
Conventional paradigms for data management are being disrupted. Collecting data in silos for single purpose analysis captures only a portion of its value. Increasingly, large data sets will be combined across companies and industry ecosystems to generate a higher dimension of insight. These data sets will span enterprises, their suppliers, partners and customers. New businesses will emerge to provide third-party data sets to supplement and enhance data aggregations by industry. These will power the next generation of AI-driven data applications and services.
At the core of multi-party data sets will be a system for controlled, performant data sharing. Such a system must have governance and access control at its core, and utilize materialized views to prevent copying of data. It must be easy to configure and manage, without requiring extensive coding or provisioning new infrastructure. It should also incentivize independent data set creators with a means to market, distribute and monetize their data.
Snowflake is building such a system with their Data Cloud, enhanced by Data Sharing and the recently launched Data Marketplace. While the features and capabilities of their core data management platform are important to consider relative to other providers, the curation and management of industry specific data sharing ecosystems could represent an end-run around competitors. As the number of participants in data sharing and distribution webs increases, network effects will kick in that create stickiness for their core Cloud Data Platform. Participation in the sharing ecosystem could become the primary driver of platform usage over time.
In this post, I will dive into these trends and how Snowflake is well-positioned to capitalize on them. I won’t spend much time detailing Snowflake’s core data platform and how it relates to competitive offerings. Other analysts, particularly Muji at Hhhypergrowth, have covered that extensively (see additional reading at the end). I will focus on the next big wave of growth for Snowflake, centering on their data sharing capabilities and the rapidly developing ecosystem of participants by industry. This opportunity encompasses an enormous addressable market and will drive future expansion of SNOW’s already large market cap.
Background
The data warehouse evolved as a concept to represent the collection of all of a company’s data in one large data store. This existed behind the individual applications and transactional databases that powered the business. It provided one place that data analysts could go to run large queries across the company’s full data set, in order to generate interesting insights about how to improve the business.
This data warehouse was often relational, with well-defined structures for data organization optimized for common query patterns. To accommodate newer types of unstructured data and data in its raw form, this concept was extended to encompass other data stores like the data lake. The data lake provides access to a larger set of raw, unprocessed data. This is often of interest to data scientists, as it precedes the deliberate filtering applied by data analysts to refine data sets into a form suitable for their analysis.
However, even if we expand the data warehouse to include its source data lake (some call this a lakehouse), the concept of a fixed boundary around an enterprise’s data remains. The notion of a “warehouse” with walls protecting the contents from outsiders provides an apt metaphor. Data analysts can examine the contents of their company’s warehouse with relative ease, as data is already organized neatly into rows, columns and tables. To extend the metaphor, perhaps the warehouse has a lake behind it, where all the raw data is stored. Data scientists can run their own harvesting algorithms and machine learning against that to extract deeper insights. Regardless of the form, the whole “data installation” is still protected by a big fence. Only participants inside the fence, whether a single company or even a department, can mine it.
In the case where data is to be shared with other parties, whether partners, customers or permissioned consumers, that data is exposed through narrow points of exchange. Much like the process of loading warehouse contents onto trucks and moving them through controlled gates, data can be exchanged with outside parties in batches, through rigidly defined methods.
These data exchange gateways often take the form of APIs, delivered over HTTP based on RESTful patterns. APIs allow the business to define fixed protocols for outside parties to request data and be provided with a response. In this case, the consumer of the data has to code their request and response to the API format dictated by the provider. In many cases, the API design is unique to each provider, requiring consumers to duplicate their interface code many times with adjustments for each provider’s API definition.
Additionally, API payloads are generally requested and processed in batches. If a consumer wants to perform their own analysis of a producer’s data set, they would generally make multiple requests to create a copy of the full set of data and load it into their own data management engine. Only then could they run analysis of it or combine it with their own data to form a superset for more interesting queries.
In many cases, an API is the ideal. Some companies exchange data through more rudimentary methods, like flat file generation and shipping over FTP or email. These require more processing overhead and are less granular. Generally, the data consumer completely wipes and refreshes their copy of the source data on a batched basis, quickly resulting in stale data. Worse, copies of the source data are floating around in consumer installations, with no ability to revoke access if the producer/consumer relationship ends.
These approaches create a lot of overhead and limit the amount of data that can be shared. They don’t handle updates well and rely on making multiple copies of the source data. While the API can provide some level of governance and granular access, it still requires developers on both ends to load and consume the payload.
These methods of data exchange limit scale and flexibility. Yet, the real promise of AI and ML is realized with increasingly larger data sets. Data shared across enterprises in the same industry or across industries for pattern analysis will yield better insights. ML training requires large amounts of data to generate and validate their models with accurate outcomes. Different types of data sets will round out the analysis from multiple perspectives. This stacking of data sets will allow for insights to be generated at the intersection of different producers.
An example might be the creation of highly personalized auto insurance premiums. These could be generated by combining weather data, driver history, insurance claims and vehicle manufacturer specs. In this case, the data might be sourced from four different entities – the government’s weather history, a driving app, insurance companies and car manufacturers. These four entities might have large data sets in their own silos, but no easy way to share data between them.
If a modern auto insurance provider wanted to conduct this kind of advanced data processing in near real-time, they would need to aggregate the data from the four entities mentioned. To get access to the relevant data from each party, they might be able to access each provider’s API’s or more likely get some sort of flat file or data dump. The aggregator would then combine all the data into one large data store (their own data warehouse) and then run the desired analysis. If any of the source data changed, they would need to repeat the request/combine process again, generally from scratch.
A more ideal way to perform this exercise would be if all the data sets could be accessed from a single cloud data platform. Each entity might still have their data in what appears to be their own physical data warehouse, but all those data warehouses would be connected by a common virtual data management backplane. That would allow for controlled sharing without all the overhead of provisioning API’s or creating data files.
In this case, the data management platform becomes an enormous “warehouse for data warehouses”. Each individual data warehouse still maintains strict federation and access controls. But, if two or more entities want to share data, it would be easy to create a materialized view representing the desired combination of data sets. Similar to the materialized view on a database, the view wouldn’t create a new copy, would have access controls and could be revoked at any time. That would make sharing much easier and scalable, enabling far-reaching data analysis queries and hence richer insights.
This is the promise of data marketplaces, as a superset of the data warehousing underneath. If a single data management provider could gain critical mass of data producers on their platform, then the benefits would be enormous. A warehouse of data warehouses would enable the next generation of AI and ML processing by providing the superset of raw data to analyze.
Ideally, the provider of the system to manage this data sharing would support several design tenets to really make it scale. Data sharing should be set up and manageable by non-technical users, without writing code or provisioning specialized infrastructure. Access controls should support granular data definitions, be account based and revokable on demand. The superset of data should be created without making copies. That materialized view should not be limited by size and should support the same analysis and machine learning workloads as the original. While the provider can prefer to have a commercial relationship with all participants, they should enable basic access to share data sets available for non-customers.
If a provider could create a system of data sharing that meets these requirements, then strong network effects would come into play. The warehouse for warehouses provider with the most participants would realize tremendous value. This is because new participants would almost be compelled to utilize that warehousing solution in order gain access to their industry’s data sharing ecosystem. Participants outside of the leading provider’s ecosystem could certainly fall back to sharing data through APIs or other manual processes. Over time, however, that would create a disadvantage for them as potential partners weigh the cost of creating a one-off data exchange mechanic versus just activating data sharing permissions on a common data management platform.
Solutions for Data Sharing
Artificial intelligence and machine learning will create tremendous opportunity over the next decade. Some analysts are calling it the next information revolution and conceive that new trillion dollar market cap companies will emerge from this. Harnessing this trend presents significant opportunities for forward-thinking investors. Along those lines, we see clear beneficiaries that address the hardware and software components of AI/ML workloads, most notably on the processor side. Nvidia (NVDA) comes to mind here.
However, I haven’t seen as much focus on addressing the challenge of creating the enormous data sets necessary to capitalize on this exciting technology. There are many solutions that allow a single entity (company, government agency, university, non-profit) to collect all their data into a data warehouse/lake/lakehouse and run AI/ML workloads on top of it. Additionally, as I discussed, there are existing technology solutions to facilitate data sharing over narrowly defined channels, like APIs, ETL jobs or data streams. In these cases, assembly of a superset of data across multiple entities still requires the construction and maintenance of a separate copy of the larger data set, presumably housed on its own even bigger data management engine.
Scalable, secure data sharing will be necessary to facilitate the assembly of these enormous supersets, particularly where unique insights will emerge from the inputs of multiple parties within an industry. In the simple example I used earlier, auto insurance premiums would be enhanced by real-time inputs across multiple data sources (weather, vehicle manufacturers, driver behavior, claims data). A similar case could be made for optimizing much more complex systems, like transportation networks, city planning, health care, product design, supply chains, etc.
Yet, it is still fairly challenging to seamlessly share data between vendors, customers, partners and third-party producers. The default approach is to distribute flat files, leverage API endpoints or spin up data pipelines that route data streams from one system to the next. Yet, these approaches still require technical support. At worst, developers are dedicated to create one-off data export and ingestion scripts or write new code to consume yet another API format. At its best, SysAdmins have to configure specialized infrastructure or open network connections to facilitate data exchange pipelines.
It would be much easier if data sharing could be enabled through a UI interface on the existing data management solution by an operator without writing code or configuring specialized infrastructure. The operator should be able to define the set of data to be shared at a very granular level and establish access permissions per user account. These could be activated and revoked on demand.
Most importantly, the data sharing should be facilitated through materialized views, without actually exporting a copy of the data to the consumer. This prevents the inevitable request for the consumer to “destroy all copies” of data after the partnership ends. It also ensures that the data view is always up-to-date, without requiring a full purge and refresh. These views, regardless of size, could then be used for sophisticated data analysis, machine learning training and visualization. The shared views would function similarly to the original data set on the data management platform, obviating the need to create a separate aggregated data set for analysis.
A solution that is well-suited to address these requirements is the Snowflake Data Cloud, specifically their Data Sharing capability and the new Data Marketplace built on top of that. A lot of focus on Snowflake’s potential up to now has been on their single entity data storage solution, which they refer to as the Cloud Data Platform. The distinction is subtle in naming, but important in scope. The Cloud Data Platform represents Snowflake’s core offering of a data warehouse like technology, with a number of extensions around it that increase the usability, flexibility and applicability to additional use cases. Included in this was their move beyond the data warehouse category into a full-fledged big data management toolset, as their Cloud Data Platform supports a Data Lake and unstructured data formats.
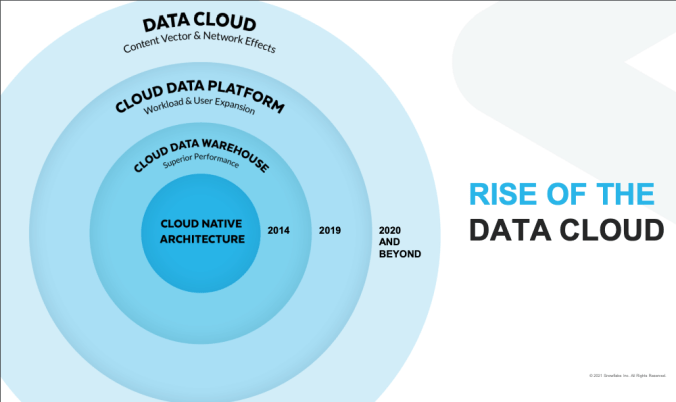
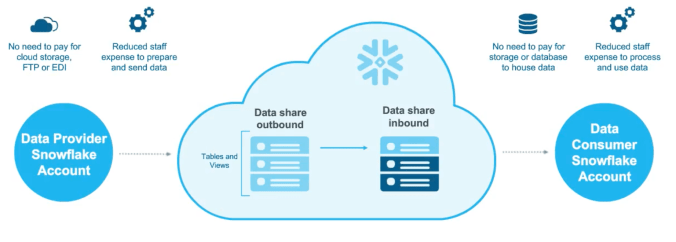
Snowflake’s Data Cloud takes the single entity model a step further and considers the opportunity to connect Cloud Data Platforms between entities. This is the crux of Data Sharing, allowing controlled sharing of data between customers, partners, vendors and third-party providers. To enable this, the Data Cloud layers on several incremental capabilities:
- Ability to define any subset of data for sharing. The data set can be filtered down into a single view, with filtering by desired parameters. For example, a retailer could share product sales data with vendors, but filter it by product supplier.
- The data view is materialized and kept up to date. This means it is not a copy and doesn’t require the creation of a separate data store for the consumer in order to examine it.
- Strict governance controls. Users can create flexible data governance and access security policies and apply them across different data workloads. They can grant access on a granular level to individual consumer user accounts and revoke access instantly.
- Any materialized view can then be used just like a data set on the core cloud data platform, meaning users can run data analysis, machine learning, data applications and more on top of it. Because the view is continuously kept updated with source data changes, the consuming application doesn’t have to request a new copy.
The implications of these capabilities are huge. It completely side-steps the current models for data sharing, which often require manual batch jobs, processing large flat files of data dumps (like csv files), one-off API integrations and even newer data streams. By using a temporal view of the shared data, the provider doesn’t need to worry about the consumer keeping a copy after the relationship is over. Once a data sharing model is set up, it can be easily duplicated across many consumers. This is a big advantage, as the FTP/API model often requires a different type of export for each consumer.

The big benefit for Snowflake customers is simplicity and cost savings. First, Snowflake provides the Data Sharing capabilities for free. This encourages more participants to join the Data Cloud and consider data sharing use cases. Once each participant in data sharing is on the Data Cloud, they don’t need to provision additional space to house the shared data set. This is a big benefit over prior solutions, where all the aggregated data was generally copied into a new data management instance for analysis. To help with onboarding, the data consumers aren’t required to have a Snowflake account to participate. The data provider with a Snowflake account can provision views for the consumers and create access credentials. In this approach, the provider can pay for the additional consumer usage.
Current data sharing solutions like file export/ingest and APIs require both the producer and consumer to agree on the format for data exchange. This is a huge hidden cost of one-off data sharing models. I have participated in these types of discussions at past companies. The BD team will typically land some new partnership with an adjacent company to share data. Then, they hand off the relationship to the engineering team to figure out how to make it work. This usually involves a series of meetings to agree on the format for data exchange, followed by several cycles of development to get file exports or APIs set up. Granted, some re-use is possible with API standards, but there is invariably a few custom fields or unique changes that each partner requests.
Even newer “open” models for data exchange through controlled pipelines still introduce some overhead. These methods rely on spinning up a server to proxy requests for the data set on behalf of consumers or implement a data streaming technology. Consumers are still required to implement client connectors and data ingestion scripts in a prescribed format. While these approaches are contrasted against Snowflake’s “closed, proprietary” system, they still create friction and require support from the technology team. Business users and data analysts would generally prefer a system in which they can be self-sufficient, albeit with expected governance and security controls.
With Snowflake’s Data Sharing capability, all these machinations at the developer level are avoided. A non-technical business analyst with admin permissions can set up the data sharing for each partner. They might simply re-use an existing sharing model, just granting access to a new user account. Or, they construct a new materialized view for that partner through a visual, drag-and-drop type interface. No code required.
Because data sharing is free, it creates a lot of stickiness for the Snowflake Data Cloud. Snowflake generates revenue from the core storage and compute that participants consume in order to get set up and participate in the ecosystem. Once sharing starts, it just cements their participation, making it more costly to consider an alternate solution for the core data warehousing solution (Snowflake’s Cloud Data Platform).
We can see how Snowflake is positioning themselves as the “warehouse for data warehouses”. The dotted line around multiple customer Data Cloud Platform instances in the prior diagram underscores this approach. Powering each Data Cloud Platform in isolation would make for a significant business opportunity for Snowflake. However, the network effects of enabling the connection of multiple customer instances increases the market value by an order of magnitude.
If we view the core data warehouse/lake/lakehouse technology set as eventually becoming commoditized, then Snowflake’s strategy makes a lot of sense. Like any network, the value is created by the number of participants. Snowflake is up-leveling to facilitate participation in the ecosystem rather than competing just on the feature set for each individual instance. As more participants join the ecosystem, its value increases. Played forward, this could result in Snowflake usurping the majority of big data processing, driven by the demand for richer insights through AI and ML models.

This point is important to consider, as it relates to market size and Snowflake’s future growth opportunity. Snowflake estimated the TAM for the core data warehouse to be $14B a few years ago. With their expansion of use cases, data types and reach, the addressable market for the Cloud Data Platform grew to $90B as of April 2021. For the Data Cloud, Snowflake hasn’t provided an estimate, but represents the size of the circle in their investor deck as being 10x the Cloud Data Platform. For this calendar year, they are tracking to pass $1B in revenue, leaving a lot of room for future growth.
Data Marketplace
The Data Cloud puts Snowflake in a favorable position to create new data sharing ecosystems by enabling the assembly of data supersets between companies and secure exchange of data as inputs to industry-wide workflows. The Data Marketplace takes this to the next level, by allowing independent data providers to market enriched data sets to ecosystem participants. The Data Marketplace was first introduced in April 2020 and was brought to full general availability in June 2021.
The Data Marketplace has experienced rapid growth this year. In January 2021, Snowflake announced passing 350 datasets from over 120 data providers. By July 2021 (6 months later), this had increased to 656 datasets from more than 175 data providers. Participants generated 4.4M data sharing queries per day on average in the month of July 2021. Data providers include examples like Heap Analytics, Knoema, FactSet, Safegraph, WeatherSource, Experian, ZoomInfo and Foursquare. This is on top of a major integration with Salesforce announced in June 2020 that allows Salesforce customers to easily share data between their Salesforce Cloud instances and Snowflake.
Examples of partners and customers using Data Sharing and the Data Marketplace help underscore the benefits of accessing data in this way. Pacific Life Insurance removed the overhead of file transfers and one-off ETL jobs to access data from Experian. Popular business contact provider Zoominfo is able to more easily distribute its data to customers through the Snowflake Data Marketplace without requiring separate data ingestion jobs for automation. Albertsons Companies are using near real time data to personalize their customer experience and share granular item and store level point-of-sale data with CPG partners. Others users include DoorDash, PepsiCo and S&P Global.
“Snowflake Data Marketplace enables Pacific Life to access business-critical data from strategic business partner Experian, eliminating file transfers and ETL,” Kurpal Sandhu, Director of Data and Visualization, Pacific Life Insurance said.
“Snowflake Data Marketplace enables us to seamlessly deliver our updated intelligence data in near-real time to our customers, on a platform that scales as our data assets expand,” ZoomInfo Founder and CEO, Henry Schuck said. “With Snowflake’s Data Cloud, enterprises can access the ZoomInfo data they need, when they need it, and pair it with their own data assets, to unlock new insights and solve their most complex business problems.”
“Customers are already realizing incredible value from the data available through Snowflake Data Marketplace, and this is only the beginning,” said Christian Kleinerman, SVP of Product at Snowflake. “As more organizations and traditional industries digitally transform, they will shift how they view and leverage their data ecosystem, adding to and benefitting from the powerful data network effects of Snowflake’s Data Cloud to create new products that can sustain their businesses long-term.”
The quote from Snowflake’s SVP of Product highlights Snowflake’s vision for the Data Cloud, specifically calling out the benefits of network effects. As I mentioned, if Snowflake can build their ecosystem of participants faster than competitors, then network effects will put other providers at a disadvantage. This will create high switching costs that even overcome differences in features at the core data warehousing level. It would cement Snowflake’s position as the gorilla in the big data market.
Snowflake is rapidly building out their data sharing ecosystem by focusing on strategic industry segments to assemble clusters of participants. This approach helps bootstrap participation in the network. These industry solutions currently span eight focus areas:
- Financial Services
- Healthcare and Life Sciences
- Retail and CPG
- Advertising, Media and Entertainment
- Technology
- Public sector
- Education
- Manufacturing
Within each segment, Snowflake is recruiting data providers, partners and customers. Their product marketing extols the benefits of sharing data directly through the Data Cloud. Investors can click into each industry segment above to view participating data providers and customers leveraging the solution. You’ll quickly notice that each has major enterprises participating, leveraging Snowflake’s penetration into nearly half of the Fortune 500.
Of these, the financial services data cloud is probably the most developed. Snowflake highlighted this in a launch announcement in September 2021. Banking, insurance, fintech, and investment management customers can utilize the Financial Services Data Cloud to launch new data-driven products and services, with regulatory compliance already built in. They included a list of customers already making use of the service, including Allianz, AXA, BlackRock, Capital One, NYSE, Refinitiv, Square, State Street, Western Union and Wise.
As with the Data Cloud in general, participants can securely share data across their enterprise and with other partners. This meets regulatory requirements and includes enhanced governance controls like private connectivity across multiple public clouds, bring your own key encryption, built-in anonymization of sensitive data and integration with third party tokenization providers. These capabilities are all SOX compliant and incorporate a new standard called the Cloud Data Management Capabilities (CDMC) assessment, which is specific to the financial industry.
This focus on industry segments provides a further competitive advantage for Snowflake in building out the Data Cloud ecosystem. They acknowledge that each industry may have unique requirements, particularly around regulatory compliance. By customizing their solution to meet the specifics of each industry, like the CDMC assessment, they make it easier for participants to move onto the Snowflake Data Cloud without having to first conduct a regulatory or security compliance review. Competitive solutions that focus on generic, open data sharing capabilities wouldn’t have these advantages and require more vetting from internal auditors.
To further underscore their momentum in the financial services space, Snowflake recently announced a strategic partnership with Citi to redesign how post-trade financial data is distributed to other service providers within the financial industry. The partnership brings together Snowflake’s secure data sharing and multi-party permissioning capabilities with Citi’s industry-leading proprietary custody network spanning over 60 markets. This industry ecosystem will operate within Snowflake’s Data Cloud environment to offer participants a unique solution to control data sharing models and end-to-end transaction data flows across partners and customers.
Snowpark and Shared Functions
In June, Snowflake introduced Snowpark, which provides a runtime environment for data cleansing, analysis and AI functions. By providing the runtime in close proximity to the data, users will get significant performance benefits. The environment currently supports Java, Scala and soon Python. Data engineers and data scientists can use this environment to code up their own data processing functions and re-use them over time.
Of course, this enhances the usability of the Cloud Data Platform for single customer data processing jobs. At their Summit, Snowflake leadership teased the idea that these data mining functions could be shared across accounts in the future, similar to the principles behind Data Sharing. This adds another dimension to the shared data ecosystem, enabling not just sharing of data across a cluster of business partners, but to even distribute the processing functions that cleanse, analyze and train models for their industry data supersets.
A similar trajectory could be applied to functions on the Data Marketplace. Third party specialists could develop and market algorithms and ML functions customized for a particular industry. In the same way that selling enriched data sets on the Data Marketplace provides an opportunity for new businesses, specialized data processing functions could be marketed and monetized in a similar way.
Traction
Data Sharing, Snowpark shared functions and the Data Marketplace all underscore the future opportunity for the Snowflake Data Cloud. Played out, Snowflake could build out a huge ecosystem of data providers and customers. By focusing on clusters of use cases in specific industries, they will also address requirements unique to each sector, particularly as it relates to regulatory compliance. Each new capability will drive additional connections between customers, partners and third-party data vendors on the Data Cloud.
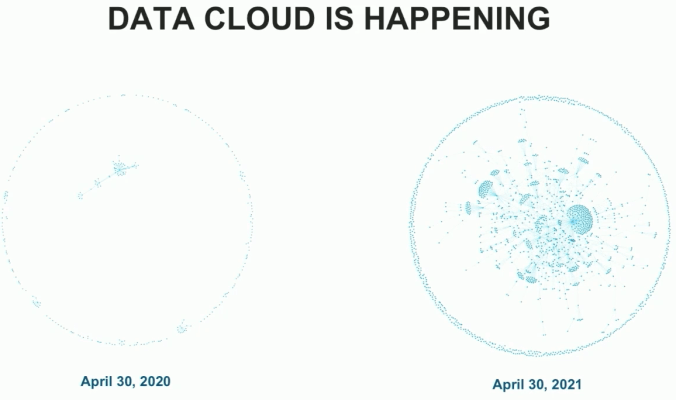
This growth in Data Cloud connections was illustrated in a slide as part of Investor Day in June 2021. Snowflake leadership displayed a diagram showing the growth of data sharing connections between customers over the course of the year. Each dot on the diagram above represents a customer. Lines between customers represent a data sharing relationship, which Snowflake calls an edge. As you can see, the number of edges increased significantly in the 12 month period from April 2020 to April 2021. This pace is continuing.
As part of Snowflake’s Q2 FY2022 results, they mentioned that the number of active edges had increased another 20% from end of April to end of July 2021. Their definition of “active” edge is important to appreciate. Snowflake leadership has set a high bar for measuring data sharing relationships to reflect real-world usage. In order to be considered an active edge, the parties must consume 40 or more credits of Snowflake usage each day over a 6 week period. In Q2, 100 more customers moved into this mode and 16% of all customers maintain at least one active edge. Given how early the data sharing motion is, this represents pretty substantial penetration.
As the Data Cloud continues to add more customers and edge connections between them, network effects will draw in more participants. As an example, Snowflake publishes a podcast called The Rise of the Data Cloud. They primarily use this to promote customer examples on the Snowflake platform. In a recent episode, the Chief Data Officer at ADP talked about how they are creating data services for the financial industry that provide useful economic indicators gleaned from summarized activity data of their business customers.
He discussed how they do support data exchange through APIs and file transfer, but increasingly the conversation for data sharing starts with the customer asking whether ADP has a Snowflake user account. He mentioned recently being asked that same question by the largest consulting firm in the world. He provided another example of partnering with the Intercontinental Exchange (ICE) to combine their data with ADP’s to create new data products, like in municipal bonds. These represent new business opportunities that ADP wouldn’t have pursued without data sharing.
Similarly, on a recent analyst call, Snowflake’s CFO mentioned that many customers now choose Snowflake because they have the ability to share data. They might not plan to use the sharing capabilities now, but want to know that they will have access to industry ecosystems and enriched data sets in the future. This is the promise of the Data Cloud and justifies what could be one of the largest TAM’s in enterprise software.
Databricks and Other Solutions
While I think Snowflake is the leader in this emerging space of data sharing, they aren’t the only provider expanding into this area. Other big data and analytics vendors are realizing the potential for supporting data sharing and the creation of supersets for processing. The fact that they are beginning to offer solutions to address this need validates Snowflake’s thesis.
Fortunately, Snowflake is well-positioned, as they have been working on their foundation for data sharing for several years. Snowflake’s Data Sharing capability has been promoted as far back as June 2017, with similar features to those I discussed above. Snowflake launched an early version of the Data Marketplace, called Data Exchange, back in June 2019. These were precursor capabilities for the Data Cloud.
Databricks is considered Snowflake’s largest independent (not a hyperscaler) competitor in the data management space. They bill themselves as an open and unified platform for data and AI. They promote a “Lakehouse” architecture, which blends the benefits of a data warehouse and a data lake. Their Lakehouse Platform strives to combine the data management and performance capabilities typically found in data warehouses with the low-cost, flexible object stores offered by data lakes. This blog post from January 2020 provides a good overview of the Lakehouse Platform approach and associated goals. A summary view is that the Lakehouse Platform provides:
- Ability to enforce schema and reflect traditional data warehouse architectures like star schema. Includes controls and capabilities for data integrity, governance and auditing.
- Support for SQL and ACID transactions.
- Ability to run disparate workloads, including data science, machine learning and analytics. Multiple tools might be needed to support these workloads but they all rely on the same data repository.
- Support for a diverse set of data types, both structured and unstructured, including images, video, audio, semi-structured formats and text.
- Decoupling of storage and compute, allowing the system to scale to many more concurrent users and larger data sizes.
Databricks initially used the Lakehouse label to differentiate themselves from other data warehouse and data lake solutions on the market, including legacy data warehouse providers and the hyperscaler product suites. They relegated Snowflake to the data warehouse category, and positioned the Lakehouse as a more complete solution. In the year and a half since then, Snowflake has added Data Lake capabilities to their cloud data platform along with support for semi-structured and unstructured data formats. We could view the feature sets for core data management as generally at parity at this point.
The big difference between the two platforms is around openness. The Databricks platform is built on open source software packages, with some of their own extensions. The primary underpinnings are based on Apache Spark, Delta Lake and MLflow, which the Databricks team created and maintains. Databricks has enhanced the performance of these projects and incorporated the improvements into their managed cloud platform, providing a benefit over just running the open source project. They still support open source file formats and protocols for integrations.
Snowflake’s platform, on the other hand, is based on proprietary software. They support APIs and languages for data exchange, ingestion and processing jobs, but the inner workings of the platform are effectively a black box. This loses the benefit of community support and customer comfort in source code review. It also can’t leverage prior expertise from data engineers and scientists who are familiar with the corresponding open source projects. At the same time, the Snowflake team has full control over their product roadmap. They can tune the engine for performance or modify capabilities without concern for effects on the downstream open source projects. Because all customers run on a cloud-based version of the software, all improvements roll out to all customers immediately.
As far as which approach is better, it depends. I think the trade-offs of a commercialized open source project versus completely proprietary platform are well-understood and will appeal to enterprise customers in somewhat different ways. The open source foundation generally favors companies with a strong engineering team that prefers to go deep into the underlying code, creating their own extensions and customizations to their own use cases. This flexibility generally brings more complexity and overhead to set up and maintain the system.
The proprietary approach favors those customers that prefer a full-featured, well-tuned solution out-of-the-box. It should do what they need, without requiring much customization. While the engineering team will have access to the functionality of the processing engine, their view will be obfuscated by programmable interfaces or admin screens. This approach is generally preferred by companies that don’t have or want to invest the engineering resources to manage the system themselves.
I think both approaches will work and both companies should succeed at building out thriving cloud-based data management platforms. We see parallels in other software sectors, where companies based on open source projects and proprietary platforms can co-exist. Linux versus Windows provides an analogy. More recently, Elastic (open source) and Datadog (proprietary) represent two different approaches. I have compared these two product strategies in past blog posts.
Applied to data management platforms, I think that a strict comparison of the feature sets and technology approaches between Databricks and Snowflake will result in a backwards looking view of the market’s evolution. As I discussed, I think that data sharing represents the future opportunity to build network effects for a particular provider and create a bias towards their underlying data management platform. I have discussed how Snowflake is addressing this opportunity head-on with their new Data Cloud offering, based on Data Sharing and the Data Marketplace.
In May, Databricks announced a data sharing solution called Delta Sharing. This capability is based on a new open source project, created by Databricks for the purpose. Delta Sharing will also be offered by Databricks as a hosted solution on their platform. While announced in May, it is currently available to customers on a limited basis, by signing up for a waitlist. In the meantime, any party can download, configure and host the open source Delta Sharing implementation themselves.

The main components of Delta Sharing are the Delta Lake provider, the Sharing Server and the Delta Sharing Client. The provider can be any modern cloud data storage system, like AWS S3, Azure ADLS or GCS, and of course Databricks Lakehouse, that provides an interface to their source data in the Delta Lake format (open source project sponsored by Databricks). The Delta Sharing Server is hosted by the cloud data provider and serves as a proxy to receive client requests, check permissions and return links to approved data files in Parquet format.
The Delta Sharing Client runs an implementation of the Delta Sharing protocol. Databricks already published open source connectors for several popular tools and languages (Pandas, Spark, Rust, Python) and are working with partners to publish more. Through the client connectors, end customers would be able to query the data shared as permissioned by the provider.
Databricks plans to host an implementation of the Delta Sharing protocol as a service on their Lakehouse platform. This would include hosting of the Delta Sharing Server and generation of an Audit Log to track usage. Databricks customers will have a native integration of Delta Sharing available through their newly announced Unity Catalog, which provides the ability to discover, audit and govern data assets in one place. Customers will be able to share data within their organization and across companies. Administrators can manage data shares using a new CREATE SHARE SQL syntax or REST APIs and audit all access centrally. Recipients will be able to consume the data from any platform that also implements the Delta Sharing protocol.

The goals of Delta Sharing are similar to that of Snowflake’s Data Sharing and Data Marketplace.
- Share live data directly without copying it.
- Support a wide range of clients.
- Strong security, auditing and governance.
- Scale to massive datasets.
I can appreciate Databricks’ approach here. They are trying to foster an ecosystem of data sharing without tying customers to any particular platform. It represents an open method of data sharing which would work across all players, including the hyperscalers. In this way, it is a strategic move, which could leapfrog Snowflake’s ecosystem building by extending it across all providers. Also, it reduces the benefits of network effects for one provider, assuming all providers agree to support the protocol and implementation.
On the other hand, Databricks’ design requires a good amount of configuration and set up for each provider and the commercial clients. For customers that want to combine data sets with multiple parties across an industry workflow, it’s not clear to me how well the solution would work. I don’t see plans for monetization or incentives for data providers, similar to the features in Snowflake’s Data Marketplace. Finally, it would need further development to enable the Snowflake concept of shared functions in Snowpark. To do that, Delta Sharing would likely need to set up another sharing server optimized for running code in a multi-tenant fashion.

The initial set of launch partners is limited, but we can assume this will grow over time, given Databrick’s position in the market. Snowflake’s Data Sharing capabilities and Data Marketplace participants are more mature and extensive at this point. This is understandable given their multiple year head start. However, given Databricks’ open approach and ability to steer customer marketing away from “closed ecosystems”, this will be an initiative to monitor.
Hyperscalers
The hyperscalers, of course, all offer big data platforms. They went through a similar evolution as Snowflake, starting with a data warehouse and then adding on data lake support and unstructured object storage. They too recognize the benefits of building data sharing ecosystems, but will be constrained by perception of their underlying business interests.
The larger problem that will limit their ability to foster a robust data sharing ecosystem by industry has to do with competitive concerns. Hyperscalers all have other business units that might compete with the participants in an industry ecosystem. Examples are in retail, healthcare, media and advertising and financial services. Participants from these industries will hesitate to put their data ecosystem on AWS, Azure or GCP, if they worry that other divisions of those companies may compete with them. Insights gained through shared data analysis would in theory be accessible by the hyperscalers, regardless of what business firewalls they claim are in place. I experienced this first hand at an AdTech company for the CPG retail industry, where customers strongly encouraged us to move off of AWS and onto Azure due to competitive concerns.
Rather than competing with their potential customers, Snowflake focuses primarily on data storage and compute. Snowflake is not trying to roll their own business services. Rather, they partner with best of breed providers to enable processing on top of their storage and compute. Similarly, they are not trying to market their own data visualization tools, ETL solutions, etc. This deliberate strategy allows other technology companies to build businesses on top of Snowflake and resell their value-add services over the Snowflake platform. In the long run, this approach should generate more revenue than Snowflake’s own duplicate product offerings in these areas could have.
As it relates to the Data Marketplace, the same principle applies. Snowflake is providing the tools for customers to share data and perform their own analysis. Because Snowflake controls the data plane, they provide the appropriate capabilities for data governance, access controls and sharing patterns. With those tools, customers are able create their own data exchanges and run AI/ML processes over the data superset. Snowflake just gets out of the way, knowing that in the long run, this ecosystem will generate more utilization of storage and compute. More importantly, network effects will bring more participants onto the platform.
If data warehousing becomes commoditized, then the network of data exchange through the marketplace will be the differentiator. This could ultimately drive Snowflake into the pole position of the cloud data management space. As data warehouse/lake/lakehouse capabilities become undifferentiated, then the network of data sharing relationships and the higher level insights created will be the value-add for participants on Snowflake’s platform. Similar to the example with ADP, participants will default to asking potential members if they already have a Snowflake account.
Snowflake Business Performance
With this background and potential in mind, let’s take a look at how Snowflake’s business has been performing and what we could expect in the near term. We can also try to extrapolate out Snowflake’s longer term potential, given some guidance provided at their Investor Day in June.
Earnings
Snowflake reported Q2 FY2022 (May – July 2021) results on August 25th. The market favored these results, pushing the stock up 7.6% the next day. SNOW eventually peaked near $324 on September 15th, increasing 15% from about $284 before the earnings release. So far in 2021, SNOW has lagged most other growth stocks, up around 8% YTD. This is also down about 29% from the peak price of $429 briefly hit in November 2020.
Top Line Growth
For Q2, revenue was $272.2M, up 104% year-over-year and 19% sequentially. This beat analyst projections for $256.7M, or about 93% of annualized growth. In Q1, annualized revenue growth was 110% and 20% sequentially. So, Q2 represented a little deceleration. Snowflake also reports and guides to product revenue, which excludes professional services and provides a measure of demand for the core platform. In Q2, product revenue was $254.6M, representing 103% year-over-year growth. Snowflake’s Q2 product revenue estimate issued in Q1 was for $235-240M, up 88-92%. This means that Snowflake beat their own product revenue estimate by 13% of annualized growth or about $17M.
For Q3, they are projecting product revenue of $280-285M, which would represent 89-92% annual growth and 11% sequentially. What is interesting about this product revenue growth projection is that it is about inline with the original projection for Q2, implying no deceleration in Q3 if the level of outperformance is the same. Also, a same-sized beat would result in 18% sequential growth. Applied over 4 quarters, that translates into 94% annualized growth.
For the full year, they raised their product revenue estimate to a range of $1.06B – $1.07B, representing 91-93% growth. The estimate from Q1 was for $1.02B-$1.035B, or 84-87%. Coming out of FY21, the initial estimate was for 81-84% growth. The Q2 full year product revenue raise of about $37M exceeded the Q2 beat of $17M by about $20M, indicating continued forward growth for the remainder of FY2022.
RPO activity provides a more mixed view. At end of Q2, Snowflake reported total RPO of $1.53B, up 122% year/year and 7% sequentially. For Q1, Snowflake reported total RPO growth of 206% y/y and 8% sequentially. The low sequential growth in total RPO is concerning and would imply that future revenue growth will slow down. The drop in annualized growth was somewhat mitigated by a large $100M three year deal closed in Q2 of the prior year.
Snowflake also reports current RPO, which represents the percentage of total RPO that they expect to realize as revenue in the next 12 months. For Q2, they expect 56% of total RPO to be recognized as revenue in the next 12 months. This represents an increase of $86M over Q1’s current RPO value (which was about $773M or 54% of total RPO). This view shows a sequential increase of 11% from Q1. Better, but still doesn’t align with the revenue growth projections.
This will be a metric to watch, albeit somewhat. After Snowflake went public, they encouraged investors to consider both revenue and RPO growth to anticipate the future opportunity. In more recent analyst events, the CFO has backed off this, focusing more on revenue growth and forward projections. I think that Snowflake’s consumption model and contract duration variability make RPO a less useful indicator. Anecdotally, it seems that customers contract for what they they anticipate using near term. Then, they either exceed that amount or expand the contract obligation incrementally over a year. Snowflake earns revenue on actual usage, not contract commitments. Regardless, this is a source of confusion for growth investors.
On the earnings call, Snowflake leadership shared some other growth metrics. As they have been focusing on particular industries, they reported product revenue growth of 100% y/y in financial services and 200% in health care. International is also growing rapidly with EMEA up 185% y/y and APAC up 170%.
Profitability
Snowflake has been generating gradual improvements in operating leverage and margins. Product gross margin was 74% in Q2 on a Non-GAAP basis. This is up from 72% last quarter and 69% in FY21. Going back to FY2020, Non-GAAP gross margin was 63%, meaning that Snowflake has improved gross margin significantly in the last 2 years. This is attributed to larger scale (discount pricing from cloud vendors) and growth of enterprise customers.
Operating margin is improving as well. For Q2, Snowflake reported -8% Non-GAAP operating margin, up from -16% in Q1 and -44% a year ago. That obviously represents a rapid ascent toward profitability. Adjusted FCF was positive for the third quarter in a row at 1% for Q2. This is up from -33% a year ago. In Q1, Snowflake had projected Non-GAAP operating margin for Q2 of -19%, so they beat their estimate by 11%. For the full year, they are now projecting -9% operating margin, up from the prior estimate for -17% issued with the Q1 results.
Customer Activity
Of all growth metrics, I think that customer activity is becoming the most visible indicator of Snowflake’s long term potential. I think Snowflake differs from some of the other software infrastructure companies that I cover due to the extremely large spend that they can potentially capture from their biggest customers and how much that can conceivably expand over time. On past earnings calls, leadership has commented that Snowflake spend is often the second largest line item on an enterprise’s IT budget, just behind their overall cloud hosting expense. Given the rapid increase in data and the value realized by mining it, I am not surprised.
Snowflake’s speed and scale of spend expansion with some customers is certainly unique. On a recent analyst call, the CFO provided an example of a large retail customer in Europe. The customer signed up with Snowflake in 2019. After a data migration, they generated about $1M in revenue in 2020. He expects them to consume over $8M of usage in 2021 and could go as high as $20M next year. That is a 20x expansion in two years – virtually unheard in other software infrastructure categories. As another example of scale, in Q2 of last year, Capital One signed a three year $100M contract.
Even with these large spend amounts, Snowflake doesn’t consider these major customers to be fully penetrated. Given that data volumes continue to increase and these customers keep conceiving of new analysis workloads to harvest insights from their data, further expansion from here is understandable. These factors help explain Snowflake’s extremely high net revenue retention rate at scale.
In terms of specific Q2 performance, Snowflake ended the quarter with 4,990 total customers. This is up 60% from 3,117 a year ago and 10.1% sequentially from Q1. The sequential growth rate in Q1 from Q4 was 9.5%, so Q2 saw a slight acceleration in customer adds. Of total customers, 212 are in the Fortune 500, up from 194 in Q1 and 158 a year ago, representing 34% y/y growth and 9.3% sequentially. Recall that analysts had flagged Fortune 500 customer growth as an issue in Q1 after adding only 4 of those. Snowflake also shared that 462 of the Global 2000 are customers.
These enterprise customers are contributing to a rapid increase in customers spending more than $1M in product revenue over the last 12 months. In Q2, 116 customers exceeded this spend level, up from 104 in Q1 and 56 a year ago, representing 107% y/y growth and 11.5% sequentially. Interestingly, Snowflake leadership disclosed that only 25% of the Fortune 500 customers were included in those spending more than $1M in trailing product revenue. They explain the difference as large international customers and smaller digital natives that are heavy data processors.
The most staggering metric for Snowflake is their Net Revenue Retention Rate. This is measured over a two year period, comparing spend in the customer cohort from the first year to their spend in the second year. This metric includes churn. For Q2, NRR was 169%, up from 168% in Q1 and 158% a year ago. The fact that this value is increasing at a $1B revenue run rate is impressive. It underscores the massive expansion motion that I discussed earlier.

Looking forward, it seems this high net expansion rate is durable. On the Q2 earnings call, analysts asked the CFO what he thought the future trajectory of NRR might be. He responded that Snowflake will stay above 160% for the rest of FY2022. While he expects NRR to come down at some point in the future, he thinks it “will be well above 130%, 140% for a very long time”.
It is this expansion of both total customers and their annual spend that could keep Snowflake’s revenue growth at high rates longer than would be normally expected for a company of this size. Even if total customer growth drops to 20-30% annually, NRR in the 130-140% range would keep revenue growth above 50%. Over the next couple of years, I think it is reasonable to expect revenue growth higher than this. While Snowflake does register an extreme valuation above 90 P/S, a couple of years of revenue compounding will quickly bring that valuation in line with their high growth rate.
Looking Forward
Snowflake leadership held their first Investor Day in June. They set a headline goal to reach $10B in product revenue by FY2029, which would be an order of magnitude increase from the FY2022 target of $1.065B. They detailed some of the factors that will make up this product revenue, primarily hinging on growth in $1M+ customers and their average spend.

They also included some other financial targets for FY2029. Related to revenue, they see product revenue growth exiting FY2029 at a value of at least 30%. Non-GAAP product gross margin will be about 75% (slightly above current levels). Operating margin will improve to at least 10% and adjusted FCF to 15%. During the presentation and particularly the QA session, leadership gave the impression that these metrics were a baseline and included expected conservatism.
If we focus on the revenue growth, we can try to model out how this might progress towards FY2029 from this fiscal year’s target. Growth rates are my assumptions, based on Snowflake’s current velocity, customer activity and product positioning.
| Fiscal Year | Product Revenue | Growth Rate | ||
| 2022 | $1.1B | 98% | ||
| 2023 | $1.98B | 80% | ||
| 2024 | $3.36B | 70% | ||
| 2025 | $5.376B | 60% | ||
| 2026 | $8.064B | 50% | ||
| 2027 | $11.29B | 40% | ||
| 2028 | $15.24B | 35% | ||
| 2029 | $19.8B | 30% |
Investors can play around with this model, but I think the growth rate projections are reasonable given Snowflake’s unusually high and durable net expansion rate. Also, during the Investor Day event, leadership stressed that the original model did not make any assumptions for new product offerings or lines of business. I think it is fair to assume that Snowflake will increase their reach into other markets or create additional revenue streams from new offerings like the Data Marketplace.
While it might be hard to imagine a software infrastructure company with a $20B revenue run rate, Snowflake’s unique position at the nexus of the explosion in data creation, processing and sharing make that conceivable. I think it is quite possible that the market for big data management, driven by AI processing, reaches a $1T by the end of this decade. For Snowflake to occupy 2% of that TAM is a reasonable assumption.
Investor Take-Aways
Snowflake is well-positioned to capitalize on the next big opportunity in information technology evolution, centering on harnessing increasingly larger data sets to generate business insights and machine learning models that deliver more intelligent software applications and services. While most of the focus on big data processing has been on assembling, curating and mining data within single organizations and companies, creating new ecosystems of shared data and workflows across industries represents the next level of interaction.
With their Data Cloud, grounded in enabling customers to securely share data, Snowflake is building network effects. Each new participant in an industry data ecosystem will bias towards Snowflake’s solutions in order to make sharing as seamless as possible. Snowflake is already demonstrating traction in building these data sharing relationships between customers. Industry specific clusters, addressing regulatory considerations and custom requirements, will differentiate Snowflake’s Data Cloud from competitive offerings that focus just on data management within a single enterprise. The Data Marketplace takes this a step further, by incentivizing third parties to create value-add data sets (and eventually data mining algorithms and machine learning models) to share within industry clusters.
All of these forces should combine to provide Snowflake with an unusually large addressable market. Customer spend expansion will likely be much more durable over time than for comparable software infrastructure providers. Coupled with total customer growth, Snowflake should be able to maintain a high level of revenue growth for much longer than investors would normally expect at their scale. This revenue compounding will bring down the valuation multiple rapidly and enable further upside as the growth rate continues.
For this blog, I hadn’t set a price target on SNOW previously, but do own shares. Given what I see as a huge opportunity for the data sharing ecosystems that Snowflake can enable, I am initiating coverage and setting an end of calendar year 2024 price target of $940. This is based on my assumption for Snowflake FY2025 product revenue of $5.376B with a growth rate of 60% that year. Total revenue is generally about 7% higher than product revenue for a total of $5.75B. That growth rate implies a P/S ratio of about 50 at today’s valuations for software infrastructure peers. That yields a target market cap of $287B or 3.1x today’s value. Current SNOW price of $304 x 3.1 lands the 2024 target price at about $940.
While I acknowledge that Snowflake already has a high valuation, I think they can grow revenue at a high rate for longer than currently expected. This should allow the valuation multiple to remain elevated, with a more gradual reduction over time. Revenue growth compounding will do the rest. Even looking to next year, I have modeled $2.1B in revenue, which implies a forward P/S multiple of about 43, already allowing for some upside. In consideration of this, I have increased the allocation to SNOW in my personal portfolio. It is now my third largest position at 16%.
NOTE: This article does not represent investment advice and is solely the author’s opinion for managing his own investment portfolio. Readers are expected to perform their own due diligence before making investment decisions. Please see the Disclaimer for more detail.
Other Resources
Here are links to some other online resources that readers might find useful:
- Peer analyst Muji over at Hhhypergrowth has written extensively about Snowflake and platforms for data & analytics. This is must read content for investors and he goes much deeper than I have on these big data concepts and the broader landscape of technology solutions.
- Snowflake conducted an Investor Day in June 2021, which coincided with their full product Summit. The Investor Day video should certainly be viewed by investors. Summit provides a broader set of information and is behind a light registration.
- Databricks held their Data + AI Summit in May 2021. The full keynote is worth watching for general Databricks coverage. Specific to data sharing, the Delta Sharing announcement video covers content mentioned in this blog post.
- An old Snowflake Data Sharing video from July 2017, highlighting how long Snowflake has been working on their data sharing platform and the capabilities available at that time.
- The Snowflake Rise of the Data Cloud podcast provides real-world examples in digestible snippets from customers and partners. This is a rich source of insight into the future plans around data management and sharing for several large companies.


Thanks Peter, enjoyed reading this. Your example regarding personalized insurance premium really helped understand how network affects could become a major tailwind. Regarding valuation, I suppose the only concern would be if market would continue rewarding these businesses with a high P/S ratio?
Correct – I can’t really speak to the relative position of valuations for all software infrastructure companies at this point. Historically, they appear high, but that could also be because the market is recognizing the large opportunity ahead.
Hi Peter, great post as usual. Seems like you added to $SNOW while trimming $CRWD. Do you see any issues with $CRWD? Thanks.
Hi – thanks. No execution issues with CRWD. They will continue to be a leader in the security space. The only limitation per se is with the addressable market. After this piece on SNOW, I realized that with data sharing and the data marketplace, Snowflake has significantly expanded their TAM with the Data Cloud. That could literally be a $1T market in 10 years. I think that will be larger than the market for security over the same time.
However, I acknowledge this is splitting hairs and happily have a large allocation to security plays (CRWD, ZS). I also recognize that my security allocation really represents the combination of CRWD and ZS in my portfolio, versus SNOW which is just data. On that level, I think the balancing makes sense.
As always, Peter, your commentary is non-pareil, as you reach far and wide to corral all arguments in your analysis, which helps to make it extremely insightful (no surprise, that!) but also a boon for other investors. Thank you. And thank you for the early-morning chuckle…
“Snowflake is not trying to roll their own business services.”
Questions.
01. Put on your C-suite hat for a moment. On a *qualitative* level, do you believe Snowflake has the chops to execute its grand business plan? After all – and if I understand you correctly – Snowflake strives not only to command the data warehouse space but to commodify it to achieve the company’s grander, far-reaching, and all-encompassing vision. That is a lot of bite to chew… but can they do it? Do you have confidence they will do it successfully? Execution risk is always a ‘thing’ – especially for technology companies out on the bleeding edge.
02. Why not also invest in Databricks (when available)? The data space looks large enough for two companies and two paradigms to succeed. (He says innocently.) Just as there are two distinct visions from two primary vendors, there are many, MANY customers for each vision of how the data world shakes out.
I welcome your comments.
Thank you,
David
PS. Have fun at the conference this weekend!
Hi David – thanks for the feedback. FinTwit Conference was a blast. We missed you.
1. Fair question. I think so, as these are additive layers for Snowflake. The core technology of the Cloud Data Warehouse has been baked for several years. Then, they expanded to support data lake and other data types, in the Cloud Data Platform. Further expansion to data sharing, marketplace and Snowpark are layers over those, as part of the Data Cloud. With that aggregate approach, I think the technology vision is achievable. Selling the vision to all participants will be the challenge.
2. I would consider an investment in Databricks. I think most of the competitive chain rattling relative to Snowflake versus Databricks is coming from Databricks. I imagine the two will be able to co-exist, with each focusing on different strengths.
Could a data marketplace run on an edge network?
Interesting question. Yes, in theory, but we would want to think through the usage. The main idea behind Snowflake’s data marketplace is to provide access to curated third-party data sets that would enhance big data mining and analysis (AI/ML insights). For that use, of course, locating the data marketplace data set in proximity to (or on) Snowflake’s Data Cloud makes sense.
However, you could make the same proximity argument for a globally distributed edge application, that might make use of a real-time, third party data set. Certainly, an example like Citi’s deal with Snowflake to distribute post-transaction financial data might perform better on an edge network for a latency sensitive application (like trading perhaps).
Thanks for the reply, and thanks for your highly informative articles.
can you talk about where cloudflare is going with s3?
Sure – Cloudflare’s new R2 product mirrors much of the functionality of AWS S3, but with lower usage cost and no egress fees. I think R2 is an important step for Cloudflare, as it offers an object store, but on a globally distributed edge network. Cloudflare is quickly creating all the “primitives” that a developer would expect in order to build modern software applications on Cloudflare’s platform. While we can debate the benefits of edge networks in the near term for the current slate of Web2.0 applications (where latency isn’t critical), if a developer can build the same application on Cloudflare’s platform, then they may as well take advantage of the inherent speed benefits.
Hi Peter,
You compared in your latest newsletter Cloudflare vs. AWS Wavelength. Since the former has a serverless, multi-tenant model, the two tend to have different use cases. Could you also compare Cloudflare vs. Lambda@Edge, which is also built on CDN infrastructure and adopt serverless model? Thanks.
Hi Joan – Lambda@Edge isn’t really much different. That is built on Cloudfront, which has more limited locations and distribution. As a CDN, Cloudfront never gained that much traction. Locating edge compute there probably won’t change much. Also, I don’t believe Lambda@Edge is truly multi-tenant.
Hi Peter
Any thoughts on Gitlab?
All the best!
Gitlab offers a great product and is expanding into other interesting areas beyond just being a code repository. I can’t really provide insight into a position for the upcoming IPO and whether that makes sense, beyond recognizing that the company has a strong growth trajectory ahead of it. I will probably cover them in a future post on developer tooling. I won’t consider a portfolio position for a quarter or two, as a standard personal preference with all IPOs.