Much has been written about how enterprises are awash in data, generating new signals at an accelerating rate. A lot of this focus has been on the data analytics and machine learning space, where arguably a large opportunity lies. Businesses are struggling to process all their data in order to gain new customer insights and improve performance. Recent IPOs like Snowflake, C3.ai and Palantir have driven investor interest and delivered valuations that reflect the huge potential.
While these opportunities in big data convergence, AI and advanced analytics are exciting, an equally significant evolution is happening on the transactional side of data storage and distribution. Models for data storage have moved far beyond a single large relational database housed on premise. Application architectures are evolving rapidly, with the return of rich clients, disparate device channels, an ecosystem of APIs and breaking up monoliths into micro-services. Cloud hosting and serverless have provided new ways to manage the runtimes that execute code. Software engineering roles have been coalescing, highlighted by the ascendancy of the developer and a bias towards productivity.
These forces are creating opportunities for emerging technology providers to capture developer mindshare and power application workloads. Cloud-based services have lowered the barrier to entry for launching new transactional data storage solutions. In the same way that Snowflake created a robust offering separate from the hyperscalers, independent data storage companies are thriving on the transactional side. This blog post provides investors with some background on application data storage technologies and an examination of trends in modern software architectures. It concludes with a survey of companies (several that are publicly traded) which stand to benefit as application workloads explode.
Background
Before the rise of the Internet, application architectures predominantly followed the client-server model. In this case, most of the application logic and all of the UI rendering occurred within a “fat” client application that ran within the operating system of the user’s personal computer. Often, the operating system was Windows and the PC was a desktop. The server primarily performed a data storage function, usually consisting of just the database itself. Examples of these central databases were Microsoft SQL Server, Oracle, Sybase and IBM DB2. These databases were almost exclusively relational, with SQL as the query language.
Both the client and server were located on the same private network, usually a corporate LAN or WAN. If data needed to be moved from one network to another, that was usually accomplished by copying the full dataset onto a physical device and transporting it to the other location. All data for an application was also stored on a single database, versus separate databases for different data types.
In this world, IT roles were distinct. Developers wrote client applications in a programming language that could be compiled into an executable that ran directly in the target PC’s operating system. For Windows, this involved languages like Visual Basic or C++. The server-side database was the domain of the Database Administrator (DBA). They designed the data structures, set up the database, monitored its usage and performed maintenance tasks like back-ups.
Internet usage caused aspects of this model to change. Application architecture moved towards “thin” clients that ran within a web browser. Initially, browsers offered little programmatic control beyond specifying layout and styling of the user interface. All business logic moved to a “web server” (eventually called an application server), which was located centrally in a data center. The database server remained, but was abstracted from the client application by the application server.
Browser-based client applications were written in HTML and CSS. Application server logic had many options for development, with numerous companies emerging to serve the need. Examples include more than can be reasonably listed, with highlights like Microsoft IIS, IBM WebSphere and Adobe ColdFusion. Eventually, packages based on open source web frameworks for PHP, Java, Python and other languages supplanted the commercial application server offerings.
With the new Internet architecture, software engineering roles began shifting. Developers focused on either front-end (HTML/CSS) or back-end (PHP, Java, Python, C#, etc.). Databases were still managed by DBAs. However, with the centralization of business logic and data access onto application servers, it became possible to separate data into different database tiers, based on context. A team might store all product data in one database and user data in another. The application server knew how and when to access each.
Soon, the front-end developers became frustrated by their dependence on the back-end developers to add simple logic to the user experience. As browsers began supporting basic scripting languages, like JavaScript, front-end developers could add form validation and other simple text manipulation functions to their web pages.
This simple model for web development persisted until two new forces emerged. First, scripting languages were given the ability to manipulate the browser’s DOM. This changed the game dramatically, allowing front-end developers to have much more control over how their browser-based applications performed. Second, mobile applications emerged. These existed outside of the browser, offering a full-featured fat client that ran directly in the operating system (iOS, Android) of the mobile device.
Suddenly, we were back to the world of fat clients, but with distant servers communicating across the Internet at web scale. The web server no longer needed to return the screen formatting instructions on each request. This drove the creation of a new facade for accessing business logic and data, packaged neatly into REST-based API’s. Mobile apps were structured so that they could run continuously within the device’s OS, periodically requesting data from the remote API in order to provide context to the app.
Because mobile apps could perform rich functionality on the client side and promoted the use of API’s to organize data access, pressure built on the browser development side to facilitate a similar model. Browser-run scripting languages and development frameworks became more robust, centralizing on JavaScript as the programming language. Browser-based “single-page apps” became richer and richer, migrating to the same API-driven model for accessing data and centralized business logic as their mobile app counterparts. JavaScript frameworks like JQuery, Angular and React (and others) emerged to provide common, re-usable code for many functions, making the developer’s life easier. This allowed browser app development to resemble the same process as mobile app building. Some of these JavaScript frameworks (most notably React Native) evolved to the point where a developer could write a single app that could be “compiled” into a different target for each mobile OS and then re-purposed for the browser.
In parallel, software engineering roles continued to evolve. The most significant change was the movement towards full stack development. As languages converged and tooling improved, it became feasible to expect a single developer to be able to address both the front-end and back-end of an application. Oftentimes, more senior developers handled database management tasks as well, obviating the need for dedicated DBAs, at least in smaller companies. Developers began provisioning their own hosting infrastructure and supporting services as the DevOps movement emerged.
DevOps was facilitated by the cloud movement. Enterprises began migrating their server-side resources out of their own data centers and onto public clouds. Initially, this involved duplicating the same server configuration with dedicated hardware for data storage, file directories, monitoring and messaging. As the public cloud providers started looking for new revenue streams beyond selling compute and storage, they began creating services that developers could consume to handle various aspects of application software infrastructure. One of the first was database services.
These data services were often delivered through network-accessed APIs that didn’t require running the server software itself. This freed up developers to not worry about their server infrastructure. If they needed access to data storage, they could just spin up a data service in their cloud environment. The software engineer role expanded to include data access and storage responsibilities.
Looking forward from this point, we can explore the next wave of evolution in transactional data storage and distribution. Modern transactional data storage solutions are influenced by four factors – new data models, application architectures, runtime hosting configurations and engineering roles.
- Data Storage Models
- Application Software Architectures
- Hosting Configurations
- Software Engineering Roles and Methods
This analysis will focus on trends in processing transactional data as part of application workloads. This type of data access pattern is often referred to as Online Transaction Processing (OLTP). The other major category of data processing and storage revolves around analytics workloads (OLAP), which generally involve ingesting data from many sources (including OLTP stores) and facilitating multi-dimensional analysis. For an overview of Snowflake and the OLAP landscape, Muji from Hhhypergrowth provided a great overview in his blog.
Transactional Data Storage Models
The data storage model determines how the data is structured within the data store and the mechanisms used to retrieve it. In the past, almost all databases were relational. The relational model of databases primarily refers to the structure of the data into “tables”, which are made up of rows and columns, much like a spreadsheet. Relational databases are defined and queried through a language called SQL (Structured Query Language). This provides commands for defining the data tables (CREATE, ALTER), querying the data in them (SELECT) and changing the data (INSERT, UPDATE, DELETE). This model for data storage has been surprisingly resilient and is still the most popular today. Examples of database solutions using the relational model are Oracle Database, Microsoft SQL Server, MySQL, PostgreSQL and many others.
As application development evolved, new models emerged for representing data within a software application and exchanging it with other applications. This was an offshoot of object-oriented programming and the need to store discrete sets of related data in attribute-value pairs. This method of organizing data within an application allowed developers to handle it in a way that more directly reflected their conceptual view in the application, versus how it was structured in the database. This difference has traditionally been driven by theories around data normalization, which fundamentally structured data into tables with the objective of minimizing duplication (to save space) and improve data integrity (by enforcing a schema). Over time, these design constraints loosened as a result of cheaper storage and new types of data. A strict requirement for normalization and structure gave way to models that reflected real-world usage by application developers.
One format that became popular for this data representation within an application is JSON (JavaScript Object Notation). JSON provides an open file format structured for data exchange. It is designed to be easily human readable and “flat”. While data fields can be hierarchical, all the data needed to represent the full data entity is included in the JSON document. This differs from the normalized form in that relationships between different types are separated into tables with reference keys. As an example, we can use JSON to model a person. Each person has data attributes directly associated with them, like their name or height. But, they can also have a hierarchical relationship (aka relational) with other attributes like address and phone number. In a relational database, address and phone numbers would be stored in separate database tables. In a JSON document, all relevant values for a person entity are stored together in one long, flat document. This representation is useful for developers in an application, as they often want all the information that describes a single person available in one data object with attributes.
When these name-value pairs are organized into a single entity (an object) in JSON notation and written out, they resemble a document. Additionally, these “documents” can be written to disk and persisted as an individual file.

As JSON became popular as a method for developers to structure data within an application, developers (always looking to save time) began pushing for ways to exchange and store data in the same format outside of their application. JSON was initially applied to facilitate communications within browsers, but quickly was adopted to provide a means to exchange data through APIs (Application Programming Interface). With the explosion of mobile apps after 2005, every modern software application needed to expose its data through an open API, which could be accessed by iOS and Android apps running within mobile devices. JSON became the standard for encapsulating data into request/response exchanges to power all functionality connecting a mobile app to its central “back-end” application. As every application needed to support JSON for data exchange, this convention of representing similar data types in hierarchical attribute-value pairs became standard.
This notion of storing data externally to the application in JSON format as documents became the foundation for the emergence of document-oriented databases (or document stores). Document-oriented databases allow data to be stored and retrieved in a way that preserves the JSON document format and aligns with the notion of an object. This contrasts with the relational model, in which database tables are generally not structured around objects and object data may be spread across several database tables. This requires the software application to “translate” from object notation into the database structure, often referred to as an ORM (Object-relational Mapping).
Document stores are one of the main categories of NoSQL databases (non-relational). There are many implementations of document stores. MongoDB is considered to be the most popular document store. Other common examples are Apache CouchDB, Couchbase, Amazon DocumentDB (AWS implementation of MongoDB) and Azure Cosmos DB.
Additional major categories of NoSQL databases are key-value, wide column and graph databases. In a key-value store, every record consists of a key-value pair. The key provides a unique identifier for referencing the value, often organized into subcomponents that resemble a hierarchical file structure. Because of this simple structure, key-value stores use very little space and are highly performant. For this reason, they are often used as an in-memory cache, but some implementations also support persistence. Popular examples of key-value stores are Redis and Memcached. Redis is supported by the commercial entity Redis Labs. Additionally, hyperscalers offer hosted versions of some open source projects. Amazon ElastiCache provides a managed service for both Redis and Memcached. Also, some cloud data services support key-value functionality bundled with other data storage types. Examples of these are Amazon DynamoDB and Azure Cosmos DB.
In a wide column store, data is organized into records with keys, but the number and names of columns for each row can vary and scale out to millions of columns. Wide column stores can be seen as two-dimensional key-value stores. Google Bigtable was the original wide column store. Wide column stores are ideal for a very large dataset that has a unique query pattern on individual attributes, like the metadata associated with a web page. Expanding the cluster infinitely is just a matter of continuing to add new nodes. Examples of popular wide column stores are Cassandra and HBase.
Graph databases organize data as nodes that contain properties (like an object). Edges then designate the relationship between nodes. This can be visualized as a graph. A common example is a social graph where the nodes represent people and the edges designate a “friend” relationship. As social networks emerged, it became clear that existing relational databases were not sufficient to organize and retrieve graph relationships in a performant manner. Graph databases emerged for this and other use cases. The addressable market of use cases that really benefit from a dedicated graph database is somewhat limited. Examples of popular graph database implementations are Neo4j, OrientDB and ArangoDB.
Search
Another data access pattern common for transactional workloads in user-facing applications is search. Over the years, the concept of search as applied to Internet-based software experiences has evolved significantly. The original and most basic use case is text search – typing a few keywords into a search box and getting back a set of results. As the types of data handled by web sites expanded beyond text to products, locations, user profiles and more, the same core search technology could be applied to new types of multivariate retrieval. Examples include product faceted search (e-commerce), profile matching (dating), content recommendations (video streaming), geographic proximity (mapping), etc. As examples, Tinder uses a search function to return matching user profiles for dating, while Uber uses search to locate the closest available driver to a passenger.
Putting aside proprietary solutions, like Google, the first general purpose, open source search technology was Lucene. Lucene was developed by Doug Cutting in 1999, a luminary in open source, who also built Apache Hadoop. Lucene is a search engine software library, originally written in Java, but has been ported to most other major programming languages. Lucene became a top-level Apache project in 2005. To supplement Lucene, Cutting also built Nutch, which is an open source web crawler. Between Lucene and Nutch, one could build a general search engine, much like Google or Bing.
In the early 2000’s, while recovering from the dot-com bust of 2001, several Internet based companies were building out their businesses on the web. Where they needed operational search capabilities at scale, there were few options. Lucene provided a good base set of libraries upon which to build search functionality, but it couldn’t be deployed to a server out of the box and immediately begin indexing and querying content. An additional set of functionality was needed to handle this plumbing and infrastructure in order to make Lucene into a “server” (in this context, responding to requests over a neutral protocol like HTTP).
One solution to this problem was an Apache project called Solr. The acronym SOLR stands for Search on Lucene and Resin, which is a lightweight HTTP server. Solr enables a number of search operations – full-text search, faceted search, real-time indexing, clustering and data ingestion. Solr can pull data from multiple sources, index it and store it internally in a format suitable for rapid query retrieval (technically a reverse index). Solr was designed for scalability and fault tolerance, by supporting horizontal load-balancing of many individual servers. It exposes a REST-based, JSON API over HTTP that makes communication with other services open and distributed. Solr is still supported today and is widely applied to enterprise search and analytics use cases. According to the Apache Solr web site, Solr is used by a number of large web sites, including Instagram, Netflix, Disney, Bloomberg, Travelocity and Zappos.
The commercial entity behind Solr is Lucidworks. It is an enterprise search technology company that provides an application development platform, commercial support, consulting, training and value-add software for Lucene and Solr. Lucidworks is a private company founded in 2007. The company has raised almost $200M to date, from a prominent set of investors. Additionally, many of the core Solr committers are employees.
Around the same time, Shay Banon, the founder of Elastic (ESTC), was working on his own search solution. As the story goes, he was trying to build a search engine for his wife’s collection of cooking recipes. In 2004, his first iteration was called Compass. After working on a few iterations of Compass, he realized that he wanted to create a distributed solution that supported a common interface for integration, namely JSON over HTTP. This became Elasticsearch, which was released in 2010. Like Solr, Shay also chose to utilize Apache Lucene for the core search libraries.
Search implementations were applied to use cases across popular web sites, working alongside relational data stores to power specific search related workloads. In many cases, a relational database provided the source data for the search implementation, leveraging the higher performance gained from a pre-calculated search index.
As large volumes of log data began being generated by all sorts of online applications, search was applied to mine these as well. This elicited use cases like log analysis, APM, security monitoring, business analytics and metrics. This analytical function drives a lot of usage of search related technologies today, but isn’t associated with our examination of data stores that drive user-facing applications.
Search is an important use case in the technology selection process for a development team to consider, because it represents a different data access pattern and cannot easily be serviced by a traditional database (relational or non-relational). As with Tinder and Uber, these search related workloads are addressed by using a search technology. In those cases, it is Elasticsearch, but Solr and cloud-native solutions like Algolia, occupy segments of the market as well. The high growth of large data sets and new consumer-focused digital experiences will continue to drive demand for search technologies going forward.
Event Streaming
As Internet usage grew, new types of large-scale data generation use cases emerged that required a different type of data collection and storage architecture. While data reads can scale almost infinitely with replicated copies of data and caches, scaling data write volume is more of a challenge. Sharding databases is one way to handle more writes, but this creates management overhead. Database clusters with eventual write consistency offer another approach.
However, some types of software applications generate a large volume of state changes that can thought of as short messages containing a few data values that are either new or represent an update to a prior value. These changes in state are commonly referred to as events. These can generally be handled asynchronously, loosely meaning that they need to be captured and persisted, but that there isn’t an expectation of an immediate (synchronous) response.
Examples of applications that generate a large volume of events are found in industrial use cases like sensors (IoT). AdTech provides another set of use cases, where an ad server needs to collect large volumes of user actions (clicks, views, etc.) in order to determine what ad to serve in the future. Because events are time-stamped as they flow into the data store, they are often pictured as a stream. The label of event streaming is applied to the asynchronous flow of all these data updates.
The data store that collects and persists the event stream is referred to as a stream processing platform. Apache Kafka is the most well-known implementation. The goal of Kafka is to provide a high-throughput, low latency platform for handling real-time data feeds. Data, consisting of short messages, is fed to the system from an arbitrary number of producers. Messages are written to “partitions” that are grouped into “topics”. Topics span a single data entity, like temperatures, clicks or locations. Message data can be persisted for a defined amount of time. Consumers are applications that read messages from topics and process the data to pass to a downstream system of record. There is generally more than one consumer, each with its own purpose. After the persistence period for messages in a topic has passed, that data is purged.

The stream processing platform supplanted prior systems that were purely message brokers, like RabbitMQ or Apache ActiveMQ. These simple message brokers are still in use, but don’t offer the broader functionality to handle a multi-faceted event stream. The stream processing function has also been referred to as the publish-subscribe pattern, or pubsub for short.
Apache Kafka has been implemented as a hosted service by a number of commercial entities. The primary maintainer at this point is Confluent. Confluent was founded by the team that originally built Kafka at LinkedIn. Confluent has developed an event streaming platform with Kafka at the core. Like other open core models, Confluent is building products and services around the open source Kafka project. These include a cloud-hosted version of Kafka, a library of connectors and support.
Confluent built a SQL-like query language for pulling data from a Kafka cluster in a way that is familiar to developers, called ksql. They also created a database structure that sits on top of Kafka, called ksqlDB. This dramatically simplifies the process of building an application on top of an event stream. ksqlDB essentially abstracts away querying the event stream through a consumer and allows the developer to treat the event stream like a normal relational database. This is a new and very interesting twist, as it brings data streaming and synchronous querying together.

Besides Confluent, the hyperscalers offer hosted Kafka services. AWS has Amazon Managed Streaming for Apache Kafka (MSK), which is a fully managed, highly available Kafka implementation. AWS offers a separate proprietary product called Kinesis, that is a data streaming processing engine. This is not based on Kafka, but leverages many of the same concepts around the publish-subscribe pattern. Azure and GCP offer data streaming solutions, but also have strong partnerships with Confluent for managed Kafka.
Application Software Architectures
The evolution in application architectures has similarly influenced the progression and expansion of transactional data storage solutions. The original client-server applications were monolithic, meaning that all code for the application was part of a single codebase and distribution. It executed in one runtime, whether as a client on the user’s desktop or the web server in a data center. Monoliths generally connected to a single database to read and write data for the application. Since there was only one database, the prevailing data storage model was utilized, which was relational.
Application monoliths had many advantages initially. All of the code was in one place, allowing the development team to trace dependencies and make changes in one location. The lack of dependencies also made observability straightforward. Traces of app performance progressed through a single codebase running within one memory space. The monitoring system didn’t have to stitch together program flow across different applications, making identification of bottlenecks easy. Even interface points to external services, like the Facebook Connect API, were clear.
Monoliths were also deployed into a single hosting environment. For an Internet application, this meant running on a tier of application servers (whether Apache, Nginx, Websphere, etc.). As these applications were stateless, teams could increase capacity by adding more servers and horizontally scaling with a load balancer.
However, as applications became much more complex and engineering teams grew, the monolithic application architecture was no longer sustainable. First, larger numbers of developers working within the same codebase created a tangle of code change conflicts that had to be laboriously unraveled prior to release.
Also, regression test suites grew as the application became larger and more complex. While some aspects of functional testing could be automated, most development organizations had a QA team perform a final set of manual sanity tests. On a large monolithic codebase, the code conflict resolution and testing overhead could add hours or days to a development cycle.
Additionally, while horizontal scaling of a large monolith was feasible to accommodate greater usage, this scaling drove inefficient hardware utilization as the performance characteristics of the application varied greatly by feature. Some functionality might be memory or I/O intensive, while others required more compute. Yet, only one application server hardware spec could be utilized to host the entire application. This resulted in over-provisioning, selecting the app server with the most memory, I/O and compute in order to perform well for all types of workloads.
As the DevOps movement gained traction, most of the release cycle could be automated. This allowed development teams to increase the frequency of their production releases. Code could be pushed through the dev/test/release cycle very quickly, creating incentives to deploy bug fixes and small features daily, rather than waiting for a full sprint release cycle (anywhere from 1-4 weeks, depending on the team’s choice).
These constraints of a large monolithic codebase, single server tier and rapid release cycles sparked the advent of micro-services. Micro-services architecture involves breaking the monolith into functional parts, each with its own smaller, self-contained codebase, hosting environment and release cycle. For a typical Internet application, like an e-commerce app, functionality like user profile management, product search, check-out and communications can all be separate micro-services. These communicate with each other through open API interfaces, often over HTTP.
Micro-services address many of the problems discussed earlier with monolithic applications. The codebase for each is isolated, reducing the potential for conflicts between developers as they work through changes required to deliver the features for a particular dev cycle. In fact, the development teams themselves often break up to organize around a micro-service, allowing for more specialization and sophistication in handling a particular type of user experience. Fraud detection expertise is much different than media streaming.

Micro-services also allow the hosting environment to be tailored to the unique runtime characteristics for that part of the application. The team can choose a different programming language, supporting framework, application server and server hardware footprint to best meet the requirements for their micro-service. Some teams select high performance languages with heavy compute and memory runtimes to address a workload like user authentication or search. Other teams with heavier I/O dependencies could select a language that favored developer productivity and callbacks.
As it relates to transactional data stores, micro-services unleashed a wave of innovation and new demand. This was driven by the fact that each micro-service could and often did have its own dedicated data store. Similar to selecting a programming language, application server type and hosting model, the development team can consider the data storage engine that best meets the needs of their micro-service. This means that other types of data storage engines, like non-relational stores, can be utilized for each micro-service, based on the characteristics of that portion of the application.
Some workloads, like financial transactions, still favor a relational (or tightly structured) data model. On the other hand, data types that benefit from a looser schema and semi-structured design favor a non-relational data store, like a document database, search index or key-value store. Semi-structured data examples might be user profiles or product descriptions. In these cases, the user or product can still be queried by a primary key, like their ID, but all the other information describing them is loosely structured into a document, allowing easy appending as new types of user or product description parameters need to be added.
Micro-services freed up development teams to consider alternate data stores, like MongoDB, Elasticsearch, Redis, Cassandra, etc. for their data storage needs. This started the shift in workload allocation away from being over 90% relational to more of a mix. Non-relational databases won’t fully replace relational databases, and vica-versa. They will each thrive as development teams build more digital experiences and are able to select the best data storage engine for their particular need.
I think this is where investors can get distracted by data storage philosophy rants like SQL versus NoSQL. One solution doesn’t have to “win” or be better. Like anything in technology solution, it depends on the use case. With micro-services, development teams are free to select the best tool to address their workload. Debating one data storage technique over another is similar to debating whether a hammer is better than a saw (or at the very least, debating a sledge hammer versus a pickaxe). Since the market for transactional data storage is enormous and development teams have the freedom to choose, both relational and non-relational data storage providers will be have plenty of room to grow.
The same forces apply to event streaming use cases, where data is routed into queues by topic for other processes to pull from. Micro-services enable an event-driven architecture to be supported just like a standard, synchronous, request/response web architecture. Event packets can be routed to the collectors for the event-driven service. These events are aggregated and processed by the storage engine. In this case, Kafka or a similar event-driven data processing engine can be selected by the development team. As application footprints grow and new use cases emerge for digitization, streaming platforms will see increasing demand.
The proliferation of discrete services will be further accelerated by some of the newest application architectures that focus on the thinnest of clients. Jamstack is a good example, where the screens of a web application are pre-rendered and delivered from a CDN. Javascript running in the client’s browser is used to provide the dynamic aspects fo the web pages. For any data access or back-end business logic, the Jamstack relies on third-party services accessed over the Internet through APIs.
The thriving API economy has become a significant enabler for Jamstack sites. The ability to leverage domain experts who offer their products and service via APIs has allowed teams to build far more complex applications than if they were to take on the risk and burden of such capabilities themselves. Now we can outsource things like authentication and identity, payments, content management, data services, search, and much more.
Jamstack sites might utilise such services at build time, and also at run time directly from the browser via JavaScript. And the clean decoupling of these services allows for greater portability and flexibility, as well as significantly reduced risk.
Jamstack.org, What is Jamstack?
As it relates to transactional data storage, this architectural movement will drive demand in a few ways. First, as the data aspects of the application are completely API driven, it further pushes architectures towards micro-services. These APIs would be provided by either the hosting development organization themselves or tap into third-parties. Second, it lowers the barrier of entry for new digital experiences. Development teams utilize APIs to stitch together an experience with minimal coding and hosting overhead. Third, while the user screens are pre-rendered, these are rebuilt periodically using transactional data as a source. So, it doesn’t necessarily reduce the need for transactional data sources.

A further refinement of the Jamstack approach is provided by Front-end Application Bundles (FABs). These support the same approach of producing a very thin server-side bundle that can be pushed to the network edge. It allows for more dynamic functionality, by processing server-side Javascript. This likely explains why Cloudflare recently introduced Cloudflare Pages and acquired Linc, which is a popular CI/CD pipeline for front-end applications and managing FABs. Server-side Javascript can be executed by Cloudflare’s Workers edge compute solution. This will further drive Cloudflare’s strategy of extending application development and delivery to the network edge, in this case through their globally distributed network of POPs. As I will discuss in the next section, this migration of logic to the edge has implications for transactional data storage as well.
Hosting Configurations
In the days of traditional client-server architectures, data was stored in a relational database located on a corporate network. These solutions were usually provided by large companies, which had the resources to market into and support these kinds of fixed installations. Developers could not simply install a database system themselves to try it out. Gatekeepers, like DBAs, decided what database software to purchase, controlled access to limited database resources and had to approve any new application usage.
With the rise of the Internet and data centers for hosting, companies moved their databases to facilities managed by someone else. These data center operators provided network connectivity, power and a facility. However, the logical model of organizing databases and provisioning access to them was kept the same.
This continued even through the the first phase of cloud-computing, in which the hyperscalers rented out compute, storage and network, allowing companies to replicate their server environment on the hyperscalers’ resources. In this case, the company’s system administrators and DBAs still controlled and managed the servers. They just no longer needed to worry about provisioning hardware and operating a physical data center.
However, cloud hosting began opening up database creation to roles outside of the traditional IT administrators. Developers could provision their own database instances on the cloud. Often this was done in a dev or test environment as part of a prototype or skunkworks project. Also, many developers had their own personal cloud hosting accounts for pet projects. As the cost of gaining access to server resources dropped significantly, developers were able to operate in more of a self-serve manner. This still required technical expertise to bring up a new server instance, install the operating system, load the database, configure it, etc.
The big acceleration in proliferation of data storage options and specialization came with the emergence of database-as-a-service (DBaaS). This started with the hyperscalers, who realized that they could sell services on top of compute and storage which provided functional building blocks that developers might need in constructing applications. AWS started by packaging the popular open source relational databases, like MySQL and PostgreSQL, into RDS. Azure and GCP followed suit. Now, there are many flavors of data services available from each hyperscaler. AWS, for example, has 11 different DBaaS offerings.
These provided limitless access to data storage for development teams, without the need to worry about operating the database. Developers could go through a simple activation process, usually within a web-based UI, to get a new data service provisioned for their needs. These would be provided with connection details to embed into the software application. Developers could then begin interacting with the data service in a similar way to fixed databases of the past.
For some open source database packages, there was already a commercial entity that sponsored the open source project and generated revenue through support and selling add-on features. Examples included MongoDB, Elastic and Confluent. These moves by the hyperscalers to host open source projects (most notably AWS) put immediate pressure on the business models of the commercial entities representing these open source projects. If the same version of Elasticsearch or MongoDB was available from the hyperscalers, why would one pay the company behind them for a similar service? Well, those companies got smart around 2018 and modified their software licenses so that the source code was open, but added restrictions on offering hosting of the packages for a fee. Hyperscalers could only offer the version of these packages available before the license change went into effect.
Fast forward a couple of years and the difference between the newest versions of the offerings from the likes of Elastic and MongoDB as compared to the older versions from the hyperscalers is substantial. The two sets of offerings are no longer at parity, making developers gravitate towards the solution from the open source package sponsor. Additionally, these companies began offering a cloud-hosted, database-as-a-service product themselves on the hyperscalers’ own cloud infrastructure. Examples are MongoDB Atlas and Elastic Cloud. Both of these services are offered in most availability zones on each of AWS, Azure and GCP.
As a result of their focus on proprietary features and continuous iteration, the capabilities of the independent offerings are starting to exceed comparable data storage products from the hyperscalers. For MongoDB, this is a document-oriented database. For Elastic, this is a search engine, with packaged solutions for enterprise search, observability and security analytics. Development teams creating new user-facing applications can review the cloud-based data storage options from the independents, alongside those from the hyperscalers, as they make data storage architecture selections. In the case of Azure and GCP, these can even be paid for through a consolidated bill.
This ease of access and enhanced functionality is driving rapid adoption of the cloud-based data storage services from the independents. In the last quarter, MongoDB Atlas grew 61% year/year and Elastic Cloud grew 81%. Both of these are higher than the overall revenue growth rates of all cloud vendors. We don’t know sales rates by data storage service within each hyperscaler, so it’s possible some of their data services are growing more quickly, but the general point stands.
This growth could see tailwinds from the tendency of large IT teams to prefer a multi-cloud solution. As I have argued in a past blog post, I think multi-cloud is a limiter for the cloud vendors. For a variety of reasons, IT organizations at large enterprises want to avoid cloud vendor lock-in where possible. Data storage represents an area where lock-in is actually the most risky, as switching costs are high.
MongoDB took a further step by expanding Atlas to provide a multi-cloud capability. In this case, the user make data in their MongoDB cluster available across multiple cloud vendors. This means the enterprise IT team isn’t constrained to a single cloud vendor’s proprietary offering. They can utilize MongoDB on one hyperscaler and access the same data from a different application on another. This provides the flexibility to leverage specialized capabilities across multiple cloud vendors. It also reduces switching costs if an enterprise needs to exit a cloud vendor completely for some reason.
This is a real game changer, in my mind. As enterprises seek to avoid cloud vendor lock-in, they will pursue multi-cloud options. In the case of application data, they can design their data access interface implementations to a single set of APIs and not worry about rework on a different cloud. This flexibility gives the independent provider a lot of power. On the OLAP side, this independence explains the rising dominance of Snowflake for data warehousing solutions. A similar parallel can be drawn for transactional data (OLTP) solutions that can operate across clouds.
The next level of this independence is emerging with the new edge networks. In this case, hosting resources exist on a network of POPs completely separate from the hyperscalers. Examples are Cloudflare and Fastly, as well as Akamai. For these providers, they have small data center instances (POPs) in locations spread over the globe.
Traditionally, these POPs were used for delivering cached static content (CDN). However, these vendors are rapidly adding compute and data storage capabilities that allow developers to build applications in these distributed environments. This is referred to as edge computing. The developer can write an edge application in a variety of languages and upload it to the vendor’s hosted runtime. These environments are serverless, meaning the developer doesn’t need to worry about provisioning an application server in all locations in order to run their code. These applications are also distributed in that they can handle requests from users simultaneously in all POP locations.
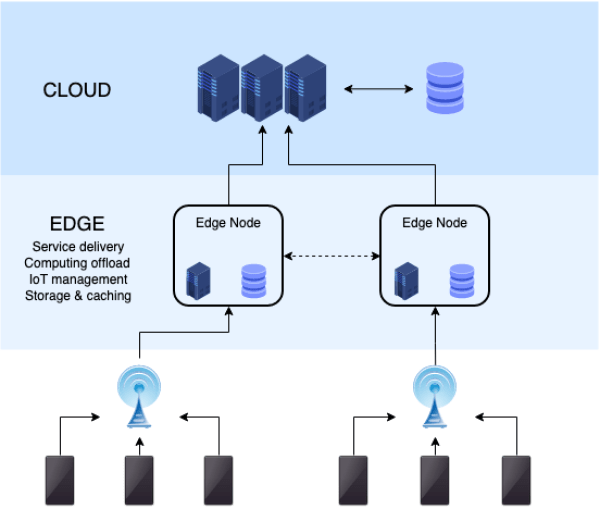
This has huge implications for the transactional data storage market and the opportunity for the edge networks. If they can shift some application compute spend to the edge, then data storage for those applications would follow. This in effect magnifies their opportunity, as both compute and storage services would migrate from the origin hyperscaler offerings to the edge network providers.
To service this need, Cloudflare provides Workers KV, a simple key-value store, and recently announced Durable Objects, which extends storage to stronger consistency among nodes and data sharing between clients. These are meant to be used as the data store for distributed serverless applications built on the Workers platform.
Fastly offers a key-value store as well, called Edge Dictionaries. They are developing a fully distributed data storage solution as part of their Compute@Edge platform, which itself is in limited availability. On a recent podcast on Software Engineering Daily, Fastly’s CTO said that they first wanted Fastly to provide a distributed data service from their POPs. But, they soon realized this would be more relevant to developers if it could be referenced from a compute runtime. This caused them to prioritize building out the runtime first, before tackling the data storage.
A similar data service is offered by Fauna, which is a popular globally distributed, cloud-based data store. It is completely accessible through APIs and meant to be connected to directly by client applications (web or mobile). This future-facing approach to application development and infrastructure is dubbed the Client-serverless architecture. It is similar to the Firebase solution offered by Google. In this case, there is no server-side code runtime. The service just provide data storage.
Software Engineering Roles and Methods
The increasing influence of the developer is biasing choice of tooling towards solutions that favor productivity and ease of use. This is understandable if you consider the primary measure of a software engineering team’s success is feature delivery. Certainly high availability and security are are important considerations, but at this point, those are expected. Success for a CTO or Head of Product is primarily determined by the new value they create for customers. Often this value is measured in product features.
As the primary builder of features, the developer has become the focal point for determining product delivery schedules. This has been enhanced by newer software planning methodologies, like agile, which encourage direct discussion between product managers and developers. Developers scope feature requests, assigning “feature points” reflecting the level of difficulty. Anything that slows down feature development is surfaced and addressed by the team. Impediments to productivity caused by infrastructure are questioned and recorded in retrospectives, with follow-up planning to mitigate them in the future.
This has created a noticeable preference for software infrastructure that is developer friendly. As a result, developers have more influence over infrastructure choices than in the past. Acceleration of feature delivery velocity forces efficiencies in the development process. Applied to data storage technologies, this provides an opening for new approaches that store and access transactional data in ways that minimize developer overhead.
As an example, this was the impetus behind the creation of non-relational databases like MongoDB. One of MongoDB’s foundational purposes is to “unleash the power of software and data for developers and the applications they build”. When data is organized in a persistent store in the same way that it is represented in an application, then it removes a mapping layer that “translates” between the application and database (literally called Object Relational Mapping).
Another explanation for the rise of the role of the developer has to do with the broader automation of infrastructure configuration and the ability to “self-provision” their own hosting environment. With cloud-hosting, a developer no longer needs to “request” a database. They can just pick their flavor and spin one up. This ability self-provision removed the “gatekeeper” function that DBAs previously held. Granted, most engineering organizations will have standards in technology selection, but developers have become much more informed and adept at making the case for their preferred technology.
With new tooling, a consolidation in development frameworks and code sharing between front-end and back-end functions, the role of a full stack developer emerged. While it is rarely fully realized, the idea is that a single developer can be proficient in the programming languages and frameworks needed to create the code for all aspects of an Internet software application. Primarily this implies writing the code that handles the UI, business logic and data access. However, a secondary responsibility is often to manage the hosting environment. This requires some familiarity with DevOps practices, server provisioning and configuration management. On the data layer, this involves working with databases, caching servers and block storage. With modern cloud-based hosting environments like AWS, most of this provisioning can be accomplished through a UI or simple APIs.
Finally, software development teams began organizing around user experiences or feature sets, sometimes referred to as agile teams or tribes. These teams were often empowered to make their own decisions regarding application architecture and software infrastructure. In some large IT organizations, they are provided a list of “approved” technologies, but this list is usually large and fluid, allowing for many options to find the right tool for a particular need.
This influence of the full stack developer has made more options available for infrastructure selection. With different database types available at the click of a button, the developer is free to pick the best tool for the job. This has dramatically broadened the aperture of technology solutions, creating large niches for specialists to occupy. For the $60B+ data storage market, this means that there can be many viable commercial players.
As micro-services gained traction, software engineering groups began organizing their development teams around them. This meant that engineers were no longer grouped together by specialty, rather they were assigned to features teams that focused on a particular functional area. The functional area mirrored the responsibilities of the micro-service. Examples might be the supply, ordering or recommendation services. This partitioning of teams further encouraged the selection of different software infrastructure components for each micro-service.
The autonomous role of the developer means that technology providers with a developer-first mindset will dominate. Surveys of developer preferences for a technology often provide a view into future market share. Stack Overflow provides an example with their annual developer survey. MongoDB has been named the “most wanted” database by developers in the survey for four year in a row. In many ways, this could be the single most important indicator of MongoDB’s (the company) future growth potential.
Demand Drivers
As enterprises embrace digital transformation, they will build new software applications that deliver modern user experiences to both consumers and employees. Each software application requires a transactional data set and increased adoption will grow capacity needs. Data sets and storage solutions will expand. While many investors have been focused on what this means for the analytics platforms, like SNOW, PLTR, AI (OLAP type workloads) there will be a similar acceleration of demand on the transactional side (OLTP).
COVID was certainly a driver of the urgency for enterprises to replace offline processes with digital experiences. Rather than going into a crowded restaurant or grocery store, we can just place a food order online and have it delivered to our home. Similar adjustments have occurred in document signing, health care, fitness, media consumption and shopping. While COVID will abate at some point, these transformations will persist. The reason is that in most cases they are better experiences for consumers – more convenient, less time, better service.
In addition to the growing demand for digital experiences, the supply side is increasing as well. By supply, I mean is that it is easier than ever before to stand up a new web or mobile application. The time from idea to working application is shorter than it ever has been in the history of software development. This is driven by the increasing productivity of developers, as a result of better tooling and automation. With open source frameworks, collaboration tools, a rich ecosystem of APIs for common functions and ready-made hosting environments on the cloud, development teams can generate new digital experiences almost on demand.
Individual developer productivity and autonomy has raised their influence within the software engineering organization. Infrastructure as a service reduces the engineering team’s reliance on system specialists (like sysadmins or DBAs) to provision hosting resources and act as gatekeepers to new development. The rapid growth in options and complexity for software tooling and services have also promoted developers to an active role in the technology selection process. A CTO/CIO today is challenged to maintain fluency in all the different tech stacks, tools and frameworks available. Therefore, they often lean on developers or software architectures to make recommendations.
This means that developer preferences for tooling often influence technology choices and will drive usage for new and better solutions over time. The days of steak dinners for CTO/CIOs to land a technology sale are over. Developers often short-circuit this process by downloading competing vendor options for tooling, comparing them in real-time and making a recommendation based on their preference and hard data. Because hosting is readily available, they even spin up a quick proof-of-concept on their personal cloud account or in the company’s dev environment.
For data storage, this means that the technologies preferred by developers will continue to supplant legacy solutions that rely on executive relationships or heavy professional services to utilize. The popular developer site Stack Overflow conducts an annual survey in which they ask 65,000 developers about their preferences across a number of technology types. Included is input on programming languages, frameworks, tools and platforms. Transactional data storage solutions are covered in the Databases category.
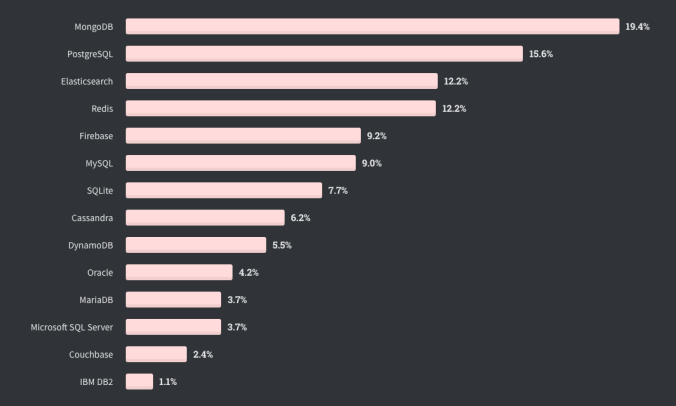
The most recent survey was conducted in February 2020. Developers rank MongoDB as the most “wanted” database for the fourth year in a row. This reflects developers who are not working with the database, but have expressed a desire to use it. Elasticsearch, which addresses a narrower set of use cases (but is the only search solution on the list), is ranked third. Products from the hyperscalers and legacy software vendors are much further down the list.
As customer interactions with enterprises increasingly occur over digital channels, expectations for the quality, performance and personalization of those experiences will continue to rise. Companies will apply the same energy to curate rich and unique customer experiences in their digital channels as they did in physical locations. They won’t be able to install an off-the-shelf software package with little customization and effectively compete. This implies that companies will need to develop bespoke customer experiences to distinguish themselves in a crowded digital marketplace. Every company of the future must become a software builder to win.
Jeff Lawson, the CEO of Twilio (TWLO), was recently interviewed on CNBC to discuss his new book Ask Your Developer. According to Lawson, we are embarking on a Darwinian struggle among companies to compete in the digital age. Customers expect to engage with every type of company through digital channels and every company must go through a transformation to enable them. The companies that figure out how to innovate by leveraging software will thrive. Those that can’t will become obsolete.
From banking and retail to insurance and finance, every industry is turning digital, and every company needs the best software to win the hearts and minds of customers. The landscape has shifted from the classic build vs. buy question, to one of build vs. die.
Developers are the creative workforce who can solve major business problems and create hit products for customers — not just grind through rote tasks. Most companies treat developers like digital factory workers without really understanding what software developers are able to contribute. From Google and Amazon, to one-person online software companies — companies that bring software developers in as partners are winning.
Jeff Lawson, Ask your Developer
This isn’t just the digital natives. It applies to every company in the Global 2000. From restaurant chains enabling online ordering to personalized automobile delivery to remote fitness training, companies are increasingly moving customer touch points online. Even old cable companies, like Comcast, are leveraging technology to improve customer experiences. They recently leveraged Twilio’s video API to allow customer service reps to troubleshoot a cable delivery issue remotely. While this was COVID driven, I can imagine customers preferring this type of on-demand service to scheduling an on-site appointment in the future.
Even e-commerce trends reflect increasing preferences for digital channels versus physical stores. Mastercard SpendingPulse recently reported that online sales were up 49% year/year for the holiday shopping period from October through December 2020. E-commerce sales now account for 19.7% of all retail sales, up from 13.4% last year. Again, while COVID forced some of this, the convenience of online ordering and delivery will likely make this growth persist. Even after COVID, consumers won’t want to spend a day at the mall completing their shopping list.
Independents like Etsy are grabbing significant share as well. One analyst recently commented that Etsy’s “growth is defying gravity” and that web site traffic for November-December almost doubled from last year. Shopify is experiencing similar growth, as are a whole host of other smaller vendors.
Bloomberg reported in September that Chipotle expected digital sales to reach $2.4B in 2020, which is more than double the $1B in 2019. The CEO anticipates orders placed online and through the Chipotle mobile app to represent 40-50% of all sales going forward. These orders are primarily for carryout and offer patrons the convenience to skip the line and have their food waiting for them when they arrive. Even as in-person dining has returned, the CEO expects digital business “is going to stay around.”
Chipotle built both its web site and mobile app in-house, using agile methodoligies and a custom tech stack hosted on Microsoft Azure. For the most recent Q3 quarterly report, digital sales increased over 200% year/year. In November, Chipotle announced that they will open their first digital-only kitchen. The new concept is unique because it does not include a dining room or front service line. Guests must order in advance through Chipotle.com, the mobile app or third-party delivery partners. This concept will allow Chipotle to enter new urban areas that wouldn’t support a full-sized restaurant.
“The Digital Kitchen incorporates innovative features that will complement our rapidly growing digital business, while delivering a convenient and frictionless experience for our guests,” said Curt Garner, Chief Technology Officer of Chipotle. “With digital sales tripling year over year last quarter, consumers are demanding more digital access than ever before so we’re constantly exploring new ways to enhance the experience for our guests.”
Chipotle press Release, November 2020
Many other restaurants have ramped up digital experiences in the past year as well, building custom solutions for their customers. Examples include not just Chipotle, but Panera, McDonalds, Chick-fil-A and Starbucks.
As we examine this growth of digital experiences, they are almost all powered by custom software applications. Companies like Etsy, Shopify, Peloton, Chipotle, etc. employ hundreds or thousands of software developers to build these experiences. This doesn’t just apply to external customers either. Many companies are extending the same digital transformation capabilities to enhance experiences for their employees. This may involve building internal applications for information sharing, operational improvements or better communications.
Even for smaller businesses that can’t afford to hire developers, they are still moving experiences online by leveraging SaaS providers in their channel. For example, Instacart provides a powered-by grocery shopping experience for many chains and DoorDash provides food delivery for many small restaurants. Other providers like Menufy allow a restaurant to seamlessly transition a customer from the restaurant’s own web site into a branded ordering interface. This makes ordering and pick-up easy, versus calling in a to-go order and paying at the restaurant.
All of these digital services have a custom software application behind them. Given that developers are building these, they are choosing their preferred solutions for data storage. This is driving demand for transactional data providers across the board, which applies to both the hyperscalers and the independents. Looking at a few different business categories, we can find examples of data storage provider usage in these software stacks. I will primarily focus on the independents, as that is where I think the biggest opportunity lies for investors.
Many popular food delivery and grocery ordering services use Elasticsearch to power product search capabilities for their apps. Some examples include Instacart, Grubhub, HappyFresh, HEB and Just Eat. In these cases, the organization of restaurant, food and grocery data into a reverse index on product facets (type, location, cost, brand, size, etc) allows for high performance queries against a combination of user selections. Full text search also enables the retrieval of a restaurant or brand name by typing just a few letters.
Online gaming platforms are increasingly using MongoDB for data storage, due to its flexible schema and high read performance. Examples are SEGA HARDlight, EA FIFA Online, Square Enix, FACEIT and Lucid Sight. A document store allows game developers to manage data structures within the gaming application in a way that mirrors their reference patterns. For example, a player’s character may have a variety of attributes (skills, weapons, levels, descriptions, etc.) that are unique to that character. It is easier to store all these attributes in one semi-structured document referenced by the character ID, than trying to rationalize a relational table structure to store all these fluid attributes.
Looking specifically towards the future of gaming, Zubair has a few thoughts for any developers considering MongoDB for their next project. “I’m a big fan of a NoSQL style database for at least games in general. I think games benefit from MongoDB’s flexibility because changes are quite frequent and relying on rigid schemas just isn’t practical. MongoDB is a big time saver in that respect, especially for gaming. I’d say, do it.”
Fazri Zubair, CTO of Lucid Sight
As another example, the popular gaming platform Roblox uses several non-relational data stores, including CockroachDB, MongoDB and Elasticsearch. Developers on the cross-platform Unity game engine have the option to utilize MongoDB as an external data store. Use cases include storing a leaderboard and sharing player scores or inventory across multiple games.
According to event streaming platform provider Confluent, Kafka has been adopted by nearly two-thirds of the Fortune 100. Businesses across financial services, retail, automotive and others are making event streaming a core part of their businesses. Large banks in particular have been adopting Confluent as the core component of their data streaming architecture for analytics, fraud detection and event monitoring. Customers include Capital One, JPMorgan Chase, Nordea Bank, Morgan Stanley, Bank of America and Credit Suisse.
At Kafka Summit 2020, Leon Stiel, Director, Citigroup, talked about how the company is tackling its data challenges and using event streaming to drive efficiencies and improve customer experiences.
Gone are the days of end-of-day batch processes and static data locked in silos. Financial institutions and fintech companies need to see their business in near real time, with the ability to respond in milliseconds—not hours. They have to integrate, aggregate, curate, and disseminate data and events within and across production environments, which is why Apache Kafka is at the epicenter of seismic change in the way they think about data.
Some industry analysts have tried to size the database market. IDC identifies the database market as being the largest in all of software – $64B spent in 2019, estimated to grow to $97B in 2023, or about 50% over 4 years. According to Allied Market Research, the “NoSQL” segment of databases should grow faster than relational. For 2018, they estimated the NoSQL market was valued at $2.4B. They see that growing almost 10x to $22B in 2026, for a CAGR of 31%. Within that category, key-value stores and document stores will be the largest segments. MongoDB is an example of a document-oriented data store.

I think the key take-away for investors is simply that the acceleration of personal, customer and employee experiences into digital channels is driving the creation of new software applications. These are increasingly being built from scratch, versus pulling commodity software off the shelf. At the core of these bespoke software development projects are developers, who are empowered to drive technology selection. New application architectures, like micro-services and edge compute, are driving an expansion in data storage options. In most cases, the development team building the new digital channel is free to select the best technology solution for their data storage use case.
These trends are increasing the demand for transactional data stores (as well as analytical). The companies providing data storage solutions will thrive in this environment. A bias towards multi-cloud deployment flexibility favors independent technology providers, providing large pockets of market demand outside of the hyperscalers. Several of those independent providers are publicly traded companies or private with aspirations to go public soon. As investors, we should be aware of these names and consider them for inclusion in a blended portfolio that harnesses the secular trend towards digital transformation.
Investment Opportunities
Besides Stack Overflow, another indicator of data storage engine usage across all categories is provided by DB-Engines. They maintain a ranking of popularity of solutions on their web site, with an overall score and an indication of change over time. This is constructed from a combination of inputs pulled from various public forums, discussion boards, web sites and job postings. It provides a reasonable indicator of overall usage and change over time.

Using this list, I pulled out the independent companies that offer a popular data storage solution for application transactional data workloads. These are either publicly traded or private companies that may approach the public markets in the next year or two. These are the most relevant for investors in my opinion. I will provide a brief summary of each in the next section.
I excluded the legacy software vendors from this list, like Oracle, IBM, etc., as I don’t view these providers as growth opportunities for investors. The DB-Engines rankings generally show a reduction in popularity for these solutions. Also, I excluded the data storage services from cloud hyperscalers, like AWS, Azure and GCP, for reasons discussed earlier. While these are great companies, I think focusing on the independents will yield more potential upside (and risk to be fair). Finally, I won’t speak to the popular open source database solutions that don’t have a leading commercial entity behind them, like MySQL and PostgreSQL.
It is interesting that the top 3 data storage solutions in the DB-Rankings are rapidly dropping in their popularity scores. Oracle represents a solution that is embedded in large, legacy installations, where the cost to migrate out is high and has been postponed. I can’t think of any examples of next-gen Internet software developers that are choosing Oracle as their database storage engine. The second position is held by MySQL, which is a popular open source relational database solution, maintained by Oracle. PostgreSQL is a comparable option and is gaining popularity among developers. Many engineering shops are selecting PostgreSQL for new applications. Finally, Microsoft SQL Server has the third spot. SQL Server is still a popular data storage technology, but most shops that want to utilize it are implementing the cloud-hosted version on Azure, called the Azure SQL Database (which is at position 15 but growing rapidly).
The big take-away related to the top 3 positions is the magnitude of their installed base, but decreasing popularity going forward. This seems to provide a large opportunity for the smaller, but growing, solutions as they gain in popularity. I will cover the background and performance data of the solutions that I think represent an opportunity for investors briefly below.
One last note – any conversation about data these days has to include Snowflake. Currently, Snowflake’s focus is primarily around enabling analytics workloads (OLAP) and their user audience is analysts and data scientists. Snowflake wouldn’t be a reasonable choice to drive a transactional data store that consists of a high volume of reads and writes for raw application data (OLTP). Developers look to other data storage solutions for these workloads. The latest DB-Ranking results show Snowflake at position 37, behind competitors like Redshift, BigQuery and Teradata. However, they were in position 107 a year ago, so their popularity trajectory is impressive.
Snowflake has shifted from branding themselves as a data warehouse to a cloud data platform, which somewhat blurs the lines around workloads. They also represent that data sets created through Snowflake processing can be fed back into user-facing application experiences, most commonly as analytic summaries or visualizations. Still, these use cases would not replace the transactional data storage solutions connected directly to popular web or mobile apps. Also, Snowflake management has made it clear that they don’t plan to build add-on services for categories like security or observability themselves. Rather, they want to stay focused on selling compute, storage and data transfer. Even reference architectures in their developer resources section recommend an OLTP data store in front of Snowflake to “provide the application with high-capacity transaction processing.”

Regardless, the expanding influence of Snowflake is disrupting the data storage and processing ecosystem. A “global platform for all your data and all your essential workloads” allows for a lot of future opportunity. Near term, they have plenty of playing field in soaking up all data warehouse and analytics spend. On earnings calls, Snowflake leadership mentions displacing hyperscaler solutions (Redshift, BigQuery) and legacy independents like IBM Netezza, Teradata and Oracle Data Warehouse. Long term, Snowflake is a player to watch and might even acquire a transactional data storage provider to expand their reach.
MongoDB (MDB)
MongoDB probably represents the largest independent document database opportunity. It is publicly traded under the ticker MDB and I have provided extensive coverage of the name in the past. MongoDB occupies the top spot in Stack Overflow’s survey of Most Wanted databases and 5th position for most popular data stores on both Stack Overflow and DB-Engines.
MongoDB is a document-oriented database that falls in the broader category of non-relational or NoSQL. As opposed to a traditional relational database, MongoDB allows for a flexible schema. This means that new data types can be introduced and stored in documents without requiring a table ALTER. This, of course, limits the ability to join documents across any data field, like the join of multiple tables in a relational database. Document retrieval against a primary key, like an ID, can be executed very fast.
This trade-off in flexibility of schema versus retrieval performance for all data elements is well suited for certain types of workloads. These represent cases in which a data entity may be identifiable at a discrete ID level, but have many types of data descriptors that vary between records and don’t require querying or grouping. Examples of this may be a user profile or a product description. Document-oriented stores allow new information about a data entity to be easily appended to the existing record, ideally where that new data doesn’t need to be “related” to data in other records.
As discussed previously, micro-services allow the selection of the ideal data storage engine for each application function. It is often the case that an engineering team will select a relational data storage engine, like PostgreSQL, for one micro-service (let’s say payment transactions), and select a semi-structured data storage solution, like MongoDB, for another (let’s say a character profile in a game).
MongoDB (MDB) the company offers a packaged version of the core MongoDB open source solution with a number of proprietary add-ons. These include additional features for cluster management, mobile app development and visualizations. Their software business is based on the open-core model. The software package is licensed under the SSPL , which limits the ability for another commercial entity (like the hyperscalers) to offer the same version of MongoDB as a hosted service on their cloud. While AWS has a MongoDB compatible offering, it is pinned to an old version of the software.
MongoDB’s growth really stepped up when they began offering their MongoDB package as a managed solution on the cloud platforms. This is called MongoDB Atlas and is currently available on AWS, Azure and GCP. Atlas is particularly appealing to development teams, as they get access to all the features of MongoDB in a package that is easily accessible from their existing cloud location. MongoDB provides a distribution for enterprises that want to self-host on the cloud or in their own data center.
The biggest recent development with MongoDB Atlas has been the addition of support for multi-cloud clusters on Atlas. This allows an Atlas cluster to span multiple cloud vendors. Data written from an application on any cloud instance is automatically replicated through the cluster and across cloud providers. This really steps up the multi-cloud appeal, as a development team could choose to utilize MongoDB and not have to worry about changing data access patterns between cloud vendors, or being trapped on one cloud solution due to data gravity.
MongoDB went public in October 2017 at a closing price of $32. It recently traded for $361. Its market cap is about $22B with a P/S ratio of 38. Their most recent earnings report was on December 8th for Q3 (Oct end) FY2021. MongoDB outperformed expectations. Revenue growth was 37.8%, roughly inline with Q2, and ahead of analyst expectations by 11%. Q4’s revenue target was raised by 8% for 26% growth. While these numbers are down significantly from the prior year, COVID related IT spending slowdowns did have impact.
MongoDB Atlas (the cloud offering) grew revenue by 61% year/year and now makes up 47% of the total. This is down from 66% in Q2, but still well above overall revenue growth. Leadership contends that Atlas demand is driven by new customers, versus migrations from on-premise licenses. The new multi-cloud offering should increase interest in Atlas.
Profitability, on the other hand, showed only slight improvement in the prior quarter. MongoDB leadership talked about investing for the large opportunity ahead on the earnings call. For Q3, Non-GAAP gross margin was 72%, which was inline with a year ago. Operating margin was -10.6% versus -13.0% a year ago and -7.4% in Q2. On an absolute basis, operating loss was greater this year. This translated into Non-GAAP EPS of ($0.31) versus ($0.26) a year ago and analyst estimates for ($0.44).
Customer growth was strong, with particular interest in Atlas. MongoDB added 2,400 customers in Q3 for a total of 22,600 customers. This was up 42% year/year and 12% sequentially. Atlas customers made up the majority of these, at 2,100 of the additions and nearly 49% annual growth. Customers spending over $100k in ACV was up 31% year/year and 10% sequentially. Customer growth for Atlas was cited by several analysts as a strong indicator of future revenue acceleration, as we look to performance in 2021.
Elastic (ESTC)
Elastic is a search company. Over the years, the notion of search as applied to internet-based software companies has evolved significantly. From a foundation in basic text search, the types of data processed expanded to products, locations, statistics, user profiles and more. The same core search technology could be applied to all these data retrieval use cases. Example use cases include product facet search (shopping), profile matching (dating), content recommendations (video streaming), geographic proximity (mapping), etc.
The core of the search capability is based on Elasticsearch, which is an open source search and analytics engine that can handle all types of data including text, numerics, geospatial and unstructured. It is built on Apache Lucene, which is a set of code libraries written in Java that implement indexing and search functions. Elasticsearch provides the server runtime that wraps the core libraries and handles data ingestion, enrichment, indexing, storage and retrieval.
The Elasticsearch data storage model is based on an index, which is a collection of documents that are related to each other. Elasticsearch documents are stored as JSON, consisting of a set of keys with their corresponding values. Elasticsearch organizes documents into an inverted index, which facilitates very fast search retrieval. An inverted index creates a relationship between every value of a designated key and the set of documents that contain that it. The indexing process as part of data ingestion builds this inverted index to make the document set searchable in near real-time.
This technology has been deployed by customers to support all kinds of application data retrieval use cases that are associated with a search function. Search in most applications isn’t strictly a text search. Rather, organizing data as a search index provides highly performant retrieval of matching records based on a combination of data value inputs. This is often leveraged for navigating product catalogs, finding similar matches and performing geolocation proximity. The returned results can then be scored based on a set of weightings and then ordered for the most relevant.
This technology has been applied at scale to many use cases in consumer apps that we use every day:
- Perform passenger / driver matches and marketplace operations for Uber
- Return potential dating profiles at Tinder
- Power in-store and online retail customer shopping for Walgreens
- Retrieve aircraft technical documents for employees at Airbus
- Locate relevant images, videos and documents for Adobe Cloud
Many of the search use cases above involve software development teams taking the core Elasticsearch functionality and applying it to data retrieval for their apps. Teams soon realized that Elasticsearch could be repurposed for other use cases that involve ingesting, indexing and retrieving large data sets of unstructured data. These included workloads like log analysis, APM, security, business analytics and infrastructure monitoring. The technologies provided by Elastic are able to support all of these functions. Over time, the Elastic team built pre-packaged solutions to support clusters of these use cases around observability, security and of course, its core in enterprise search.
To address all of these types of search experiences, Elastic created the Elastic Stack. Specifically, the stack is composed of Elasticsearch, Kibana, Beats and Logstash. It allows developers to take data in any format from any source, and then transform, index, analyze and visualize it in a rapid and scalable manner.

The Elastic Stack is open source. This means that all the source code is publicly available for developers to view and extend. They distribute code under the Elastic license and recently added support for SSPL. Like MongoDB, the license includes restrictions on other commercial entities offering hosting of the open source package (like the Amazon Elasticsearch Service). From the perspective of Elastic and MongoDB, these restrictions are fair, as their employees contribute the vast majority of code to these projects at this point.

Elastic’s solutions can be deployed in three different configurations, depending on customer preferences and their existing infrastructure foundation. Traditionally, customers self-hosted and managed the Elastic Stack themselves. Elastic’s Cloud offering is newer and provides a managed service for customers on all the major cloud hosting providers. This option is becoming particularly popular for customers and is financially beneficial for Elastic, as they generate revenue even if the customer is using the “free” version of the Elastic distribution. This varied deployment model provides customers with flexibility in their hosting approach and recognizes that many enterprises haven’t fully migrated to the cloud (nor immediately plan to).
Elastic is publicly traded under the symbol ESTC. It went public in October 2018, closing at around $70 per share. It recently traded at about $163, with the majority of its growth in the last year. It has a market cap of about $14B and a P/S ratio of 26, reasonable as compared to peers with revenue in the low 40% range and a similar margin profile.
Elastic’s most recent earnings report was released on December 2nd for Q2 FY2021 (Aug-Oct). The Q2 results were well ahead of analyst expectations with revenue growth of 43% year/year, versus expectations for 29%. This growth was nearly linear to Q1’s performance, demonstrating that the deceleration of revenue growth over the past year may be stabilizing. Additionally, Q2 revenue increased 12.4% sequentially. Calculated billings grew 42%, and both deferred revenue and RPO were up over 50% year/year. These metrics all provide confidence that revenue growth in the low 40% range should be sustainable.
Even more encouraging was that profitability measures are improving with revenue growth. This had been an investor complaint in 2019, as Elastic grew revenue at a higher rate, but reflected little leverage on the bottom line. Non-GAAP gross margin approached 77% in Q2, and was up over 2% year/year. Operating margin nearly reached break-even at -1%, versus -18% a year ago. Looking towards next fiscal year, the CFO is projecting positive FCF margin.
Customer growth also reflects continued adoption of the Elastic solution. Total customer counts increased by another 800 to 12,900 in Q2. Incidentally, Elastic has added roughly 800 new total customers in each of the last 4 quarters, indicating that they are not experiencing competitive disruption and that platform demand is continuing through COVID. Growth in customers spending over $100k in ACV has slowed for the last two quarters and is up just 24% y/y in Q2. We will want to watch this metric, but the slowdown does align with leadership team commentary around extended sales cycles and additional approvals needed for larger deals (also mentioned by competitors like Splunk).
On the product front, Elastic continued its rapid release cadence. Over the last 6 months, the development team has pushed out 4 major version updates (7.7 – 7.10). Each of these was packed with new features, further building out their offerings across observability, security and enterprise search. This feature completeness in multiple categories is driving large customers to adopt multiple solutions. At Elastic’s Analyst Meeting in October, they revealed that over 75% of customers spending >$1M ACV were utilizing two solutions or more.
Also in mid-October, Elastic held its annual user conference ElasticON. The event consisted of over 300 sessions and attracted over 25,000 attendee registrations. Most interesting to me were the customer presentations, which revealed the depth and breadth of use cases for the Elastic Stack within customer organizations. Several customers highlighted the advantage of programmability and openness, allowing them to create customized solutions in observability and security to meet their company’s unique requirements.
Cloudflare (NET) and Fastly (FSLY)
While the vast majority of application workloads and their data are located in central data centers, the demand for better app performance (further exacerbated by 5g) is driving new software architectures that seek to move application logic in closer proximity to end users. Doing so reduces the round trip latency of sending a user’s request across the globe in order to service it. If logic can be distributed to POPs (Points of Presence – like small data centers) located in every country and near population centers, then some portion of application workloads can be serviced locally.
This model of proximity delivery started with static content. Most readers are familiar with the model of a CDN (Content Delivery Network), which caches files that change infrequently in POPs close to users. This content has traditionally been images, video files, some browser code modules and other content that is readily cacheable. User requests for this type of content are then directed to the closest POP versus traveling back to origin. This model dramatically sped up Internet application performance in the early days.
The next opportunity to improve application performance is to move server-side logic to run in distributed POPs. This achieves the same benefit as a CDN, but is much more complex to execute. It requires creating a full development environment and distributed runtime that allows code to be written, deployed and executed in all POPs simultaneously. In order to make this model scale, the runtime environments have to be distributed, shared and secure. These requirements are best met through a serverless hosting architecture, which provides an isolated runtime environment for a developer’s code to execute in response to a request.
This spawned a new trend referred to as “edge compute”, which effectively provides the mechanism to move application code processing (compute) to a globally distributed network of small data centers (the edge). Commercial entities began offering edge compute solutions to enable development teams to take advantage of this new paradigm, including the hyperscalers and legacy CDN providers.
AWS offers their Lambda@Edge product for edge computing. This is an extension of Amazon Cloudfront, which is their CDN service, and AWS Lambda, which provides Amazon’s serverless solution. In a similar approach to Amazon, Microsoft Azure offers edge computing (called Intelligent Edge) through the use of Azure Functions, which can be deployed on Azure, Azure Stack (a managed physical appliance) or Azure IoT Edge. Google supports serverless runtimes through their Cloud Functions.
Akamai launched their EdgeWorkers product in October 2019. This solution is based on the V8 Engine and currently only supports JavaScript for development. The product is in private beta for existing customers, requiring a sign-up form and review to utilize.
With that said, I think the most advanced products for edge compute from a publicly-traded independent provider are being offered by Cloudflare (NET) and Fastly (FSLY). These two companies are demonstrating the most focus and innovation around building a distributed serverless runtime environment, with all the necessary supporting developer tooling.
Cloudflare offers edge compute through their Workers product. This has been available to customers since early 2018. Workers provides a distributed runtime that executes developer code in parallel across Cloudflare’s network of over 200 POPs spread across 100 countries. Cloudflare built their solution on the Chromium V8 Engine. This allowed them to leverage the work already done by the Google Chrome team and get a product to market quickly in 2018.
With Workers, developers can create code modules that run on request or scheduled via a cron service within their distributed serverless environment. Due to its foundation in the V8 Engine, Workers can run JavaScript, along with a plethora of other popular languages that can be complied to JavaScript. Workers provides developers with tooling to write, test and deploy their serverless functions.
Adoption of Workers has been strong. On the Q3 earnings call, Cloudflare’s CEO announced that more than 27,000 developers wrote and deployed their first Cloudflare Worker in the quarter, up from 15,000 in the prior year’s Q3. Cloudflare has been rapidly adding features to the Workers offerings, hosting a stand-alone Serverless Week in late July 2020 and launching a new data storage engine Durable Objects in early October.
Fastly, on the other hand, offers a globally distributed, serverless compute runtime through their Compute@Edge offering. With the Q3 earnings report, Fastly announced that Compute@Edge has moved out of beta and into a limited availability status. Access is still limited to a finite set of customers, but does reflect that they are running production workloads on it.
Fastly chose to build their own runtime in Lucet (versus leveraging the V8 engine), which they have heavily optimized for performance, isolation and resource utilization. However, this required constraining the compiler and runtime to only running a WebAssembly binary. This reduces support for languages to the few that currently have a compiler for WebAssembly, like Rust, C, C++ and AssemblyScript. The trade-off is that Lucet has faster cold start times and a much smaller memory footprint than runtimes based on V8.
I have compared the two serverless solutions extensively in prior blog posts. Suffice it to say, both Compute@Edge and Workers have significant performance advantages over legacy serverless solutions. This has allowed both to be considered for synchronous workloads, where legacy serverless solutions were primarily relegated to offline, asynchronous jobs. This shift to synchronous requests dramatically expands the use cases for serverless, to being suitable for real-time web and mobile applications.
So, what does this have to do with data storage? Well, if edge compute moves more application processing out of origin data centers, then it stands that a subset of data storage would move with it. While data stored at the edge now is generally equated to a cache, providers are evolving to make it persistent and durable. This would allow developers to rely on it to store application data just as any other data store. The micro-services architecture already pushed the concept of breaking up a monolithic database into discrete data stores that use different storage engines to match the use case. This same model would apply to the functionality located within edge compute. The most critical application transaction data would likely still be pushed back to origin databases, but other types of persistent, but not critical, data like shopping cart contents or user session data would be suitable for storage at the edge.
Both Cloudflare and Fastly have evolving edge data storage solutions. For Workers, Cloudflare recently launched Durable Objects. This supplements their prior solution of Workers KV, which provides a distributed, low latency key-value store. Durable Objects takes this a step further, by allowing any set of data to be persisted with guaranteed consistency across requests. Objects can be shared between multiple application clients (users). This consistent and sharable data object storage enables many common use cases for multi-user Internet applications, like chat, collaboration, document sharing, gaming, social feeds, etc.
During the Compute@Edge talk at Fastly’s annual user conference Altitude, speakers made references to a future offering called Data@Edge. While this hasn’t been formally announced by Fastly, we can assume it represents a new distributed data store for use by the serverless runtime. Fastly has a basic local cache available for the existing VCL environment called Edge Dictionaries. Data@Edge would presumably take this to the next level, providing an eventually consistent, distributed data store with a CRUD-like data interface for developers to use.
While it seems counter-intuitive to include edge compute providers in a discussion about opportunities for investors to leverage the ongoing growth in transactional application data storage demand, the migration of compute and data storage from the origin to the edge implies that there could be a large future revenue stream for the edge compute providers. Gartner has predicted that by 2025, up to 75% of “enterprise-generated data will be created and processed outside a traditional centralized data center or cloud”. While much of the focus for edge-based distributed application runtimes has been on the compute workload and its migration out of the central data centers, the same trends would apply to data storage. Companies like Cloudflare and Fastly could be the future data storage solution providers. For more information on last quarter’s financial performance for these two companies, investors can reference this post.
Private Companies
While investing in publicly traded companies provides investors with an immediate outlet for leveraging trends in transactional data storage, there are a number of sizable private companies that we should monitor. The examples below are leaders in their category and have indicated intentions to IPO at some point in the future.
Confluent
Perhaps the most significant private company that influences modern data storage architecture is Confluent. Confluent was founded in 2014 by the original developers of Apache Kafka. As discussed in the event streaming architecture section previously, Kafka is an open source, stream processing software platform. Kafka can serve as both a data pipeline for handling large volumes of events and a persistent data store queried through SQL. In this way, applications can send event data to Kafka and can also pull processed data back from it. It is often used to collect data from multiple sources and feed it to back-end systems, including a data warehouse.

Confluent provides a complete distribution of Kafka packaged as the Confluent Platform, which improves open source Kafka with additional community and commercial features. This is offered as a both a self-hosted download and a managed service on AWS, Azure and GCP. Self-hosted customers can purchase a subscription to the Confluent Platform that provides access to commercial features and enterprise support. Cloud customers pay monthly based on their usage.
Confluent has assembled an impressive list of customers, including many members of the Fortune 500. In April 2020, Confluent raised $250M at a $4.5B valuation. At that time, Confluent had 1,000 employees and had grown revenue by 100% in the prior year. While an IPO date hasn’t been set, the hiring of a new CFO from Google Cloud in June 2020 fueled speculation that it was imminent. This IPO would be one for investors to watch closely and would provide an opportunity to add the leading event streaming platform to their data storage portfolio.
Datastax
Datastax built a proprietary version of the open source project Apache Cassandra. Cassandra is a non-relational database variant, specifically a wide column store. Data is stored in records with keys, but the number and names of columns for each row can vary and scale out to millions of columns. Wide column stores can be seen as two-dimensional key-value stores. Google Bigtable was the original wide column store.
Due to its structure, a wide column store can expand to store very large amounts of data. New data nodes can be added without reconfiguration. Originally for Google, this was how they stored the metadata generated from crawling every page on the Internet. Cassandra is used at some large Internet properties for a similar data storage pattern. Apple has an installation with over 75,000 nodes containing over 10 PB of data. Netflix reportedly has 2,500 nodes, 420 TB and processes over 1 trillion requests per day.
While these are impressive stats, Cassandra seems be losing mindshare. It was a popular option 5-10 years ago, as many of the larger Internet properties were scaling. However, the data model can be challenging to understand for the average developer and cluster management can be tricky. It is more suitable for large organizations that have sufficient staff to specialize and operate it. While I have used it at a past company, I don’t hear of many new software teams starting with a Cassandra implementation.
Datastax markets their proprietary version of Cassandra called Datastax Enterprise. They also offer Datastax Astra, which is a cloud-hosted, managed service for Cassandra. Datastax has an impressive customer list, including 40% of the Fortune 100. In March 2019, Datastax was reported to be preparing for an IPO, with about $150M in revenue growing about 30% a year. However, at the end of 2019, they changed out the CEO and went through several rounds of layoffs. They had brought in former Apigee CEO Chet Kapoor, who took that company public and later sold it to Google. Kapoor has re-focused Datastax on pursuing a cloud strategy and increasing developer evangelism.
It remains to be seen if Datastax can build back up their momentum. This would involve getting more traction with the Astra managed service and raising developer awareness. If they do this, they might be a candidate for a future IPO, or an acquisition for a legacy software vendor looking to extend their offerings.
Redis Labs
Redis Labs is the official sponsor of the open source project Redis. Redis is an open source in-memory data structure store, that supports a variety of data types like strings, sets, lists, hashmaps, geospatial indexes, etc. Developers can perform atomic operations on these data types, like appending to a string, incrementing a value, adding an element to a list or grabbing the highest element in a sorted set. Because the data store is in-memory, it is often used as a non-persistent, high-performance shared cache. Data can be stored to disk, but this process only allows the in-memory data structures to be recreated. Because the data store is schemaless, Redis is categorized with other non-relational (NoSQL) solutions.
Redis has add-on modules that expand its applicability to a variety of use cases. It can be used for data streaming, user session stores, time series data, distributed locks or geospatial applications. This has allowed Redis Labs to position Redis as more than a simple key-value store. Like other commercial entities with an open source project at the core, Redis Labs has built an Enterprise Software distribution for self-hosted customers and a managed cloud service available on AWS, GCP and Azure. Cloud vendors do offer their own Redis managed services (like AWS ElastiCache), but the distribution from Redis Labs includes all the enterprise add-ons which offers an expanded feature set and enhanced scalability.
Redis Labs was founded in 2011 by two co-founders who still lead the company. In August 2020, they raised $100M with a valuation just over $1B. They count over 8,000 paying customers, including The Gap, Staples, Redfin, eHarmony and several large credit card processors. Redis Labs generates close to $100M in revenue, growing at about 50% year/year for the past several years. They have strong working partnerships with Azure and Google Cloud. With the latest fundraising, the CEO thinks they will be ready to IPO in 1-2 years.
Algolia
Algolia is a search-as-a-service platform. It is cloud-native, with search results distributed via a global network of 17 regions. This improves the performance of response times, much like a CDN or edge network. Algolia does not offer a hosted version of the software. Its underlying engine is custom-built, not an extension of an open source package like Lucene. It was originally built for offline search in mobile phones and later ported to a cloud service.
Use cases for Algolia are primarily geared towards user-facing application search. It provides SDKs in many programming languages for collecting data and UI tools for incorporating the results into a web or mobile interface. Configuration of indexes, weighting rules, sorting order and other admin functions are performed through a SaaS-like UI. The source code is closed.
Algolia is a popular option for powering a site search or navigating faceted results. It provides a highly responsive type-ahead experience for a search box. It is very easy to get started with Algolia – a basic search experience can be enabled in minutes. Recently, they have focused on expanding the set of use cases, adding personalization, A/B testing and site analytics. Customers are charged on a usage basis. This translates into a count of “units” consumed per month. A unit represents 1,000 search requests on an index of up to 1,000 records.
For application search tooling choices, Algolia often competes with Elasticsearch. Like any technology choice, there are pros and cons for each, based on use case, developer time investment, pricing and type of organization. This Quora thread provides a reasonable comparison (which is even referenced from the Algolia web site and includes comments from Algolia’s CTO and co-founder). Advantages of Algolia are associated with ease of use, fast learning curve, response speed due to global distribution and UI plug-ins. Elasticsearch favors large data sets and query volumes (due to resource-based pricing model), offers more fine-grained controls and can be repurposed for other workloads like log analysis or analytics. Being open source, Elasticsearch code is open for inspection. In terms of popularity, Algolia is 53 on the DB-Engines rankings versus 8 for Elasticsearch and 20 for Solr.
Algolia was founded in 2012. They closed a funding round of $110M in October 2019 and brought on a seasoned CEO in May 2020. They have over 9,000 paying customers, including some large players like Slack, Stripe, Under Armour and Twitch. They are considering an IPO and set a target of $100M in ARR to start the process. By 2019, they reported passing the half-way mark with growth in 2018 doubling. If Algolia goes public, we will get more visibility into performance metrics and can get a sense for the investment opportunity.
Investment Plan
Demand for transactional data storage solutions will continue to grow, in response to the need for enterprises of all types to meet their customers on new digital channels. Changes in application architecture, cloud infrastructure and software development processes have broadened the aperture of opportunity for solution providers that can meet developers on their terms. In this post, I have reviewed these trends and identified several independent players that should benefit.
In my personal portfolio, I have positions in Cloudflare (NET), Elastic (ESTC) and Fastly (FSLY). I had a small position in MongoDB (MDB) last year and may re-open that in 2021 as growth resumes. Enterprises are generating huge amounts of data and the velocity is only increasing. Transactional data stores represent the entry point, attached to the ever growing number of user-facing software applications that make up digital transformation. This should provide a trend that investors can harness for many years.
NOTE: This article does not represent investment advice and is solely the author’s opinion for managing his own investment portfolio. Readers are expected to perform their own due diligence before making investment decisions. Please see the Disclaimer for more detail.


Wow, Peter, just excellent. And thorough. And very, very good. Rather than merely compliment you, though, I want to point out a few reasons why you deserve the plaudits…
* You take an arcane topic, with its own jargon, and pause to define or explain each acronym or seminal development so the lay-person can follow along and achieve some measure of understanding. Such an effort is not easy, not for the reader and certainly not for the writer, you. Which terms do you explain, which do you not? Which terms can you assume your readers know and do not know? How can you define and explain terms without impeding your narrative flow?
* You provide your commentary a palpable sense of narrative thrust, similar to a good novelist who writes a “page-turner.” I read this commentary at 2am and was not disgruntled for losing sleep. Yes, I read every word, it is that compelling; 3x now. In fact, your commentary was and is energizing – and I will bet (literally) ultimately rewarding. This is no easy feat for any writer and yet you achieved it easily, seamlessly. Congratulations!
* Your commentary rewards re-reads, which means re-reads are not a task but a pleasure.
Okay, enough praise. Me being me, I have questions.
01. Although not the focus of this commentary, you single out Snowflake as a force to reckon with in OLAP, with the possibility that the company could move into OLTP. Moreover, it *seems* you find no dominant player in OLTP; you identify four possibilities, all of which you praise but none of which you deign as a predominant force as you did Snowflake (in OLAP). So you spread your investment bets across Elastic/ESTC, Fastly/FSLY, and Cloudflare/NET, with MongoDB/MDB a possibility sometime this year. Do I understand you correctly?
02. JFrog/FROG seems worth a mention in this commentary – if only for its Liquid Software and Artifactory technologies. Neither tech is OLTP (as I understand it) but both seem at minimum tangentially germane to your commentary. Do I understand correctly? Do you intend to cover JFrog/FROG and Snowflake/SNOW with their own dedicated commentaries?
03. Wholly unrelated to OLTP. Alteryx/AYX announced early in the week a partnership with Snowflake that eases, I believe, your concerns about Alteryx’s future if Snowflake should decide to go after its business. Does this new partnership merit a 2nd look at Alteryx as a renewed investment opportunity? Or does the partnership usher in its own risks? Or…?
Thank you again for the excellent commentary above and in advance for your replies!
David
Thanks for the detailed feedback, David. I appreciate it. Here are some answers to your questions:
1. Yes. Independent OLTP providers all focus on a particular segment of the transactional database market with pretty clear lines between them, based on use case and data workload. It certainly would be interesting if a modern solution provider started spanning multiple types of OLTP data stores, but I only see the legacy providers (like Oracle) or the hyperscalers doing this. Regarding Snowflake, while they brand themselves as a data platform now, they are really a replacement for legacy and cloud-based data warehouse solutions. DW is a single large category in OLAP, so it makes sense that they dominate it. We just collectively have to keep an eye on Snowflake due to their momentum and size.
2. JFrog provides tooling for developers to create, manage and distribute the “artifacts” of code that make up a software application in production. This supports the pipeline of code management from development through production. So, you are correct, these tools would not be used as the data store for a software application (not an OLTP database provider). They use the term “database” to describe their store of these code artifacts, but its not the same as the context that the blog post covered. As FROG is a solutions provider for developers, it does fall into my coverage wheelhouse. I have been giving the stock some time to settle before doing a formal review.
3. I think the Alteryx / Snowflake partnership is a step in the right direction for Alteryx. But, it doesn’t alleviate all of my concerns. Alteryx will be a Snowflake Technology Partner, along with 20+ other companies. I still worry about the competitive noise. Additionally, beyond the relationship with Snowflake, I wanted to see traction on the product side towards a true cloud-centric delivery mode and more evidence of a “renaissance” for Alteryx before I re-enter a position. The CEO change could take this either way (too early to tell).
Regarding coverage of SNOW, I don’t think I can add anything to what Muji produced over at Hhhypergrowth. He and I try not to overlap too much on coverage. I would love to open a position in SNOW, but the valuation still seems excessive to me. I would like to see where revenue growth lands at the one year anniversary of IPO before I decide.
Thank you for your helpful and enlightening answers, Peter. I look forward to your commentary regarding JFrog/FROG.
As long as I have you on the phone, a selfish question, please, that has nothing to do with OLAP/OLTP (or FROG or SNOW, etc). In fact, you are the perfect person to ask my question…
Regarding the SolarWinds hack. As a citizen and consumer, NOT an investor, it seems to me this hack is very serious — although *I* cannot explain why or how. It seems to me the media struggles to convey how serious the hack is but lacks the terms to bring it home. It also seems like businesses and the US government have a … oh, I don’t know, a cavalier or flippant attitude about the hack. I would think that C-suite execs are shitting in their pants trying to figure out how to handle the hack. Perhaps I misunderstand the hack’s gravity, that it is not so serious?
From your perspective as a coder, programmer, C-suite exec, etc, how serious is the hack? Are proper steps being taken to remediate the hack? What should we unknowing consumers and citizens do – if anything?
I admit I do not understand investors’ fixation on Crowdstrike to remediate this hack because the intrusion already is well past the endpoints and into the guts of companies and the US government. Unless Crowdstrike has morphed and its tools can help? Shouldn’t the focus be on companies that focus their solutions on internal systems? And whatever the cyber-security software, how is it even used to rid systems of the SolarWinds hack? Is the process laborious and time-consuming? Or is it one-pass and done? And why does anyone think the known hack is the extent of the dirty work? Perhaps the true problem remains unrecognized and unknown?
On a separate and fun note…
“Twilio co-founder and CEO, Jeff Lawson, talks with CNN’s, Julia Chatterley, on why businesses must bring developers into the C-suite to thrive in a digitized world.”
https://twitter.com/jchatterleyCNN/status/1351627184453124101?s=20
An excellent 8 1/2 minute interview. Jeff is, as Julia states, quite “sparkly”! 🙂 Worth watching.
Sure thing, David. Feel free to email me directly with other questions at analysis@softwarestackinvesting.com. The interface on the comments board can get cumbersome after a few exchanges.
On the SolarWinds hack, yes, it is serious. Previous breaches involved a single company. With this hack, the attacker was able to get their malicious code into a patch that was distributed to all SolarWinds installations. That expanded the surface area of affected companies. Also, it highlights the extent to which these bad actors are willing to go, which I think heightens the risk level across the board.
While Crowdstrike doesn’t specifically protect the software update process, it would mitigate any further damage to an infected company’s systems from lateral movement. And, again, the whole sector is at higher risk, so all security companies are benefitting. While this hack was associated with software updates, the next hack might try a different tactic.
Thanks for the link to the Lawson interview. I actually bought his book “Ask Your Developer” and am working through it. I think it underscores the big opportunity for the “picks and shovels” companies that provide tooling and infrastructure for building software applications that drive new digital experiences. That is the premise of his book – that companies of all types will differentiate themselves in the future through custom software development.
Hi Peter,
Thank you for all the work you are doing! There are a couple things I don’t understand in your reply to dmg. One is the “expanded the surface area of affected companies.” Does “expanded surface area” apply to the number of affected companies or the extent or something else? You noted that CRWD would “mitigate any further damage to an infected company’s systems from lateral movement.” Does that mean that CRWD is able to isolate and contain damage once it is within an infected company’s system? Thank you for any clarifications. ~ Ilene
Hi – thanks for the feedback. Regarding the expanded surface area of affected companies, I was referring to the fact that the bad actor was able to leverage an exploit with one company (SolarWinds) to gain access to a broad set of other entities (SolarWinds customers). Normally, bad actors have to pick on one target at a time. Regarding CRWD, when a bad actor gains access to a single system/server within a target’s network, they try to “move laterally” and gain access to other systems on the network. Crowdstrike and others have endpoint protection and monitors in place that would flag unusual signals of the lateral movement and block them.
Thorough and enjoyable as always
Many thanks !!
When is the movie coming out?! Great stuff.
As usuall, thanks for the detailed write up. Its awesome to be invested in these companies especially given the tailwinds cited in the article particularly elastic. What are your thoughts to elastic changing its licensing model: See announcement from shay banon:
https://www.elastic.co/blog/why-license-change-AWS
It appears the change was in response to amazon. I was surprised to hear that amazon launched amazon elastic without informing elastic and they have been profiting for this for over 3 years. Elastic actually sued amazon. Not sure what the outcome was.
2nd question: Beth kindig made some arguments in the video below(skip to 14:00) on why she thinks fastly and net will not win the edge computing space citing quantity of cdns by other OEMs like amazon and akamai. What are your thoughts?
https://youtu.be/JKEP9D-AuZY
Thanks
Thanks for the feedback. Regarding Elastic’s license change, you are correct that the impetus was to counter competition from the hyperscalers, primarily AWS. The Amazon Elasticsearch offering created confusion in the marketplace and essentially re-purposed the investment Elastic made in the product for their own commercial gain. I was happy to see this move by the Elastic team. As a shareholder, I think the upside is to close a competitive loophole. Potential downside may be fewer new start-ups building their infrastructure on top of Elastic, which has been a good source of acquisitions. However, I suspect Elastic will still make efforts to promote that type of cooperative activity.
Regarding the Motley Fool podcast, I thought it was a fair and balanced discussion. I generally agree with the points made. I think the challenge for investors is that the “edge compute” landscape is potentially very large and there will be many winners. Rather than focusing just on the furthest network edge, like locating hardware in cell towers and on factory floors, we should think about the opportunity for moving compute and data out of origin data centers. The “edge” in this context is any place between the end user and the origin, where a performance benefit will be realized by locating some compute and data storage.
There will be a wide variety of use cases. For many, like IoT, industrial, autonomous vehicles, remote surgery, etc. the hyperscalers and cellular networks will dominate. That seems to be where they are focusing and will be an enormous opportunity. However, I think there will also be a large market to provide distributed, serverless environments for running code and storing data closer to the end user of standard Internet applications. Customers of this market would be the same set that heavily use CDNs now, like in e-commerce (Shopify, Etsy, Wayfair), media distribution (Spotify, Fubo), payments (Stripe, PayPal), etc. As edge compute becomes available, these same types of Internet “content” services will move compute and data out of the central data center. This will represent new spend for edge compute providers. As an example, all the companies I listed as examples are Fastly and Cloudflare customers. It would only make sense that they would also take advantage of computing at the edge. Since Fastly and Cloudflare won this CDN and basic routing business while Akamai and the hyperscalers were fully scaled up, I don’t see why or how their focus and technology advantage for these use cases would suddenly be reversed.
The Fastly CTO was recently on the Serverless Chats podcast. I think he provides a great explanation for many of the questions you raise. He also points out that gaming would be a new application for this flavor of edge computing.
This is amazing. I think I’ve heard of almost every topic, phrase and company in this post before, but never understood how they relate together. I really enjoyed the background history because it allowed me to piece together why some technologies are so popular now.
I can see why Cloudflare, Mongo and other’s stock is soaring.
Thanks!
Holy crap, this is all for free? What kind of treasure (website) did I just discover
Ha. Yes – I am an individual investor with a deep background leading software development at Internet companies. I focus the coverage in the blog on software services that I have used and understand. I perform my own research and have found it helpful to publish my investment rationale for peer review. The primary motivation is simply to make me a better investor.
Thank you for a thoughtful, complete and informative essay. Very impressive and helpful.