, as compared to Cloudflare and Fastly. They launched their EdgeWorkers product in October 2019, but it was in private beta through last year. The current solution is based on the V8 Engine and only supports JavaScript for development. They offer a basic key-value store, called EdgeKV, but no more sophisticated data storage solution that addresses strong consistency, full database functionality or data residency controls.
Wow this is the best article I’ve ever seen. Any thoughts on confluent?
Thanks. As a technology, Kafka and event-streaming architectures have a lot of potential and are popular approaches. As a company, I think Confluent could be executing better to capitalize on the opportunity. Specifically, for their size, I would expect higher revenue growth at this point. Since they are a new IPO, I plan to monitor for a couple of quarters. If you would like an in-depth review, peer analyst Muji at hhhypergrowth.com has put out some great work recently.
Hi, Peter
I really learned a lot from your analysis. Every time you post some article like this, I would spend days if not weeks to digest it.
A quick question: I found out you have hold position on CRWD, but you never analyzed this stock like other holdings. Any specific reason for this? (like regulatory etc.)
I have done some study on SentinelOne recently, and found it is also an appealing cloud security stock to have. If possible, would you be able to share some thoughts on these two?
Merci beaucoup.
Thanks for the feedback. I do own CRWD. I have discussed the company and my allocation in past newsletters. You can read the archive on this page. I do plan to publish a deep dive on the company in a blog post at some point. I haven’t done so to date because many other analysts cover them well. Muji at Hyypergrowth.com has talked about CRWD pretty extensively. He also reviewed SentinelOne.
My initial take on SentinelOne is that they have potential, but I want to give them a few quarters of performance before considering a position. Of course, my default will be to compare them to Crowdstrike.
Another amazing article. I definitely didn’t think I’d spend 2 hours reading an article on network security, edge compute and data storage, but you make it enjoyable.
I think the best part is tying it back to the actual use cases of e-commerce stores, factory centers, media, etc. Otherwise this stuff is too abstract for me to understand.
Thanks!
Hi Peter, thanks for another brilliant essay. I was curious if you came across Megaport, and if you did – do you think it fits within this trend of decentralization? Especially considering their latest product – MVE (Megaport Virtual Edge)?
Thanks,
Yoni
Hi Peter, very informative article. Since you are not currently invested in Fastly, are you considering investing there soon?
Thanks – I laid out a few things I am looking for Fastly to do. These are to maintain their recent uptick in customer additions, demonstrate (or just announce) more progress on new product offerings (all the xxx@edge products mentioned during Altitude), and pull back the curtain on actual usage of Compute@Edge. These could all combine and provide a nice set-up for 2022. This would be on top of lapping the TikTok revenue impact starting in Q3. Once I see these materializing, I will start to lean back into FSLY.
Concerning Fastly customer acquisition, “need to continue adding new customers at an accelerated rate. ” shouldn’t this be to START adding new customers at an accelerated rate?
It has been some time since I last checked numbers but they are have been way behind, vis-a-vis Cloudfare acquisition rate.
I keep expanding my knowledge base reading your posts-thanks.
Thanks. Regarding adding new customers, I was referring to the fact that Fastly added 123 new total customers in Q1, which was up 20% year/year and 5.9% sequentially. This represents a significant jump in total customers adds – the largest increase in at least 2 years, after adding just 37 customers in Q4 (1.8% seq) and 96 in Q3. So, I would like to see them maintain this higher rate of total customer adds.
Cloudflare grew total paying customers by 7.4% sequentially and 33.6% annually in Q1. The total number of customers isn’t really a useful metric, as Fastly customers spend much more on average. Regardless, I wouldn’t focus on comparing the two, as they address some different markets. Individually, if Fastly can maintain their rate of customer additions around 20-25% annually and keep long-term NRR above 130%, that implies they can push revenue growth back over 40%. That would rerate the FSLY valuation and provide a nice bump going into 2022.