Confluent stock recently bounced off its 52 week low, yet still trades under the closing price from 2022. This is in spite of posting strong results in their Q3 report in early November, which drove an 11% after-hours pop. More broadly, Confluent is part of a basket of companies that provide enterprises with software infrastructure and services to power their digital experiences. Entering 2023, we see pressure on this basket, associated with concerns around the durability of growth. This effect, along with lingering headwinds from the path of interest rates and macro volatility, has ratcheted down expectations for the software infrastructure basket.
As we consider the possibility of these macro headwinds starting to abate in 2023, growth investors have the opportunity to shift into stock picking mode. The goal is to identify companies that have the potential to outperform muted growth projections for 2023, stemming from an expectation for lower IT investment after a surge of cloud spending over the last two years. While some areas of enterprise IT investment will likely moderate, I think other functions could see a re-acceleration of demand as we exit this year.
Harnessing data to drive efficiencies in enterprise operations, supply chain management and curated customer experiences is one that I see as ripe for further investment. While every consumer-facing business has an app at this point (long couched as “digital transformation”), I am looking forward to the next wave of growth where businesses must instrument every corner of their operations and leverage the data collected to improve efficiency, lower cost and drive competitive advantage. Let’s call this data transformation. New capabilities in IoT, real-time streaming, parallel processing and data mining are converging. Advanced AI models are facilitating algorithms that can automate decision making and produce better work products. Labor shortages will reward businesses that can streamline more of their daily operations and lower cost.
Occupying a critical step in this emerging data-enabled business paradigm is Confluent. With the leading platform for data streaming, Confluent is well positioned to capitalize on the shift from uni-directional consumer and business interactions to multi-directional coordination between all participants (humans and devices) in an industry ecosystem. As the majority of data creation shifts from human activity to device activity, data volumes will explode, requiring better systems to distribute it from many producers to many consumers.
In this post, I will examine some of the emerging trends in harnessing a data-driven economy, how Confluent fits into that and the business opportunities available. I will then review how Confluent has executed against this backdrop and whether it represents the best way for investors to capitalize on this second wave of data (not digital) transformation.
Audio Version
View all Podcast Episodes and Subscribe to the Feed
Stepping Back – Demand Trends
We may very well see a dip in demand for cloud infrastructure following two years of outsized investment. This seems to be the expectation of analysts, summed up by the recent downgrade of MSFT by UBS due to concerns over Azure growth. After kicking off numerous digital transformation projects during Covid, enterprises may well be ready for a breather. Arguably every physical business now has a reasonably functional digital channel that provides a convenient touchpoint for consumers. The rush to establish these alternate channels was necessitated by Covid lockdowns and have now reached critical mass.
However, I don’t subscribe to the thesis that cloud infrastructure demand has peaked. It is true that many enterprises pulled forward cloud investment and could benefit from some optimization. At the same time, most are just getting started in transitioning their business operations to be fully software driven. I am not referring to the bevy of new SaaS apps for workforce productivity and communication, or digital twins of physical channels wrapped up in a new web experience for consumers. I am pointing to software applications behind the app facade that improve delivery of their services, customize experiences for their customers and make better use of all the data available to them.
These data-driven capabilities will differentiate companies from their competitors and the drive for that competitive advantage will continue. If enterprises pause those investments, then they will start losing share to competitors. That’s why I think any signals from CIOs about a slowdown in IT investment are temporary. Unless they can coordinate with all their competitors to do the same, they will have no choice. That is because software is a competitive differentiator.
Yes, CIOs can argue that they have enough workforce productivity software (for internal use) at this point. But, they can’t indefinitely pull back on investments that make their companies more competitive. Enterprises will continue to improve their ability to harness data to lower costs, customize services and generate operational efficiencies. Once one company in an industry ecosystem publicizes their new operational advantage stemming from automation, all the other participants will have to follow suit.
And unless all players in an industry agree to spend the same amount, they will be forced back into incremental IT investment eventually. Externally facing apps and digital experiences will continue to require attention. To build and host these experiences, enterprises will require more software infrastructure and cloud services. They should be able to optimize their cloud spending in the near term, by identifying resources that are under-utilized after a resource provisioning spree in 2020-2021. But, that low hanging fruit will soon dissipate. As usage growth continues, they will eventually require more resources.
Enterprises could make better use of on-premise data centers, in an effort to reduce their cloud bills. This would lower spend allocated to the hyperscalers, as compute, storage and network resources are provided by the enterprise itself. Yet, there are still a whole subset of software infrastructure providers that sit over or are API-adjacent to the enterprises’ data center infrastructure. These include databases (MongoDB, Elastic), monitoring (Datadog), communications (Twilio), dev tooling (Hashicorp, GitLab), security and more. A shift to on-premise hosting would have little impact here.
Enterprises could also spin up a lot of open source projects and manage these services themselves, but that generally results in more costs (people to run them) and less functionality (most open source projects have a stripped down community version at the core). Proprietary or commercialized open source solutions usually have a lower TCO than “free” open source.
As customized digital services proliferate, they will require more software infrastructure to deliver them. This will keep the demand elevated for services that power these digital experiences. Demand for those services will continue to grow linearly.
The area that I think has the potential for non-linear growth, however, is in data transformation. This encompasses new ways to instrument, collect, stream, process, mine and visualize data, and then generate new algorithms from that data to automate decision making and drive efficiencies in every step of a company’s value chain. Demand for services to extract value from raw data will likely grow exponentially. Enterprises will be forced to continue investment in this area, as their competitors do the same.

Services that facilitate the collection, transport, refinement, added intelligence and display of large magnitudes of data will continue to be in high demand. The data has to go somewhere. And while CIOs might claim they are cutting back on cloud spend, they will need to allocate resources to data transformation. Their product, operations and marketing teams will push for it. New competitor services will add pressure. As soon as the CEO sees an innovative new consumer digital service or operational efficiency that a competitor publicizes, that will become the next IT project.
Some Examples
Let me give a few examples, first on the consumer side and then on the larger B2B side. I recently purchased an electric toothbrush. I had been putting this off for years, until my dentist convinced me to make the investment in one of the higher-end ones from Oral-B. Well, it turns out that modern electric toothbrushes come with an app for iPhone and Android that connects to the toothbrush to record your brushing session.
The app provides real-time feedback on your brushing technique, with timing, coverage, pressure and brush angle. A score is assigned for each session. Additionally, each user is categorized into a type of brusher using artificial intelligence to provide coaching on getting a more effective brush. Finally, all brushing sessions are stored in a history, so that the user can track their progress and compare themselves to other users.

As you can imagine, this represents a lot of data to store. Some of that could be recorded on the user’s phone, but the majority would need to be transmitted to a central location. From there, the data would be summarized and stored for each user. Background ML jobs would review the data of all users to create the types of brushers and categorize a new user into one of them. They would then create personalized feedback for the user to incorporate into their next session. The feedback is meant to mirror the coaching that a dentist would provide.
All of that for a toothbrush. This is a digital function that didn’t exist previously, yet is now available to millions of consumers. Oral-B’s CIO can’t turn this off and their app development team likely has a list of additional features to add. It is an important feature of the product and likely contributes to the higher price point. Having an app represents a competitive advantage. Now Sonicare offers a smart toothbrush with an app as well that offers similar AI-driven features.
I realize this is a silly example, but it makes an important point. These products represent a new software enabled, AI-driven digital experience that didn’t exist previously with mechanical toothbrushes. It is data intensive, requiring a large amount of central storage and processing. Beyond the data, the app would require the standard set of dev tooling, monitoring and security to build, deliver and protect. But the data processing represents the function that can grow in a non-linear fashion as more users enable the app and the feature set becomes more sophisticated.
I think we are on the verge of seeing many more of these types of experiences. Not just toothbrush apps, but certainly around many more aspects of health tech. I do a bit of angel investing and have seen an explosion of new devices for monitoring every aspect of human and sports performance. All of these start-ups are collecting and harnessing data in new ways. They rely on large cloud-based data infrastructure installations to function.
Even professional sports teams are harnessing these capabilities in a new wave of Moneyball-like data processing. Gemini Sports Analytics delivers “Moneyball as a service”. They provide a cloud-based system that collects huge volumes of performance data, analyzes it and trains 100s of models to deliver predictions and insights to coaches. Gemini has already signed several professional teams across a couple sports categories to make use of the service. As you can imagine, as the service creates competitive advantage for one team, then they all will make use of it. Further, if we can “Moneyball” a sports team, why not an emergency room, a fire department or a retail operation? By the way, Gemini is a heavy user of Snowflake.
While these applications are focused on sports and health tech, business leaders are good at pattern matching. If an AI-enabled wearable device can monitor and optimize their blood oxygen levels for peak fitness performance, why can’t the same capability be applied to their business? More broadly, these capabilities represent the collection of data from devices to review operation and optimize performance. You can imagine all kinds of applications of this in manufacturing, transportation, logistics, health care, law enforcement, customer service, etc. At the heart of this is data.
Supply Chain Management
One could argue the prior example was just an app. Granted, the toothbrush tracker represents a new use case, but there are many other B2C functions that have been largely addressed over the past few years by apps. The digitization of common business processes started before Covid, but really accelerated in 2020-2021 as investments in “digital transformation” generated a dual benefit. Rolling out an app for consumers by most businesses provided convenience and addressed the reality that users couldn’t leave their homes.
At this point in 2023, we could observe that every bank, restaurant, retail operation, healthcare provider and airline has an app for consumers. So, what’s left? Aren’t all the physical channels transformed to digital? While there is still a long tail of businesses to upgrade their consumer experiences, the bulk of the work is likely complete.
However, I view this part of digital transformation to be simply the first wave and the tip of the iceberg. It was a necessary first step to establish a closer link between consumers and businesses. Being a digital channel, the interaction with consumers is more real-time and can be instrumented. That creates much more opportunity for the business to optimize and customize the experience for the consumer. Instead of relying on episodic connection points whenever a consumer visits a store or a physical location, the business can continually try to personalize and curate their offerings for each consumer. To do this, they will need to collect and process a large amount of data.
Similarly, creating more responsive and intelligent experiences for customers will require tighter integrations with all participants in a business’ value chain. This scope would include their partners, suppliers and even employees. Data collection, management and mining will be at the heart of these functions. As they mature, organizations will look to improve performance iteratively through machine learning and refinement of algorithms.
Decision making for many of these business functions (pricing, scheduling, coordinating, communicating) has traditionally been handled by humans. As more components of these processes are instrumented (IoT, event collection, sensors), data will be available for algorithms to handle decision making. Humans will still supervise, but won’t need to initiate every step. With more data and more effective machine learning, automated decision making will improve. The cost of labor will make these functions more critical for businesses to operate profitably.
All of these functions, in my opinion, will drive a greater investment in software infrastructure over the next decade, not less. We may see a lull in IT spending during 2023 as businesses digest the investment made in the first wave. But, I think a second wave of business innovation centered around “data transformation” will come to the forefront, exacerbated by the same competitive forces I discussed earlier. If one large company can lower cost and improve efficiency by intelligently harnessing data to optimize operations and raise customer engagement, then competitive pressures will force them all to. These are the same forces that drove every bank, grocery store, retailer and fitness studio to launch an app in the first wave.
Supply Chains
A rapidly emerging example of data transformation can be found in supply chains. As we are all aware, supply chains were severely disrupted during Covid. The challenge for all participants in these value chains, from manufacturers to distributors to retailers is knowing the status of shipments and intelligently mapping that to product demand. The goal is to avoid empty shelves, thereby maximizing availability for the end consumer. That represents a real business problem, which solved, would increase sales.
Participants are scrambling to track their components in the supply chain, creating a new “digital transformation” of the supply chain. The largest shippers are building their own engineering teams to collect and process data. They are investing heavily in IoT to instrument every physical touchpoint in the entire value chain from commodity inputs to manufacturer to distributor to wholesaler to retailer.
As supply snarls recede this year, they’re giving way to a different kind of disruption in the $10 trillion global logistics industry: a tech transformation, where everything between an assembly line and a store shelf will be tracked in real time where possible, fortified with artificial intelligence and automated. The long-term economic upside of the shift will be a disinflationary force after three years of price pressures from the supply side.
Bloomberg Article on Supply Chains, January 2023
VC’s have been dumping money into new start-ups at the rate of $9B a quarter (even in 2022) to address this problem. CB Insights estimated that there 64 tech start-ups addressing the supply chain valued at over $1B as recently as October 2022.
Some other examples of supply chain optimization initiatives referenced in a recent Bloomberg article:
- DP World Limited, a port operator that handles about 10% of global trade, has hired 500 engineers over the last 2 years to focus on end-to-end logistics solutions, tracking and visibility.
- Flexport, a U.S. digital freight-forwarding company, is doubling its engineering team by adding 400 new developers to help enterprises digitize their supply chains. That is just one private unicorn of many.
- Germany’s largest container ship carrier, Hapag-Lloyd AG, is adding sensors to its fleet of 3 million 20-foot containers to offer customers full visibility to the movement of their containers worldwide in real-time.
- Maersk Growth, the venture arm of the Danish shipping giant, helped fund a company that provides software to automate thousands of routine supplier negotiations. Walmart is a customer.
- Most logistics still run through middle men and operated manually. Pricing is communicated over emails and telephones and visibility is tracked on Excel spreadsheets. According to Cowen Inc., less than 10% of warehouses globally are fully automated.
Each of these examples would generate an immense data footprint and require significant software infrastructure resources to enable. The industry’s aspirations go beyond simple data collection and visibility, as well. Participants would like to automate more steps in the process, applying artificial intelligence to make routing decisions, optimize product placement at retailers and calculate pricing. Additionally, they want to enable real-time communications through the system. These would require secure connections to mobile networks and device-to-device messaging.
AI Developments
The other new development that has rapidly emerged in the last year has been the application of better AI to improve information retrieval, feedback loops, problem solving and decision making. This movement can be encapsulated by tools from OpenAI like ChatGPT, which provides an AI layer over a large data set and attempts to answer questions based the corpus of knowledge available on the Internet.
While the movement is early and the potential is susceptible to hype, the technology can be taken in a number of directions. We only need incremental improvements in machine to human interactions to unleash a new wave of productivity gains. And while much of the focus is on reproducing human content creation and communication, I think the bigger gains will realized in modeling and automating the more mundane business operations that companies have to deliver every day.
As an example, the start-up DoNotPay recently supercharged their chatbot with GPT-3 to handle negotiations on behalf of customers to address routine issues, like getting a refund, changing a billing plan with a provider or cancelling service. In December, their bot “talked” to Comcast’s customer service department to negotiate a $120 savings on a customer’s broadband bill.
ChatGPT leapfrogged software capabilities for bots and understands language better than almost any software before it. It can communicate in a human voice that sounds reasonably close to reality. And for mundane tasks, like these customer service issues, it doesn’t matter if the solution lacks all the rich emotions of a real human. The start-up is now planning to build an AI-driven lawyer bot that can whisper instructions to people through their earphones when they’re in traffic court.
DoNotPay is just one of a flurry of new services being hastily built on top of these next-generation AI tools like GPT-3 and DALL-E. I think these new capabilities will further drive innovation and create another surge of demand for software infrastructure. The CEO of Box recently tweeted about the rapid interest in ChatGPT from a sampling of enterprise CIOs. Perhaps some of this will fizzle out, but there appears to be tangible interest in understanding the potential and quickly applying it to enterprise operations for competitive advantage.
These AI services are even being applied to assist software developers to create applications faster. Every enterprise has a backlog of software development work. If apps and features can be built more quickly, then demand for services to host them may accelerate proportionally.
What does this mean for Confluent?
I think these trends will create a new wave of demand for software infrastructure. While we may well be nearing the peak of the cycle for SaaS applications that reproduce a physical experience (like shopping) on a digital channel (like e-commerce), I think we are beginning a new cycle of data-driven experiences that require an order of magnitude increase in data processing, storage and enrichment. These experiences will create an even larger demand for software infrastructure resources, as data creation shifts to devices (IoT), rather than humans. And devices can reproduce far more quickly.
What does this have to do with Confluent? Well, I think that this data-driven ecosystem will require a number of supporting software services. Besides the obvious capabilities to store and process the data (like databases and machine learning systems), the data will need to be collected and moved from one location to another very quickly. While in transit, it could be summarized and even queried.
This is the wheelhouse of Confluent. In this post, I’ll dig into what Confluent offers and why their services are becoming increasingly relevant. I’ll also look at how they are performing as a business and the opportunity for investment. Investors can then consider how to capitalize on the growing wave of investment around data transformation.
Sponsored by Cestrian Capital Research
Cestrian Capital Research provides extensive investor education content, including a free stocks board focused on helping people become better investors, webinars covering market direction and deep dives on individual stocks in order to teach financial and technical analysis.
The Cestrian Tech Select newsletter delivers professional investment research on the technology sector, presented in an easy-to-use, down-to-earth style. Sign-up for the basic newsletter is free, with an option to subscribe for deeper coverage.
Software Stack Investing members can subscribe to the premium version of the newsletter with a 33% discount.
Cestrian Capital Research’s services are a great complement to Software Stack Investing, as they offer investor education and financial analysis that go beyond the scope of this blog. The Tech Select newsletter covers a broad range of technology companies with a deep focus on financial and chart analysis.
Confluent Background
As Internet usage grew, new types of large-scale data generation use cases emerged that required a different type of data collection and storage architecture. While data reads can scale almost infinitely with replicated copies of data and caches, scaling data write volume is more of a challenge. Sharding databases is one way to handle more writes, but this creates management overhead. Database clusters with eventual write consistency offer another approach.
However, some types of software applications generate a large volume of state changes that can thought of as short messages containing a few data values that are either new or represent an update to a prior value. These changes in state are commonly referred to as events. These can generally be handled asynchronously, loosely meaning that they need to be captured and persisted, but that there isn’t an expectation of an immediate (synchronous) response.
Examples of applications that create a large volume of events are found in industrial use cases like sensors (IoT). AdTech provides another set of use cases, where an ad server needs to collect large volumes of user actions (clicks, views, etc.) in order to determine what ad to serve in the future. Because events are time-stamped as they flow into the data store, they are often pictured as a stream. The label of event streaming is applied to the asynchronous flow of all these data updates.
The data store that collects and persists the event stream is referred to as a stream processing platform. Apache Kafka is the most well-known implementation. The goal of Kafka is to provide a high-throughput, low latency platform for handling real-time data feeds. Data, consisting of short messages, is fed to the system from an arbitrary number of producers. Messages are written to “partitions” that are grouped into “topics”. Topics span a single data entity, like temperatures, clicks or locations. Message data can be persisted for a defined amount of time. Consumers are applications that read messages from topics and process the data to pass to a downstream system of record. There is generally more than one consumer, each with its own purpose. After the persistence period for messages in a topic has passed, that data is purged.

The stream processing platform supplanted prior systems that were purely message brokers, like RabbitMQ or Apache ActiveMQ. These simple message brokers are still in use, but don’t offer the broader functionality to handle a multi-faceted event stream. The stream processing function has also been referred to as the publish-subscribe pattern, or pubsub for short.
Apache Kafka has been implemented as a hosted service by a number of commercial entities. The primary maintainer at this point is Confluent. Confluent was founded by the team that originally built Kafka at LinkedIn. Confluent has developed an event streaming platform with Kafka at the core. Like other open core models, Confluent is building products and services around the open source Kafka project. These include a cloud-hosted version of Kafka, a library of connectors and support.
Confluent built a SQL-like query language for pulling data from a Kafka cluster in a way that is familiar to developers, called ksql. They also created a database structure that sits on top of Kafka, called ksqlDB. This dramatically simplifies the process of building an application on top of an event stream. ksqlDB essentially abstracts away querying the event stream through a consumer and allows the developer to treat the event stream like a normal relational database. This is a new and very interesting twist, as it brings data streaming and synchronous querying together.

Besides Confluent, the hyperscalers offer hosted Kafka services. AWS has Amazon Managed Streaming for Apache Kafka (MSK), which is a fully managed, highly available Kafka implementation. AWS offers a separate proprietary product called Kinesis, that is a data streaming processing engine. This is not based on Kafka, but leverages many of the same concepts around the publish-subscribe pattern. Azure and GCP offer data streaming solutions, but also have strong partnerships with Confluent for managed Kafka.

Amongst the hyperscalers, Confluent Cloud distinguishes itself by offering more add-on services and broader availability than any of the cloud providers’ solutions. For customers with a multi-cloud deployment, being able to access the same Kafka installation across different cloud providers and on-premise systems represents a big advantage. This capability would be limited in usage for any of the individual hyperscaler offerings.

Due to this inherent advantage, the hyperscalers have been increasingly partnering with Confluent. AWS signed an expanded agreement in January 2022. Azure soon followed in April 2022. As with other independent software companies, the hyperscalers are discovering the advantages of partnering with these providers versus trying to compete with them. First, it is generally more profitable, as they don’t have to build and maintain their own product line. Second, they generate revenue from the partner, as their installations consume compute and storage resources (particularly with a data-heavy product like Kafka). Finally, as on-premise customers plan their cloud migration, the software providers can bring that customer to the hyperscaler. If the hyperscaler has an antagonistic relationship, they would be less likely to win that business over another hyperscaler.
These are all benefits enjoyed by Confluent and explains why their solution for cloud-native data streaming is growing rapidly.
Product Offering
Confluent sells a cloud-native, feature complete and fully managed service that provides development teams with all the tools needed to support real-time data streaming operations. The platform has Apache Kafka at the core, supplemented by Confluent’s additional capabilities to make Kafka easier to scale, manage, secure and extend. Some of these include visualization of data flows, data governance, role-based access control, audit logs, self-service capabilities, user interfaces and visual code generation tools.
All of these are designed to simplify the effort of streaming data from multiple sources to multiple destinations. As more producers and consumers are introduced into an organization’s data infrastructure, flows cannot be managed through traditional one-to-one, batched data pipelines. A many-to-many system based on the publish-subscribe model becomes necessary.

For organizations that rely on a continuous stream of data to function, Confluent provides the underlying data infrastructure. Use cases extend beyond obvious applications like in financial markets and AdTech. As enterprises realize the benefits of optimizing their business operations and performance through data mining and machine learning, then broader and faster distribution of data in near real-time yields incremental benefits. Confluent is leveraged by leaders in multiple industries to address use cases in fraud analysis, transportation/logistics, healthcare and telecommunications.
At a high level, the investment thesis for Confluent’s growth revolves around the reality that Kafka usage is already widespread among enterprises. During their Investor Session at the annual Current conference in October 2022, leadership shared that more than 100k organizations worldwide currently use Apache Kafka. This includes over 75% of the Fortune 500.

Since Kafka usage is prolific, Confluent’s opportunity is to convert this installed base to the commercial version of Kafka that Confluent provides. To justify the upgrade, the Confluent team has built additional, proprietary functionality around the core Kafka distribution. These address tricky problems in scalability, security, management and ease of integration with data producers and consumers. These capabilities are only available to customers who subscribe to Confluent’s distribution. If the customer is self-hosted, they download and install the enhanced Confluent package onto their servers.
In addition to the enhanced capabilities in their proprietary distribution, Confluent offers self-hosted customers other services like training and support. Since managing a high-scale Kafka cluster can be quite a complex undertaking, the support function is invaluable. As Kafka usage is often associated with real-time systems, allowances for downtime are minimal. Knowing that escalated outage support is a phone call away provides enterprise IT leadership with some margin of safety in the decision to self-host. In a past role, I was responsible for a large Apache Kafka installation for an AdTech company. Having support from the Confluent team was invaluable.

Of course, with Confluent Cloud, the need to contract support separately is a moot point. Like other open core software companies (MongoDB, Elastic), the cloud offering really accelerated growth for Confluent. This is because customers can take advantage of all the extra proprietary features and offload the management of the open source package. For Kafka, I think this represents a big deal.
Managing a large Kafka cluster is no small feat. I would consider it to be more complicated than managing MongoDB or Elastic clusters (although those can be tricky as well). Knowing that the maintainers of the software are also managing the cloud service represents a huge relief. Expectations for uptime can be outsourced to the vendor, like any SaaS infrastructure.
It’s funny to say this because we’re a big engineering team, but we’re always under-resourced. For me to go hire a bunch of engineers to babysit Kafka, I don’t have the ability to go do that. And being able to offload those concerns is just such a relief for us and lets us focus on delivering value to the organization and not worrying about ops and other overhead.
Director of Engineering, Data at Instacart.
Addressable Market
To calculate the market opportunity, the Confluent team used a bottoms-up approach. They looked at their three customer segments, calculated the target population for each and then assigned an average ARR target. Admittedly, their budget estimates are on the high side, but they do have existing customers with these spending levels. This exercise yields a $60B market opportunity, of which Confluent is currently about 1% penetrated.

To reach these spending levels, Confluent employs a typical “land and expand” motion. Customers start by experimenting with a single data flow. They proceed to add more data flows that are disconnected. Often, the initial cases are non-critical or can tolerate some latency. Over time, expectations for reliability and speed increase. Eventually, Confluent is handling all real-time data flows and becomes the high availability backbone for the organization’s data operations.

Competitive Position
Confluent’s primary competition is with deployments of Apache Kafka, where the enterprise has decided to host and manage open source Kafka themselves. Confluent estimates that some form of Kafka is already deployed in over 75% of the Fortune 500 and that an additional 100,000 organizations are using Kafka. This provides a fertile hunting ground for Confluent, yet they have only penetrated a single digit percentage of potential customers.
To attract these Kafka users to the Confluent offering, the product team emphasizes three categories of advantage:
- Cloud Native. Kafka has been redesigned to run in the cloud. The Confluent Cloud solution comes with tools for DevOps, serverless configuration, unlimited storage capacity and high availability.
- Complete. Confluent has added features in a number of areas that provide supplemental capabilities not available in open source Kafka. These are designed to appeal to developers, allowing them to reliably and securely build next generation applications more quickly. These include over 120 connectors to other popular systems, stream governance, enterprise security, monitoring, ksqlDB and stream processing.
- Everywhere. Confluent Cloud is available on AWS, Azure and GCP. Confluent Platform is also available for customers that self-host their infrastructure. Cluster linking provides a bridge to connect instances across different cloud providers or to physical data centers.
For Confluent Cloud, the advantage to customers is that all aspects of managing the Kafka instance and adjacent services are handled by Confluent. With self-managed installations or Kafka cloud hosting from other providers, the IT organization is left to manage most or some of the functions in the Kafka installation.

Confluent Current Investor Session, October 2022
With Confluent Cloud, the customer outsources all aspects of managing the Kafka instance to the Confluent team. These include partitioning, scaling, software patches and monitoring. Managing a Kafka cluster at high data volumes can be very complex. Having the engineering team that wrote the software managing one’s infrastructure is a big help. Resources that were dedicated to running the Kafka installation can be redeployed onto projects that create real competitive advantage for enterprises.
Immerok Acquisition
On January 6th, Confluent announced its intent to acquire Immerok. Confluent’s CEO also published a blog post about the acquisition with more details. Immerok was founded in 2022 and consists of the leading contributors to Apache Flink. Immerok’s primary product is a cloud-native version of Apache Flink. As a fully managed, serverless offering, Immerok Cloud provides customers with an easy way to run Apache Flink without setting up their own infrastructure. This is a similar benefit to other cloud-native services based on an open source product (including Confluent Cloud for Kafka).

Apache Flink is a a large-scale data processing engine and stream framework. It was designed to focus on real-time data and stateful processing, making it an ideal solution for handling large amounts of data. Flink usually runs self-contained streams in a cluster model that can be deployed using resource managers or standalone. Flink can consume streams and then forward data to other streams and databases. Most commonly, Flink is used in combination with Apache Kafka as the storage layer. Flink is managed independently, allowing teams to get the best out of both tools.
While Flink is compatible with Apache Kafka, it overlaps with the Kafka Streams API. Kafka Streams provides a lightweight library and stream processing engine, designed to build standard Java applications. It is often used for microservices, reactive stateful applications and event-driven systems. It is a native component of Apache Kafka.
In some cases, developers will choose to deploy Apache Flink instead of Kafka Streams. Because Flink is managed separate from the Apache Kafka cluster, it has more flexibility in the types and volume of data sources that it can process. It supports both bounded and unbounded streams, and is better suited for analytics workloads. Kafka Streams are largely tied to Kafka topics as the data source, but can be simpler to deploy and maintain, as it leverages the existing Kafka cluster for its infrastructure.
With Immerok, Confluent adds significant stream processing expertise to the organization. Confluent plans to accelerate the launch of a fully managed Flink offering. This would be compatible with its fully managed Kafka service, Confluent Cloud. The benefit to customers is that they could choose from several stream processing tools natively on Confluent Cloud, including Flink, Kafka Streams and ksqlDB, based on their use case.
Confluent’s plans are to build Flink into the Confluent Cloud offering in a truly native way (not just hosting Flink on the cloud). This will include a full integration, available in the same cloud locations as Confluent Cloud. They are targeting the first version to be launched in Confluent Cloud later in 2023.
The benefit to customers will be having direct access to Flink within the Confluent product offering. Many of them were already using Flink in conjunction with Kafka, but had to manage the Flink installation separately. Flink provides them with more capabilities for data streaming than basic Kafka Streams. As Flink is gaining in popularity, this integration should allow Confluent to capture interest among their enterprise customers. Support for Flink will likely be incorporated into Confluent Cloud standard pricing, versus being pulled out as a separate offering.
Business Performance
Confluent (CFLT) reported Q3 results on November 2nd. The market initially reacted favorably to the results, yielding an 11% pop after hours but fading the next day and closing up about 1%. The stock was weighed down by a broader market sell-off in early November. Since then, CFLT stock has generally trended downwards, in line with the performance of the software infrastructure category in general. On January 6th, it touched a 52 week low below $17. In late 2021, the stock peaked over $90.

Confluent went public in June 2021 at a price of $45. Like many software infrastructure stocks at the time, it enjoyed a high valuation with a trailing P/S Ratio over 40. As with price, CFLT stock’s trailing P/S Ratio is currently near its lowest point historically around 10. For a company that is delivering revenue growth in the high 40% range, this valuation multiple is on the lower end. However, Confluent is still far from break-even on operating or FCF margins.
As with many software infrastructure companies, suppressed valuation is being driven by macro pressure (interest rates, inflation) and concerns over revenue growth in 2023. The key question will be how Confluent performs this year. Analysts currently have 2022 revenue estimated to be $580M, at the top end of Confluent’s guidance, for 49.5% growth over 2021. For 2023, the preliminary estimate is for 32.2% growth, which was based on Confluent management’s initial guidance for $760M – $770M in revenue issued with the Q3 report. We will get an update on this range with the Q4 results on January 30th.
As part of that initial range for 2023, leadership anticipated a hit of $12M to $17M from increased deal scrutiny and macro impact. This represents about 3-4% of annualized growth in 2023, which would have brought the growth rate up to the mid-30% range. Confluent has a history of outperforming guidance. So, it’s likely that actual revenue growth for 2023 lands somewhere in the mid to high 30% range. This is highly dependent on the macro environment and customers’ appetite for investment over the next 6 months.
As with all software infrastructure and SaaS companies, expected valuation comes back to the durability of revenue growth. That will hinge on the size of Confluent’s target market and whether they can capture increasing share. Competitive moat, customer expansion opportunities and adjacent product categories will drive the potential here. As I discussed, these look favorable at this point, combined with secular tailwinds in data transformation revolving around the growth of big data to drive new AI-enabled consumer experiences and the instrumentation of the value chain (IoT, automation).
With that set up, let’s take a look at Confluent’s performance in their most recent quarter.
Q3 2022 Results
In their Q3 earnings report, Confluent beat expectations across the board. Revenue was $152M, up 48% y/y and 9.4% sequentially. In Q2, revenue was $139M, up 58% y/y and 10.5% sequentially, so we are seeing some deceleration. Sequential revenue growth is holding up pretty well, but more in line with a 40% annualized growth rate. The Q3 results beat the analyst estimate for $144.8M substantially, which represented 41% growth.

Confluent Cloud revenue grew more quickly, coming in at $57M, which was up 112% year/year. In Q2, Cloud revenue was $47M for 139% growth. Confluent added $10M of Cloud revenue in Q3, up 21.3% sequentially. This was a record amount of total dollar addition. Cloud now makes up 37.5% of total revenue, up from 26.2% a year ago. Like other open source companies with a cloud offering (ESTC, MDB), the higher growth rate of the cloud product will pull up total revenue growth as it becomes a larger contributor. Cloud is already generating the majoring of new ACV bookings at more than 60% for Confluent.

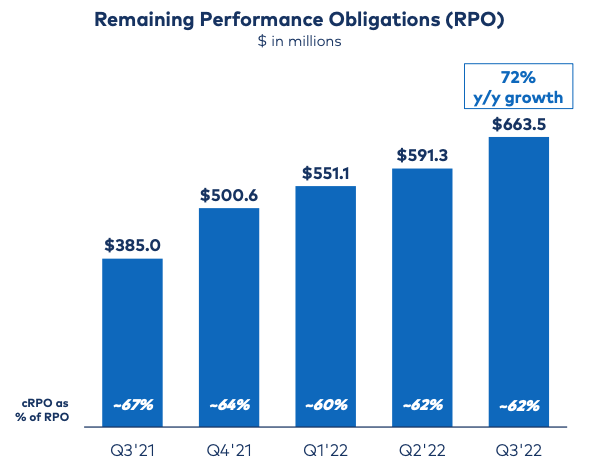
RPO showed a nice increase as well with total RPO of $664M, up 72% y/y. This compares to RPO of $591M, up 81% y/y in Q2. Current RPO was 62% of the total in Q3, or $408M. This grew by 59% y/y.
Geographically, revenue from the US grew 44% to $95.1M. Revenue from outside the US grew 56% to $56.6M. On Confluent’s Q2 earnings call, they called out some deals that were taking longer to close, due to additional scrutiny across geographies. While that dynamic continued in Q3, leadership reported that the vast majority of those deals were closed as expected in the quarter.
For Q4, management estimates revenue will be in a range of $161M – $163M. This represents annual growth of 35.1% and 6.6% sequentially. This beat the analyst estimate for $160.2M. While the annual growth rate is taking a large step down, the sequential raise is pretty good considering the magnitude of Confluent’s beat in Q3. If they repeat that sized outperformance, then annual growth would be in the low 40% range and sequential growth would be almost 12%. I don’t expect a repeat of Q3’s beat, but even sequential revenue around 10% would be favorable for forward annual revenue growth rates.
Annual growth is expected to finish 2022 at a range of $578M – $580M. This represents an increase of about $10M from the Q2 estimate for $567M – $571M. Confluent beat their Q2 estimate for Q3 revenue by about $8M, allowing a bit of upside to the Q4 guide.
On the profitability side, Confluent is making progress, but is still far from break-even. They are following a similar path to other software infrastructure companies, starting with operating margins deeply negative and then incrementally improving them year/year. They are currently targeting to reach positive operating margin in Q4 2024. This approach was viewed by the market more favorably in 2020-2021. In 2022, high growth companies with negative margins have been re-rated below their profitable peers. This posture is likely to continue.
In Q3, Confluent reported total Non-GAAP gross margin of 71.0%. This is up 160 bps from 69.4% a year ago and 400 bps from 70.6% in Q2. Narrowing to just the subscription products (Cloud and Platform), gross margins are higher. For Q3, subscription Non-GAAP gross margin was 76.9%, which was slightly greater than 76.8% a year ago. Improvements to gross margin stem from efficiencies in cloud hosting due to scale and optimization. These are offset by the greater mix of the Cloud product, which inherently has lower gross margin than the packaged software offering in Platform.
Confluent continued to demonstrate improving operating leverage in Q3. Non-GAAP operating margin increased by 13.8% y/y to reach -27.8% in Q3, up from -41.6%. This was driven by reductions in the relative percentage of revenue for R&D (2.4% improvement y/y), S&M (8.2% improvement) and G&A (1.6% improvement). This drove a Non-GAAP EPS for Q3 of ($0.13), which beat the analyst estimate for ($0.17) by $0.04.

Cash flow improvements were offset by a $13.5M payment in Q3 for the annual bonus program. This charge had been moved out of Q1 2023 and was discussed by management last quarter. Free cash flow in Q3 was ($45.6M) for a FCF margin of -30%. This compares to ($20.6M) a year ago and -20% FCF margin. The bonus payout in Q3 of 2022 impacted the FCF margin by 9%, meaning that FCF margin roughly remained even y/y. Confluent ended Q3 with $1.94B in cash, cash equivalents and marketable securities.
Looking forward to Q4, management expects Non-GAAP operating margin to be approximately -28% and non-GAAP net loss per share to be in the
range of ($0.16) to ($0.14). This compares with the analyst estimate for ($0.18). For the full year, management raised the Non-GAAP operating margin target to be approximately -32%, up from -34% to -35% set with the Q2 results. They also raised the Non-GAAP net loss per share to a range of ($0.65) to ($0.63), up from ($0.73) to ($0.69).
As part of their preliminary guidance for next year, Confluent management set an operating margin target of -21%. This would represent an 11% improvement over the updated target for FY2022. They will likely beat this by a few percent, bringing Non-GAAP operating margin closer to the negative mid-teens.
Confluent reported mixed customer activity for the quarter, considering mounting macro pressure. They added 120 new customers, bringing the total count to 4,240. This represented annual growth of 40%, but only 2.9% sequentially. I call out the sequential growth rate, as that follows 0% growth sequentially in Q2, implying that the annualized total customer growth rate will quickly drop below 10% at this cadence.

Growth in large customers appears to continue to be on track. Confluent added 64 customers with greater than $100k ARR in the quarter, up 7.5% sequentially and 39% y/y. This is practically linear to Q2’s growth, where 66 customers crossed this threshold, up 8.3% sequentially. Confluent also reports on $1M+ ARR customers regularly. This segment grew by 6 in Q3, up 5.6% sequentially and 53% y/y. They had added 9-10 of this size customers in the last two quarters, so a slight slowdown.
Confluent has a higher concentration of large customers as a percentage of total customers than most other software infrastructure companies. Their $100k+ customers make up 22% of the total customer count. This compares to 12% for Datadog, 4% for MongoDB and 1.2% for Cloudflare.
The revenue contribution of the $100k customers is 85% of total revenue. This is more inline with other software infrastructure companies, where large customers also contribute the majority of the revenue total. Even Confluent’s concentration of million dollar customers is high at 2.7% of the total. They also report a growing number of customers with $5M+ and $10M+ in ARR.
Robust growth in large customers is driving a high dollar-based net retention rate, which remained above 130% for the 6th consecutive quarter. This was bolstered by 90%+ gross retention and even higher NRR for Cloud customers, which is the fastest growing segment. This circumstance of a higher net expansion rate for Cloud product customers mirrors the experience of other open core providers, like Elastic.

I would be less worried about the movement in total customer counts sequentially if Confluent already had an oversized pool of customers. Other software infrastructure companies have seen their movement in total customers slow down recently, but they have a much larger base in multiples of 10k or even over 100k (DDOG, MDB, NET).
To make this process even easier for developers, I’m very pleased that towards the end of our first quarter, we removed the requirement of entering credit card information for the free trial of our product. This paywall removal is a strategic move that aligns well with our customer growth go-to-market model, allowing us to reduce the friction for developers to test our product, grow usage and progress to the production stage. And we are already seeing strong returns at the top of our funnel as evidenced by the accelerating growth in Q2 signups, which are up more than 130% year-over-year and up more than 50% sequentially.
This paywall removal has been incredibly successful in increasing signups, but it has also created some short term noise in our total customer count metric. Users who would have incurred small amounts of spend and been previously counted as customers in their initial trial phase will now show up as just signups not paying customers, which impacts our customer count growth in Q2. This means that the change has eliminated a large chunk of pre-production customers, paying us an average of less than a few hundred dollars per quarter, creating a reset of our pay as you go customer count.
Reset of customer count aside, it’s unquestionably the right strategy for our business as our customers can now test drive Confluent risk free. And for us, the reduction in developer risk and friction drives easier land and ultimately more paying customers as the larger cohort of trials leads to sticky production applications that grow and expand at scale.
Confluent CEO, Q2 2022 Earnings call
Total customer growth will be an item to watch going forward, as the low number of sequential additions could eventually dry up the future expansion motion. Confluent did make adjustments to the customer sign-up process for the free trial of their products in Q1. The explanation for the impact was covered in the Q2 earnings call.
Assuming total customers get back on track, the big opportunity for Confluent at its current size with an annual revenue run rate around $600M, is to grow more large customers into the $5M and $10M range. For a company at this revenue run rate to have any $10M customers is impressive, as long as the spend elasticity extends across their customer base. Confluent doesn’t require a whole lot of $5M and $10M customers to get revenue over $1B.
They have shown evidence of a very elastic spending threshold. At their Current conference in October, leadership presented a number of examples of companies that have significantly increased their Confluent spend over time.

If we look at one example with the Fortune 50 Bank, Confluent leadership laid out the expansion progression over 4 years. They even think the customer has a line of sight to $20M in ARR.

To have a single customer approaching $20M in annual spend is significant. That one customer would represent over 3% of total revenue for 2022. Assuming that other Fortune 100 customers can reach this threshold, then Confluent’s focus on growing their largest customers makes sense. Snowflake applies a similar tact, with some of their customers recently passing the $100M threshold in annual spend. Given that Confluent’s budget likely falls in the same bucket as Snowflake, I could see how Confluent can justify large spending thresholds, even if just 10% of the Snowflake budget threshold.
Investor Take-aways
While I am bullish on the broader implications of “data transformation” trends to increase demand for software infrastructure over the next 3-5 years, I have a mixed take on Confluent as an investment opportunity in the near term. Here are some pros and cons.
On the favorable side:
- Relatively small revenue run rate ($600M), yet demonstrated ability to capture very large spend with select customers ($10M-$20M at top end). Moving just a subset of Fortune 500 customers into the top range quickly gets them to $1B in revenue. NRR is over 130%.
- Apache Kafka has broad adoption with Fortune 500 enterprises, so the “sell” is to convince them to flip over to a commercial version versus introducing a brand new technology.
- Confluent is the leading solution that addresses the Kafka ecosystem – its co-founders started the project. Alternative solutions haven’t reached market scale yet.
- Relationships with the hyperscalers are warming, switching from a headwind into a tailwind over the last year. Revenue from hyperscaler marketplaces is growing rapidly.
On the risk side:
- I have concerns about the true size of the market. While Confluent’s projections paint an optimistic picture, I would like to see more evidence that many companies will allocate the large spend anticipated. It’s possible that only a small percentage of businesses really benefit from “real time” data streaming, versus leveraging other ways to distribute data through frequent updates. While many companies use Apache Kafka in some capacity, it may not be central to their data processing pipelines.
- A slowdown in total customer additions has been obfuscated by the change to the sign-up process. If Confluent’s new customer pipeline is shrinking, it will eventually impact the expansion motion.
- While data streaming could become a large market, I don’t see other product categories emerging that Confluent could address. So far, they sell into one category, making their offering somewhat niche. If other companies offer alternative means of distributing data in real-time, along with adjacent data processing and storage capabilities, then the platform consolidation argument could squeeze out Confluent. For example, Databricks offers a data streaming capability. It currently integrates with Confluent as a source, but could be used as a stand-alone pipeline for simpler data distribution configurations.
- The need for a high scale, real time data distribution system would be mitigated if the concepts around a universal Data Cloud take hold. In this situation, the connections between transactional and analytics data stores are direct, potentially within the same company. While nascent, Snowflake has made moves in this direction with their new Unistore transactional database.
Looking at valuation, CFLT currently has a market cap of $5.8B and EV of $5.0B. Its P/S ratio comes in about 11 with $537M of trailing revenue. If Confluent beats their preliminary estimate by 4% of growth, then 2023 revenue will land around $790M. With a market cap of $5.8B, the forward 2023 P/S ratio would be 7.3. Enterprise value is $5.0B, making the EV/S ratio a slightly more favorable 6.3. With revenue growth of 36%, this ratio would be on the lower end as compared to peers. Profitability dampens this view, though, as the preliminary operating margin estimate for next year was set at -21%. This compares to the current estimate for 2022 of -32% operating margin, representing an 11% improvement.
Projecting where these estimates, if hit, would put CFLT stock exiting next year is difficult. Peers in software infrastructure and SaaS that are growing in the mid-30% range and unprofitable (OKTA, SMAR) have a P/S multiple around 6-7 currently. That implies that CFLT is fairly valued now. Upside would be possible if Confluent outperformed their targets for 2023, or exited the year with some growth re-acceleration in Q3-Q4. Additionally, if market sentiment towards growth stocks improves and interest rates stabilize, that would provide some valuation tailwinds as all software infrastructure stocks might re-rate upwards.
The other opportunity for a Confluent investment is dependent on how 2024 looks. Analysts have modeled $1.01B in revenue for 2024, which would represent 31.7% growth over 2023. This would bring the valuation multiple into the 4-5 range, which would be low for 32%+ growth. The big question, then, revolves around the durability of Confluent’s revenue growth over the next few years and whether they could return to the 40% range if/when macro pressures subside.
At that point in 2024, we could see a re-rating, combined with the accumulated revenue, bringing the enterprise value up to the $9-10B range, or almost 2x increase over the current value of $5.0B. We could also assume that Confluent reaches break-even operating margin at this point, which they indicated was their intent by Q4 2024. That represents a lot of “ifs”, but an optimistic view could get to that valuation and result in stock appreciation back to about $40 a share.
Given this, the pros/cons and the more than 10% appreciation in CFLT since I started this post, I will likely continue to monitor CFLT stock before opening a position. If the price drops back below $18 or revenue growth appears like it will be higher over the next 2 years and durable, I will start to build a position in CFLT. Given the tailwinds from data transformation, Confluent is definitely well situated and merits closely monitoring.
NOTE: This article does not represent investment advice and is solely the author’s opinion for managing his own investment portfolio. Readers are expected to perform their own due diligence before making investment decisions. Please see the Disclaimer for more detail.
Additional Reading:
- As I was writing this post, Muji over at Hhhypergrowth published an update on Confluent in his Premium service. It is worth a read and goes into more detail on recent product developments. A paid subscription is worth the money.
- Sessions from Confluent Current are available for viewing. I recommend watching the Keynotes at least if you are considering an investment.


Thanks for the article. Just from a google search, Snowflake says:
“Snowflake can provide near real-time data ingestion, data integration, and querying at industrial scale. For example, the Snowflake Kafka Connector reads data …”
“Data consumers securely access live and governed shared data sets directly from their Snowflake account, and receive automatic updates in real time.”
Because of “real time” and “near real time” in that, I’m not seeing a strong case for anyone to use Confluent rather than Snowflake, unless they’re already using Kafka and want Confluent to “baby-sit” it. Am I just confused and need to read the piece again?
You are generally correct. If an enterprise is already using Kafka, then they could utilize Snowflake’s real-time data connectors. Confluent does provide easier management of Kafka, though, saving the enterprise engineering resources to “baby sit” as you put it. The enterprise may have other destinations for their data than Snowflake as well, increasing the value of the other Confluent connectors.
Thanks!
Hi, Thank you for your detailed articles.
Just wondering. What is your opinion of the Kappa and Lambda architecture, is Kappa sounding too good to be true (practicality, economically, technically), and would it ever affect SNOW and CFLT’s long term look.
Thanks. I don’t have a strong opinion on either architecture. They both have pros and cons. With that said, both architectures make use of a data warehouse and a stream ingestion service, so SNOW and CFLT could benefit from adoption