Snowflake held their annual user conference, Snowflake Summit, in Las Vegas last week. This included a number of product announcements and followed their Q1 earnings report, where the CEO promised “our most significant product announcements in four years.” Beyond the new product features, Snowflake updated their overall platform positioning and provided insight into future product directions. Mixed in with this was an Investor Day session, which included more granular financial detail. In this post, I will focus on the platform updates and product strategy, as I they provide the foundation for the next phase of Snowflake’s growth.
Audio Version
View all Podcast Episodes and Subscribe
High-level Strategy
Over the course of Summit, it became clear that Snowflake has expanded their vision for the Data Cloud and are eager to move beyond their origins as a cloud-based data warehouse. Since inception, Snowflake’s product trajectory has been tied to disrupting conventions in data storage. Initially, they set out to improve the standard way of handling data warehousing. This was targeted at traditional data warehouse solutions, that involved purchasing an on-premise appliance infrastructure that was difficult to scale and share between teams. Snowflake disrupted that model by migrating the appliance to the cloud and separating compute from storage. Multiple teams could work on the data in parallel and capacity planning became more flexible.

The lion’s share of the use cases for Snowflake’s data cloud platform revolved around these traditional data warehouse analytics use cases early on. As Snowflake gained more customers on their multi-tenant data platform, they observed how much effort customers wasted copying and distributing data to other partners and their end customers. Any time two parties wanted to exchange data with one another, they relied on one-off processes. Popular solutions for data exchange are file transfer (SFTP) and APIs. However, these incur costs and overhead to set-up, maintain, secure and govern the data. Engineering teams within customer organizations would go through endless cycles of setting up yet another custom job to exchange data with a new partner.
Snowflake solved this through Data Sharing and Clean Rooms. Data Sharing enables controlled sharing of data between customers, partners, vendors and third-party providers. To enable this, the Data Cloud layers on several incremental capabilities:
- Ability to define any subset of data for sharing. The data set can be filtered down into a single view, cut by desired parameters. For example, a retailer could share product sales data with vendors, but filter it by product supplier.
- The data view is materialized and kept up to date. This means it is not a copy and doesn’t require the creation of a separate data store for the consumer in order to examine it.
- Strict governance controls. Users can create flexible data governance and security policies and apply them across different data workloads. They can grant access on a granular level to individual consumer user accounts and revoke permissions instantly.
- Any materialized view can be used just like a data set on the core cloud data platform, meaning users can run data analysis, machine learning and data applications on top of it. Because the view is continuously kept updated with source data changes, the consuming application doesn’t have to request a new copy.
The implications of these sharing capabilities were significant. They completely side-step the current models for data sharing, which often require manual batch jobs, processing large flat files of data dumps (like csv files), one-off API integrations and even newer data streams. By using a temporal view of the shared data, the provider doesn’t need to worry about the consumer keeping a copy after the relationship is over. Once a data sharing model is set up, it can be easily duplicated across many consumers.

Data Sharing is enhanced by clean rooms, which allow two participants to share data, but only from a relevant overlap. As an example, a retailer may want to offer a promotion to their customers on a media provider. The two can utilize a clean room to determine the intersection of their customers based on a common attribute like an email address. Only the customer list in common is shared. The rest of the data from each participant is kept secret.
This capability would not be possible with the legacy method of data exchange, which involved data dumps or API queries. In those cases, one party would be privy to the full data set. To get around this, the partners could contract with a neutral third party to find the intersection, but this adds latency and cost to the process.
With Clean rooms, Snowflake customers can create Secure User Defined Functions (UDFs) in SQL or Javascript that are run on the shared data sets. Only the output of the functions is made available to both parties. Generally, this would represent an intersection of two data sets. Besides the efficiency of data sharing, clean rooms provide another capability that encourages industry participants to move data onto the Snowflake platform.

These capabilities in Data Sharing and Clean Rooms are arguably “disrupting” the market for data collaboration, as Snowflake’s leadership team eluded. We can see evidence of this in the rapid growth of Data sharing usage. The images above provide a visual summary. In April 2020, few customers had an active data sharing relationship enabled. An active data share is defined as a stable edge, in which two parties consume actual Snowflake credits to maintain a data sharing relationship for a period of time. As of April 2022, you can see the bloom of data sharing connections, represented as all the blue lines between the dots.
As part of the Q1 results, Snowflake leadership provided some metrics on data sharing. They said that the number of stable edges grew by 122% y/y. At that point, 20% of customers have at least one stable edge, up from 15% a year prior and 18% in Q4. Taking total customers into account for the year/year comparison, 1,264 customers had at least one stable edge in Q1, versus 680 a year before. This represent 86% more customers with a stable edge year/year. The increase in customers using data sharing was 18% quarter/quarter.
Finally, in the financial presentation at Summit, the CFO revealed that 63% of $1M+ customers have a data sharing relationship in place. This is over 3x the 20% of total customers with at least one stable edge. This fact demonstrates the importance of Data Sharing as a driver of large spend. It also underscores the value that Data Sharing provides for these larger customers.
Application Sharing
Why rehash all of this? Because the next stage of Snowflake’s development is to extend the sharing concept by moving up the stack and enabling software applications to run directly on the Data Cloud. Snowflake intends to provide a full framework and toolset for developers to build, deploy and host data-driven applications.
During the opening keynote, the Snowflake leadership team identified several core concepts for their product strategy going forward.
- Have all enterprise data in the Data Cloud (or as much as possible).
- Enable seamless sharing of data between partners, customers and industry participants.
- Address all workloads necessary for data analytics and delivery of data rich applications.
- Support deployment on a global basis, supporting data sovereignty requirements by country.
- Platform self-management – provide a working solution out of the box that doesn’t require significant overhead from DevOps and data engineering to maintain.
- Governance – extend full control to data access, privacy and compliance across all data sets and application usage.
- Incentivize partners – foster an ecosystem of data providers and application builders on top of the Data Cloud through monetization features.
- Support programmability – bring the applications to the data, not the data to the applications.
It’s the last bullet that received the most attention during Summit. Data applications should be shared in a secure and private way, using the same patterns as Data Sharing. Developers can build applications in the abstract, pointing them to their own copy of data for testing purposes. When customers are ready to utilize a third-party application, they provision it to run in their Snowflake instance with direct access to their data. This “sharing” of application context is critical because it prevents the developer from having access to the customer’s underlying data.
The current model of SaaS applications assumes the SaaS vendor will maintain a copy of the customer’s data. While this architecture has existed for many years, it is inherently wasteful and insecure. The customer has to import their data from disparate SaaS applications through ETL pipelines in order to consolidate it into one place for analysis. This approach creates two copies of the data and a lot of overhead in managing data pipelines.
Along those lines, if the SaaS vendor experiences a data breach, then the customer’s data is exposed. Similarly, if the customer decides to terminate their relationship with a particular SaaS vendor, they have to trust that the vendor deletes all their operational data, including all back-ups (which really isn’t feasible).
Snowflake’s vision is to bring the applications to the data, not the data to the applications. With Data Sharing and now “application” sharing, Snowflake is making that more feasible. During the Summit conference, Snowflake introduced this concept of running “native” applications. To further expand the development environment in which these applications run, they have fully rolled out Python support in Snowpark, completed the integration with Streamlit and provided a new data storage engine for transactional workloads.
I don’t expect enterprises to abandon all their custom developed and rented SaaS applications to consolidate all data stores onto the Snowflake Data Cloud. But, I find the argument compelling for many use cases, assuming Snowflake can continue building out the capabilities of the development environment. Applying this strategy, we can start to visualize new workloads for Snowflake. As part of the Investor Day briefing at Summit, the leadership team quantified the potential impact by expanding their addressable market target.

With an expanded developer toolset and application runtime environment, Snowflake could start to address software applications with heavy read workloads. Typically, application workloads are supported by creating an ETL job that pulls the data out of Snowflake and loads it into another database, which is optimized for concurrency and short response times. These databases are typically of the OLTP family, directly connected to consumer applications. Examples might be MySQL, PostgreSQL, MS SQL Server, Oracle or even MongoDB.
To accomplish this, Snowflake would need to provide a database engine with high concurrency and low response times. That was another one of the major announcements at Summit (I will detail below) with their Unistore data engine and Hybrid Tables. These are designed to support transactional application use cases. The main design difference is that storage and retrieval is oriented around traditional row-based access patterns, which better aligns with the use cases for a relational application data store.
During Summit, the Chief Data and Innovation Officer from Western Union presented. He discussed many aspects of Western Union’s relationship with Snowflake. They have migrated 34 data warehouses over 20 months to the Data Cloud and now rely on Snowflake for the core of their analytics and data processing engine. One of their most critical workloads is to determine pricing for their products across all countries of operation. This data is updated frequently to optimize for a number of business and macro factors.
Snowflake currently runs all the analytics and data science jobs to set pricing for Western Union’s products. Once the pricing is determined, the data is currently copied out of Snowflake into a Cassandra cluster to be the read source for all customer facing applications that need pricing data. That Cassandra cluster is designed for high concurrency and reliability, with fast response times. For Western Union pricing requests, the cluster currently processes about 15,000 queries a minute (250 a second).
The Chief Data Officer explained that he looks forward to a solution from Snowflake that eliminates the Cassandra cluster, and has been pushing for an integrated transactional data engine within Snowflake. Assuming it could handle the load, that would simplify the Western Union back-end, by removing the overhead of managing Cassandra separately and maintaining an ETL process to sync it with Snowflake. Considering that Snowflake generates the pricing data, it is just simpler to serve it to the pricing application from the same data store.
As the use case for Western Union exhibits, I think expanding support for transactional use cases will generate new utilization growth for Snowflake. These workloads will presumably be priced on a consumption basis, just like the core storage and compute billing for other Snowflake uses. By moving more workloads to the Data Cloud, Snowflake will have other avenues to expand customer usage and drive revenue.
Snowflake’s strategy revolves around the notion of keeping as much data in the Data Cloud as possible. By adding support for transactional data access workloads, they are reducing the need for customers to copy data out to other databases in order to serve data to customer-facing applications. Expanding support for application development within the Snowflake environment, whether through Snowpark (with Python), Streamlit or new native applications, also helps keeps customer data in one place by bringing the applications to the data. The Snowflake Marketplace and Powered By programs take this a step further, by incentivizing developers to build new applications within the Data Cloud with controlled access to customer data.
Trying to address every use case where a customer needs to move data out of Snowflake for some purpose could create an awkward relationship with Snowflake’s ETL partners. During the Investor Day session, the SVP of Product even acknowledged this. Snowflake isn’t competing with the ETL providers. Snowflake’s vision played forward just reduces the need for them to move data between Snowflake and vendor applications. While I don’t see a future world where all enterprise data of every type and workload consolidates onto the Data Cloud, I can appreciate the strategy that more of it will.

This vision culminated with the chart above, comparing the Data Cloud with other solutions across the criteria that Snowflake considers important. While it is biased towards Snowflake by setting the categories and assigning their ratings, we can also start to appreciate the directions that Snowflake is moving and how they are differentiating themselves from other data platforms. That’s not to say that Snowflake’s offering is better overall than competing providers in all cases – it is just aligning towards a specific set of goals and user audiences.
Sponsored by Cestrian Capital Research
Cestrian Capital Research provides extensive investor education content, including a free stocks board focused on helping people become better investors, webinars covering market direction and deep dives on individual stocks in order to teach financial and technical analysis.
The Cestrian Tech Select newsletter delivers professional investment research on the technology sector, presented in an easy-to-use, down-to-earth style. Sign-up for the basic newsletter is free, with an option to subscribe for deeper coverage. Software Stack Investing members can subscribe for the premium version of the newsletter with a 33% discount.
Cestrian Capital Research’s services are a great complement to Software Stack Investing, as they offer investor education and financial analysis that go beyond the scope of this blog. The Tech Select newsletter covers a broad range of technology companies with a deep focus on financial and chart analysis.
Product Announcements
Snowflake wants to evolve from being considered just a data storage engine to becoming a software stack for delivering data experiences. Specifically, this means providing more capabilities that enable developers to build applications that access data directly in Snowflake. The leadership team keeps emphasizing the theme to “bring the applications to the data, not the data to the applications.” This is at the core of the announcements at Summit and Snowflake’s vision going forward.
As part of that, the team rolled out a new diagram representing the primary components of the Snowflake platform. You can see the prior version of the platform diagram (upper diagram), along with the new version introduced during Summit (lower diagram).


The new version of the diagram included a number of changes. These all tie back to the strategy and announcements as part of Summit.
- Data Sources has been updated to reflect the types of data that the Snowflake Platform can ingest, reflecting the formats of structured, semi-structured and unstructured. With announcements at Summit, data streams can be directed at the platform as well.
- On the right side, Data Consumers has been changed to Outcomes. This maps more cleanly to the business purposes that Snowflake is trying to enable. These move beyond driving analytics insights and ML-powered predictions to incorporate the value for Marketplace partners to monetize their data sets and create new applications for enterprises to apply directly to their data.
- Snowgrid was elevated as an infrastructure layer that enables Snowflake to work across public and private clouds. Maintaining consistent interfaces and performance between hyperscalers and extending even to on-premise data storage is fairly complex and represents a competitive advantage.
- Snowflake’s three different data storage engines are explicitly named, for use by the application workloads on top. These are the existing data warehouse and data lake engines, with the new Unistore solution that serves transactional workloads.
- Cybersecurity is called out as a stand-alone top level use case. This aligns with Snowflake’s announcement of a new Cybersecurity Workload prior to Summit. I think this top-level treatment is indicative of the size of the opportunity as Snowflake sees it (attributed $10B of TAM to this category). It also implies there may be other product categories that Snowflake may pursue in this manner.
- Changing Data Sharing to Collaboration emphasizes the more active nature of enabling positive outcome through sharing of data. It elevates the more mechanical aspect of streamlining data exchange between two parties to building stronger relationships between companies.
These changes to the platform model serve to position Snowflake centrally as a data platform upon which customers and partners can build richer data-driven experiences. This underscores the theme that the software application can exist in the same environment as the data. It also argues for less duplication of data and eliminating silos, making the case that all enterprise data could remain in the Data Cloud. Cybersecurity is one example of this theme. Security analytics could be performed on all enterprise data in one place, versus shipping logs off to another security vendor’s data platform for analysis.
What’s compelling about this change in product positioning for Snowflake is that none of it requires modification of the business model. Snowflake still earns revenue from the consumption of compute and storage on its platform. They are simply expanding the use cases for that consumption. By emphasizing the removal of data duplication (and the inherent cost savings and security posture improvement), they are also justifying the expansion of Snowflake spend for customers by replacing expense that might have gone to other vendors.
The application of this model to Cybersecurity provides further insight here. A typical SIEM provider is performing two functions. First, they collect, normalize, aggregate and store all the log data that might contain useful security signals. Second, they provide analysis and pattern recognition with a strong security context to surface threats for enterprise security teams. We could argue there isn’t much value-add to the first function – the data collection and processing is necessary to enable the second function. Snowflake presumably can perform that function more reliably and cheaply than stand-alone vendors. Cybersecurity partners can then add the real value of threat detection on top of the data in Snowflake, without having to build and host their own data processing and storage infrastructure.
That realization underscores a potential disruption that many of us in the software services industry have taken for granted. It has been a natural assumption that any SaaS vendor should just store their own copy of an enterprise’s data to enable the application functionality that they provide. Snowflake is evolving to make the argument that duplication isn’t necessary in all cases. As Snowflake’s platform capabilities and partnership coverage evolves, we could start to see enterprises go “all in” on Snowflake and shift spend to SaaS vendors that can operate on their data within the Data Cloud.
With that set-up, let’s go through the product announcements in Summit. As you review these, keep the top-level platform strategy in mind. You can see how the new capabilities align with the idea of bringing the work to the data, versus the data to the work.
Unistore
As I eluded to above, Unistore is a new data storage engine for the Snowflake platform that supports transactional workloads. This will enable application developers to connect directly to Snowflake to provide the database source for their data-rich applications. In industry terms, the standard data access pattern for a data warehouse is called OLAP (Online Analytical Processing). Unistore introduces support for the other type of data access pattern called OLTP (Online Transaction Processing). Like other Snowflake data storage engines, Unistore brings governance, strong performance and scale.
As a part of Unistore, Snowflake is introducing Hybrid Tables. These provide fast single-row operations on data that allow customers to build transactional business applications directly on Snowflake. The Unistore storage engine is organized around data rows, which is foundational to a relational, transactional data model. Hybrid tables operate like standard SQL tables. Snowflake requires a primary key for each table, unique for each row, and enforces referential integrity between multiple tables based on defined foreign key relationships. They also support other standard features of transactional tables like indexes and row-level locking. Snowflake plans to continue to evolve Unistore and Hybrid Tables with additional features to enable even more use cases.
Unistore will provide multiple benefits for customers. They can now combine their analytical and transactional data in one data store, eliminating the need to duplicate data and maintain ETL processes in order to power transactional use cases. They can also perform analytics on transactional data as it is being collected and provide those insights back to the application. Customers can join Hybrid Tables with existing Snowflake tables as well, to generate a full view across all data. Unistore and Hybrid Tables enable customers to build transactional applications on top of Snowflake, while maintaining a unified approach to data governance and security.
During Summit, Adobe was mentioned as an early adopter of Unistore, which is currently in private preview. They are applying Hybrid Tables to the Adobe Campaign application, which enables brands to deliver omni-channel experiences to their customers. The tool leverages customer data to create, coordinate, and deliver marketing campaigns through email, mobile, web and offline channels.
Running Adobe Campaign on Snowflake has enabled us to offer unparalleled speed and scale to our customers, who can now leverage our best-in-class cross-channel campaign management functionality with performance that can’t be matched. Our teams already love the improvements we’re seeing, including 50x improvement in delivery preparation time. We look forward to seeing how Unistore will enhance the ability of Adobe Campaign to unlock even more possibilities for our customers to do personalization at scale.
Nick Hall, Senior Director, Adobe Campaign & Managed Cloud Services
Besides Adobe, the Snowflake team shared several other customers who are using Unistore currently in private preview.

The Snowflake team has high expectations for the business impact that Unistore can make. Their SVP of Product posits that it will drive “another wave of innovation”, by enabling customers and partners to build and deploy new applications directly on the Data Cloud.
Native Application Framework
Unistore provides developers with a transactional database to use as the data source for their applications. Snowflake’s second announcement, Native Application Framework, delivers the tools and environment for developers to build, deploy and even monetize data-intensive applications in the Data Cloud.
What is interesting about the Native Application Framework is that it extends the concept of Data Sharing to the actual application runtime. Practically, it means that developers can create applications that run within the customer’s Snowflake environment. As a consequence, the application executes directly on the customer’s data, eliminating the need for it to be copied out to the application developer’s hosting environment, which is a common SaaS pattern. The developer doesn’t even have direct access to the customer’s data, providing an extra layer of security and privacy for customers.

The Native Application Framework supports Snowflake programming functionality like stored procedures, user-defined functions (UDFs) and user-defined table functions (UDTFs). It also extends to the new Streamlit application environment. Like with data, applications benefit from Snowflake’s high availability and disaster recovery, data sharing capabilities and governance.
Additionally, developers can build applications for monetization. These can be listed in the Snowflake Marketplace, made accessible for all Snowflake customers to consider. As an example, Capital One Software, the enterprise B2B software division of Capital One, is using Snowflake’s Native Application Framework to build and deploy their Slingshot application natively in the Data Cloud. Slingshot provides customers with tools to monitor and optimize operational costs of their Snowflake utilization. I discussed this relationship in a prior post.
With Snowflake’s ability to build, distribute, and deploy applications natively in the Data Cloud, we will be able to quickly deliver value to customers. Following the launch of Capital One Slingshot, a data management solution for customers of Snowflake’s Data Cloud, we saw the potential of the Snowflake Native Applications Framework and the increased opportunity to reach more customers to help them optimize the efficiency of their Snowflake usage with the Slingshot app for Snowflake Marketplace.
Salim Syed, VP, Slingshot Engineering for Capital One Software
In addition to Capital One, a number of other customers and partners are using the Native Application Framework. By distributing these applications in the Snowflake Marketplace, customers get faster value by installing new applications with a few clicks and improved security by running the applications directly in their Snowflake instance. During Summit, the SVP of Product discussed demand for the Native Application Framework. He said they currently have more interest in the program than they can handle.

The idea of running applications directly on customers’ data within the Snowflake environment is disruptive to the traditional SaaS model of keeping the customer’s data in the SaaS vendor’s environment. With the Native Application Framework, Snowflake is making the argument and providing the platform to migrate a portion of these SaaS applications onto the Data Cloud to run directly on the customer’s data instance within Snowflake.
With a Marketplace for developers to promote and monetize their applications, this could spawn a whole new breed of SaaS applications. These may resemble existing SaaS categories, but be designed to run directly within Snowflake. That should provide those software vendors with a cost advantage, as they don’t need to charge customers for the overhead of managing their data. Cybersecurity vendors like Securonix and Panther Labs provide examples of this new design pattern.
Programmability
Snowflake announced several new enhancements that improve programmability of applications within the Snowflake environment. These are meant to be consumed by data scientists, data engineers and application developers. The main enhancement revolves around Snowflake’s effort to bring Python support to the forefront, with the launch of Snowpark for Python to public preview. They have also delivered the native integration of the Streamlit application development and hosting environment.

Snowpark for Python makes Python’s rich ecosystem of open-source packages and libraries accessible in the Data Cloud. With a highly secure Python sandbox, Snowpark for Python runs on the same Snowflake compute infrastructure as Snowflake pipelines and applications written in other languages. Snowflake has struck a relationship with Anaconda, which extends access to more Python packages within the Snowpark development environment. This provides Snowpark for Python with the same scalability, elasticity, security and compliance benefits as other Snowflake applications.
When Snowflake first introduced Snowpark for Python, they expected to support maybe 10-20 customers in the private preview. According to the SVP of Product, demand was so great that they opened it up to nearly 200 customers. He claims that there are hundreds more customers in the queue who have been waiting for Snowflake for Python to be opened up to public preview. He was looking forward to seeing the dashboard of new users following the Summit announcement.
Improved Data Access
In addition to the big announcements of Unistore, Native Application Framework and Snowpark for Python, Snowflake introduced a few more enhancements revolving around improving data access.
Streaming Data. Snowflake is improving their support for ingesting streaming data with the private preview of Snowpipe Streaming. This provides better integration between streaming and batch pipelines for processing incoming data. It will be deployed using a serverless model and will add Materialized Tables to support declarative transformations.
Iceberg Tables. To allow customers to access data from external sources, Snowflake announced support for the open industry format Apache Iceberg. Iceberg is a popular open table format for analytics. Iceberg brings high performance, reliability and simplicity of SQL tables to big data. It is compatible with other data processing engines like Spark, Trino, Flink, Presto and Hive.

Besides the Apache Iceberg project, alternatives for an open table format are Delta Lake (from Databricks) and Apache Hudi. The Snowflake team claims that they evaluated all three options and chose the Apache Iceberg project. Iceberg was open-sourced by Netflix is backed by Apple and Amazon.
On Premise Data Access. External Tables for On-Premises Storage was introduced in private preview, to allow customers to access their data in on-premises storage systems like Dell Technologies and Pure Storage. These customers can benefit from the capabilities of the Data Cloud without having to move their data out of these on-premise locations. This is important because some customers cannot store their data on the cloud (due to regulations, sensitivity, etc.). Snowflake wants to support this requirements, by treating the data like it is in the Data Cloud. This further extends Snowflake’s reach into physical data centers maintained by customers.
Competitive Positioning
Snowflake’s broad vision to allow customers to do more with their data in the Data Cloud butts up against the strategies of other providers in the data processing and storage space. I won’t do a detailed feature comparison with all competitive offerings, but can reflect on the positioning with a few other vendor groupings.
Transactional Databases (MySQL, PostgreSQL, MongoDB, MS SQL Server, etc.). One question for investors is what impact this would have on other transactional database providers. MongoDB and some of their new product strategies come to mind. The cloud vendors also have transactional database products for applications (AWS RDS, Aurora, Azure Cosmos DB). I think Snowflake’s Unistore offering will start to encroach on this market, but not capture a large share (at least not initially). The criteria to monitor will be read access times, write concurrency and data access patterns.
For read access times, a transactional database that backs a high traffic software application like a social network or e-commerce site would need to support response times below 1 ms for simple row retrieval on a primary key. This is because anything slower would quickly run out of threads for millions of queries a minute. During Summit, the Snowflake product leadership shared that they are targeting a 10ms response time, not “low microsecond”. While this sounds like a limitation, a lot of low to medium traffic applications would function just fine with 10ms response times and reasonable concurrency.
Second, while read queries can power a lot of workloads, many consumer applications have a heavy write volume as well. Traditional transactional databases are designed to support a high volume of inserts and updates to the data set, in parallel to read traffic. Use cases with high write traffic would be a shopping cart, chat application or IoT data stream. If the database solution is clustered with distributed writes, then it can handle a high volume of inserts and updates concurrently and then propagate consistency across the cluster. Based on the announcement, I don’t think Unistore is going to this level of write traffic, at least not initially.
Finally, the data access pattern for Unistore is relational. This means is wouldn’t be suitable for other common application data workloads like key-value, document-oriented, time series, graph, search, etc. In the case of MongoDB, those data access patterns are supported through the Query API. For development teams that prefer to utilize a non-relational model, Unistore wouldn’t be a fit (again, at least for now).
Modern Data Stacks (Databricks). As Snowflake is usually compared to Databricks, it’s worth seeing how Snowflake’s strategy overlays that of Databricks. As a sidenote, Databricks is holding their Data + AI Summit later in June, so it’s likely they announce several exciting releases as well.
The Databricks Lakehouse Platform combines the best elements of data lakes and data warehouses to deliver the reliability, strong governance and performance of data warehouses with the openness, flexibility and machine learning support of data lakes.
This unified approach simplifies your modern data stack by eliminating the data silos that traditionally separate and complicate data engineering, analytics, BI, data science and machine learning.
Databricks Web site, June 2022
Snowflake and Databricks share a focus on supporting traditional data warehouse and data lake storage and access patterns, with an emphasis on governance, performance and openness. They also both argue for eliminating data silos.

The difference between the two (which appears to be diminishing) is in the use cases for that foundation and the target audiences. For Databricks, use cases primarily revolve around enabling data science and ML workloads, data engineering and analytics. The idea of targeting application developers hasn’t been emphasized yet. They provide a SQL interface to enable standard data warehousing functions on their Lakehouse architecture. That is currently implemented for data visualization partners (Tableau, Looker, Qlik) and ETL vendors (dbt, Fivetran) to use. Whether that gets extended to provide an interface appropriate for application developers remains to be seen. It appears possible, as users can create a SQL endpoint that responds to SQL queries.
The SQL endpoint is implemented as a JDBC/ODBC to Spark connector, so data applications could connect directly to the Databricks platform. It’s not clear whether this would support high query read load with response times in the 10ms realm. The implementation requires that the SQL client is compatible with the Spark interface.
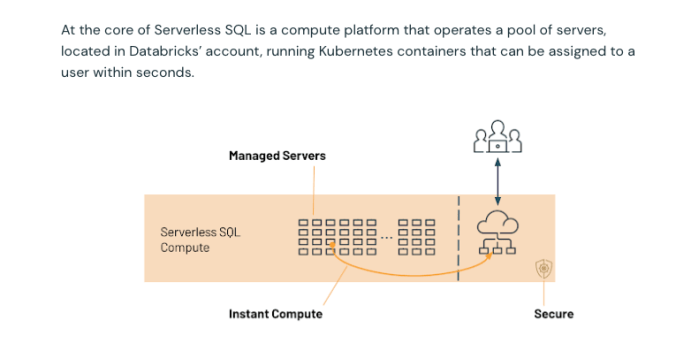
The Databricks Serverless SQL interface runs on a pool of servers that are spun up on demand, advertised as being within 15 seconds. As load increases, more servers are added to the pool (within seconds). This cold start delay might create issues for an always-on application, unless the compute cluster is provisioned at max scale and persists. This deployment model is likely fine for many use cases and winding down resources when not needed would reduce cost.
Snowflake’s focus has expanded to enabling end-user application workloads. They are even going so far as to target specific categories, like promoting Cybersecurity to a top level use case. By introducing their new data engine, Unistore, for transactional data workloads, Snowflake is clearly pursuing application developers as a new audience. Databricks may evolve in this direction as well, or choose to continue to build out their capabilities for data scientists, data engineers and business analysts. While pundits will argue finer technology points, I think both platforms have strengths, depending on the application, sophistication of the customer and user segment targeted.
Investor Take-aways
Snowflake’s strategy of enabling application development directly on the Data Cloud platform opens the aperture of use cases they can address. Bringing applications closer to the data has advantages for customers and is potentially disruptive for traditional software-as-a-service vendors. This architectural design pattern eliminates the need for application vendors to maintain a separate application hosting and data storage environment. It reduces copies of the customer’s data, along with the inherent disadvantages of cost, overhead of synchronization and security risks.

This idea of a shift of SaaS applications to operate directly on the Snowflake Data Cloud could represent a real paradigm shift for the industry. We have taken for granted the idea that a SaaS provider should maintain their own database infrastructure to deliver their software applications to customers. Snowflake is raising the question whether that separate data storage layer is necessary in all cases. I can see a number of cases where it is not, or at least not differentiated enough to justify the additional expense of maintaining a copy of a customer’s data outside of Snowflake.
How this strategy plays out remains to be seen. Snowflake is gaining some initial traction with the Cybersecurity vendors like Securonix, where there is a compelling value proposition. I agree with Snowflake leadership that this new model of software distribution should become a meaningful revenue driver for Snowflake. During the Investor session, leadership shared that 9% of $1M+ Snowflake customers are part of the Powered By program. I suspect this will increase as more developers choose to build and monetize applications in the Snowflake Marketplace.
Additionally, as Snowflake seeks to keep expanding spend with their largest enterprise customers, displacing duplicate data storage from SaaS providers should help offset the incremental cost of Snowflake. If Snowflake’s vision is fully realized, they could evolve into a full featured application development and data storage platform that sits on top of the hyperscalers. Industry analysts have dubbed this concept as a “supercloud“. Perhaps a little early, but we can see the capabilities lining up. If anything, the product announcements at Summit should drive another leg of growth for Snowflake.
NOTE: This article does not represent investment advice and is solely the author’s opinion for managing his own investment portfolio. Readers are expected to perform their own due diligence before making investment decisions. Please see the Disclaimer for more detail.


Hi Peter, great content as always.
I noticed that a few companies emerged to help users get better visibility into their usage on Snowflake and reduce costs, including Slingshot (which you have mentioned) and Bluesky Data (https://www.getbluesky.io/). From what they have described, companies can easily reduce their Snowflake bills by 10%-20%. During an economic downturn (like right now), this looks like a hint to me that Snowflake’s growth will slow down considerably in the coming quarters.
On the other hand, Snowflake seems pretty open-minded around this. The senior leadership thinks cost optimization makes their customers happier and will bring in more business. Indeed, cost reductions can reduce churns. In this aspect, I’m pretty satisfied with Snowflake leadership’s mindset: putting customers first.
Would love to hear your take on this.
I agree with your take overall. At Snowflake Summit, leadership presented several examples of companies that increased their spend after optimization. The best example was Western Union. They went through a formal optimization that the Snowflake sales support team initiated. Indeed, their spend dropped after the the optimization review, but several months later was up 15% over the prior spend. This is because they were able to find more business cases to apply Snowflake towards.
In a tighter spending environment, Snowflake spend will certainly take a hit, but I think it will represent a one-time optimization (like the Western Union example). From there, it should return to a normal expansion cadence.
i’d also factor in that many of these companies have committed levels of annual spend. as they contain costs, they are sure to reuse that committed spend by bringing new workloads. mgmt has spoken about this when they did the recent optimization changes, plus is very open about helping custs optimize their queries. they want happy customers, not to nickel and dime like an Oracle, which all helps grealty allay fears about vendor lock-in.
Thanks for the article. About:
“These customers can benefit from the capabilities of the Data Cloud without having to move their data out of these on-premise locations.”
when Snowflake brings out a new product, is there always going to be some extra work that Snowflake needs to do to get it to work on-premise? If so, is it possible to give a ballpark estimate of the cost, per dollar of the cloud-only R&D cost, like is it closer to $0, $0.10, $1, or $10?
Peter, if I may borrow a word, the cadence of your recent output has been impressive (and welcome). This torrent of entries has continued the clear and authoritative writing which makes your blog unique. I’ve happily followed you to Commonstock and will just as happily contribute to the “tip jar” whenever you set it out.
Here’s my question. I’ve heard of concentrated portfolios before, and I follow along with the folks on Saul’s board who number their stocks in the high single digits; but I’ve NEVER heard of a portfolio boiled down to four stocks. It’s bold, to say the least. Surely, there are other quality companies you could invest in that would allow you to mitigate the risk of an individual company stumbling? Crowdstrike comes to mind, as you referenced it a couple of times in your latest Commonstock post on Datadog. I’d love to hear your thinking on the balance of risks and rewards in your approach to portfolio management.
Thank you, as always,
Erik
Hi Erik – thanks for the feedback. I appreciate it. My portfolio is currently concentrated as a consequence of moving out of positions that I have lost confidence in and not finding new companies yet that I like enough to open new positions. I am watching Crowdstrike closely to see if they can maintain their growth. I still have a concern about a large pull forward in security spend. I prefer to invest in companies that offer other services besides security. I may also look into GitLab further.
Thank you so much Peter for another very informative article!!!
In case you attended/listened to Databrick’s investor day, would be really interested to have your take on how Databrick’s competitive position has evolved compared to Snowflake and whether you think this is gonna be a winners takes most/all market.
Sure – thanks for the feedback. I do plan to publish a summary of Databricks’ Data+AI Summit announcements. For now, I think the market will be big enough to accommodate both Snowflake and Databricks. They are still appealing to separate use cases and user audiences for the most part. A good signal for this is customer penetration. Several large enterprises highlighted during their respective conferences showed up in both (Adobe for example).
I’m a bit late with this, but I noticed something interesting about JP Morgan’s upgrade of SNOW on June 23. It’s at least partly based on a survey of Snowflake’s customers. CIO’s were asked to name software companies in the mid-size or smaller range that showed impressive vision, and Snowflake led in that. Snowflake was getting strong spending intent, and was top for spending intent from existing customers (it’s not clear if that was from surveying the same CIOs). The JP Morgan analyst said Snowflake “surged to elite territory” in the survey. To see what I boiled that down from, google “snowflake jpmorgan upgrade” and use the marketwatch link.